
Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
编辑论文链接:2403.12570v1.pdf
今天要分享的是来自CVPR 2024的一篇异常检测的文章,从标题我们也能知道这篇文章主要针对的是异常检测中医学图像检测这个方向的,用的是经过修改的视觉语言大模型来实现通用的异常检测。
背景

首先讲一下方法提出的背景。
大规模视觉语言预训练模型在自然图像处理领域的异常检测取得了重大进展,但受限于医学图像与自然图像之间的巨大差别,这种差别可能体现在图像的特征、数据分布以及所需的标签信息等方面,传统大规模视觉语言预训练模型如CLIP无法直接应用于医学图像异常检测。
医学图像在模态和解剖区域方面的巨大差异性需要一个通用模型。
当代大规模预训练视觉语言模型(VLMs)最近为稳健且可推广的异常检测奠定了基础。稳健的模型能够有效识别出异常样本,即使这些样本在特征上与训练数据有显著不同。这意味着模型不仅能处理标准情况,还能应对意外情况,减少误报和漏报。可推广的模型能够在不同的数据集或应用场景中有效工作。这对于异常检测尤为重要,因为实际应用中的数据分布可能与训练数据有所不同。一个可推广的模型可以在多种环境中应用,而不需要进行大量的重新训练。
动机

基于以上背景,文章提出为医学图像开发一种能够适应之前看不见的模态和解剖区域通用的可推广AD模型,也就是这里的基于CLIP Model的Multi-level Adaptation and Comparison Framework
文章中采用CLIP这种VLMs作为基础并进行医学异常检测方向的定制修改。
但定制这样的CLIP模型存在以下挑战:
CLIP从捕获图像语义到识别不同语义上下文中的不规则性的重大转变。
CLIP从自然图像处理领域到医学影像过渡的重大领域转变。
在训练阶段将CLIP模型应用于未遇到过的成像模式和解剖区域非常困难。
接下来的方法部分就将着重解决这些挑战。
方法
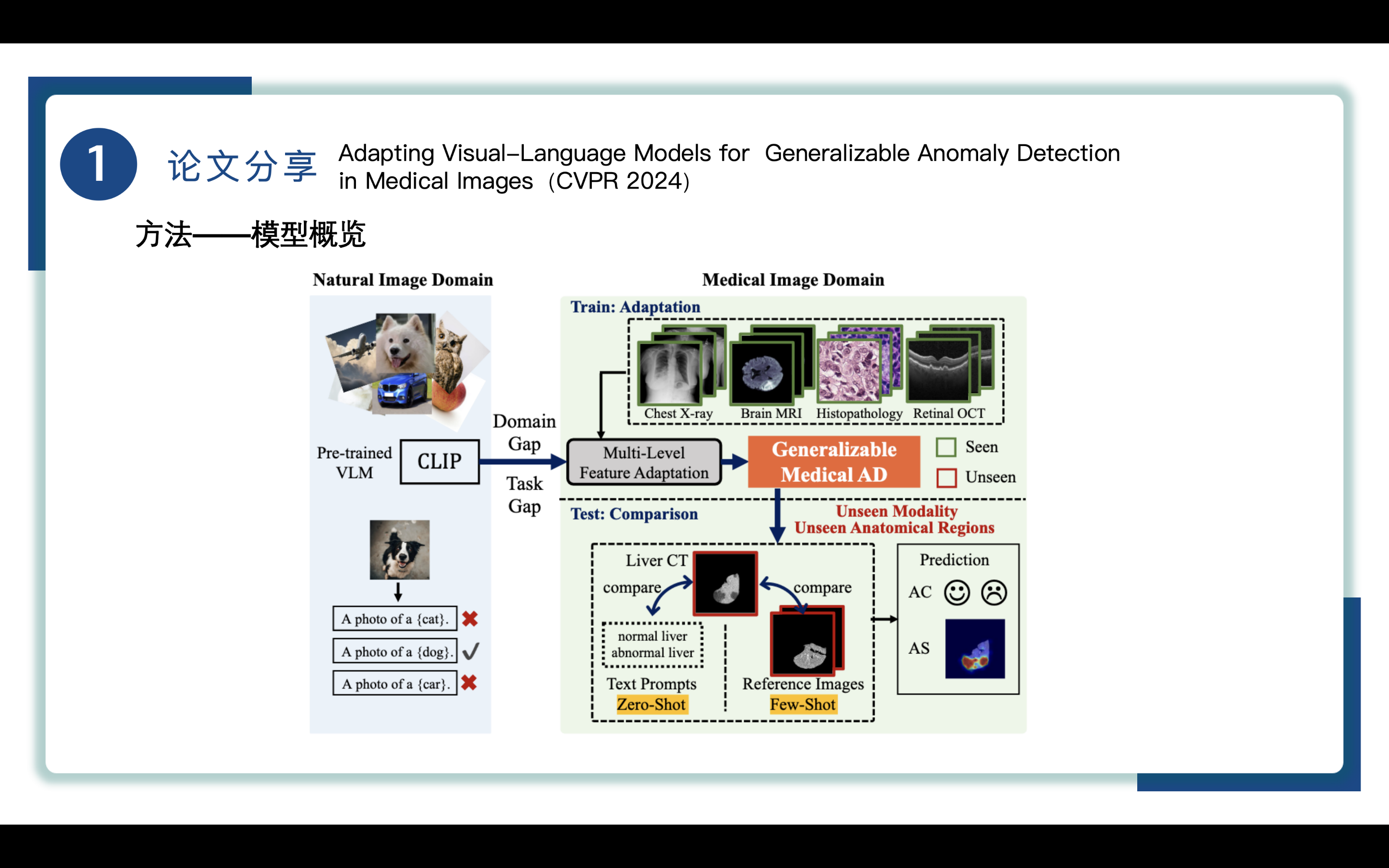
来到方法部分,先来看一下模型概览。给出了自然图像领域(Natural Image Domain) 和 医学图像领域(Medical Image Domain),自然图像领域(Natural Image Domain)的CLIP模型通过视觉编码器和文本编码器进行匹配,狗照片匹配到的就是 A photo of dog。
医学图像领域(Medical Image Domain)的分为训练适应和测试对比两个部分,domain adaptation来通过MLFA训练得到基于CLIP的Generalizable Medical AD模型,将其应用于之前看不见未遇到过的模态和解剖区域。测试则通过zero-shot分支的text prompt和few-shot的reference image进行比较,最终得到AC和AS的预测结果。
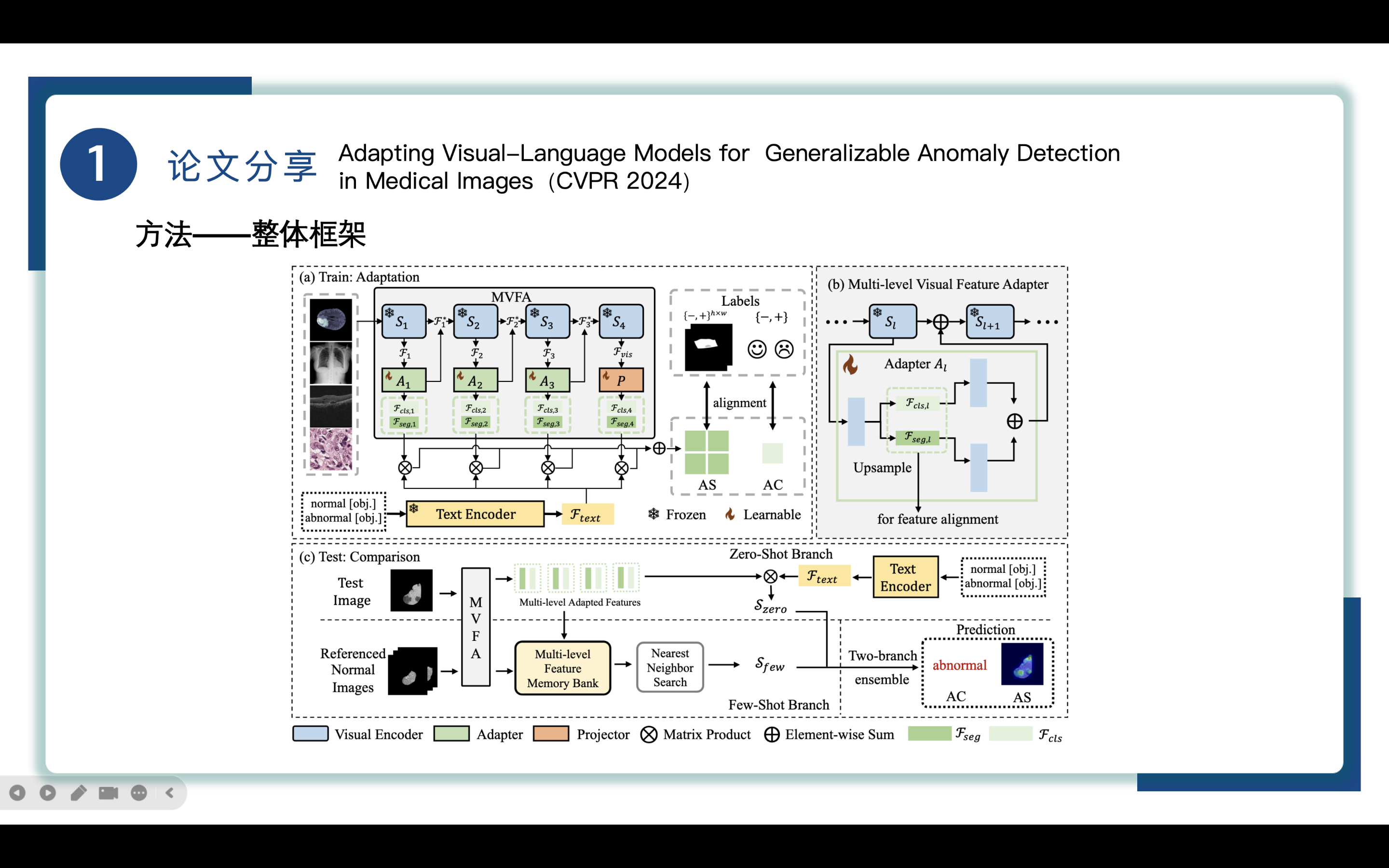
再来看一下整体框架,这张图上给出了整体的执行流程,也就是刚才我们讲的Medical Image Domain部分的细化。接下来我们对两个阶段的内部进行进一步地分析。
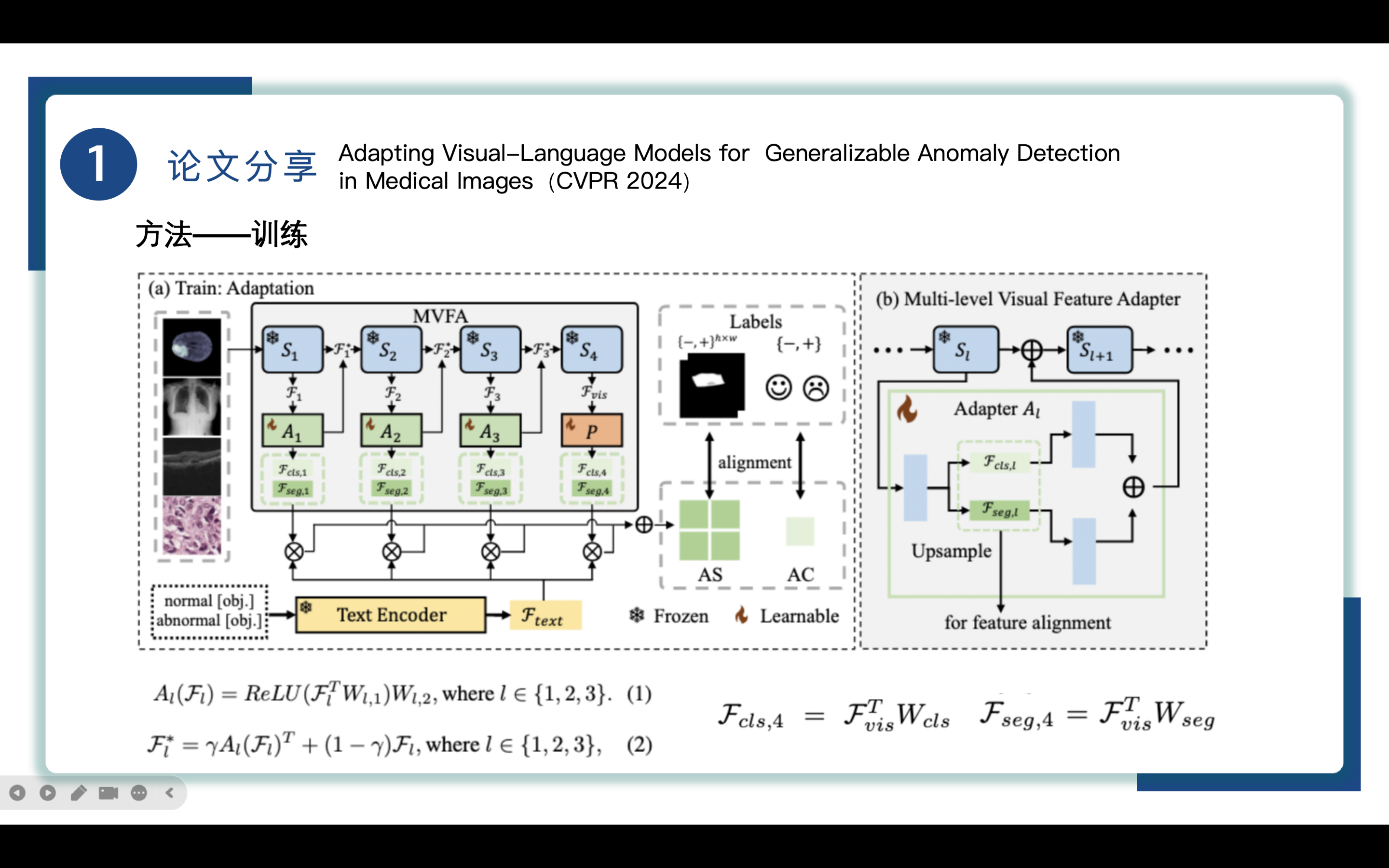
为了使预训练的自然图像视觉语言模型适应医学成像中的异常检测(AD),引入了一个专门为医学图像中的异常检测设计的多层次特征适应框架,也就是图中MVFA部分,利用最少的数据和轻量级的多层次特征适配器。
①MVFA:Multi-level Visual Feature Adapter
在多个特征级别上应用CLIP适配器,也就是图片中的visual encoder。对于图像x∈Rh×w×3, CLIP视觉编码器通过四个连续阶段(S1到S4)将图像x转换为特征空间Fvis。前三个视觉编码器阶段(S1到S3)的输出,记为Fl, l∈{1,2,3},表示三个中间阶段的特征。并冻结了主干网。
visual feature adaptation视觉特征自适应涉及三个不同层次的特征适配器,l∈{1,2,3}和一个特征投影仪P(·)。在每一层l∈{1,2,3},一个可学习的特征适配器被集成到特征中,如公式(1)所示,包含两层(最小数量)的线性变换。W是可学习的参数。最后一层使用投影器而不是适配器的原因是投影器将最终的视觉特征从其原始空间映射到与文本特征相匹配的空间,这有助于在特征比较阶段实现更准确的对齐,在多级特征适配之后,投影器有助于整合不同层次上学习到的特征,生成一个综合的特征表示,这个表示可以更好地捕捉到异常的全局和局部特性。
公式(2)给出了的计算公式,其中γ是超参数一般设置为0.1,Fl*将作为下一编码器级Sl+1的输入。
(b)MVFA
如右图(b)所示,为了同时处理AC和AS的全局和局部特征,双适配器架构取代了公式(1)中使用的单适配器,在每个级别产生两个并行的特征集Fcls, 1和Fseg, 1。对于CLIP视觉编码器生成的最终视觉特征Fvis,特征投影仪P(·)使用参数为Wcls和Wseg的线性层对最终视觉特征Fvis进行投影,得到全局和局部特征Fcls,4和Fseg,4。
为了从高层次的紧凑特征中恢复空间分辨率,MVFA使用上采样步骤,以便生成与原始图像相同分辨率的异常分割图,用于后续对比。
该模型利用多层自适应特征,通过之后的视觉语言特征对齐,可以有效地识别全局异常进行分类,也可以有效地识别局部异常进行分割。
②语言特性格式Language Feature Formatting
如左下部分所示,采用了一种两层的文本提示方法,正常和不正常的,通过分别计算文本编码器text encoder对正常状态和异常状态提取的文本特征的平均值,我们得到一个文本特征,表示为Ftext,Ftext后续将被用于与每阶段的视觉特征进行运算。
③视觉语言特征对齐Visua-Language Feature Alignment
将MVFA给出的自适应视觉特征与文本特征对齐,在特征对齐阶段,视觉特征和文本特征通过点积或其他相似性度量方法进行比较,在每个特征层l∈{1,2,3,4}上对模型使用损失函数进行优化,以确保它们在语义上是一致的。

具体的损失函数如公式(3)所示,其中Fseg代表局部特征,Ftext代表文本特征,Fcls代表全局特征,S代表对应的长为h宽为w的像素级异常图, c代表图像级异常注释。
每个特征层的损失由Dice损失、Focal损失和二进制交叉熵BCE损失构成,Dice损失、Focal损失主要关注局部异常分割,而二进制交叉熵BCE损失关注全局异常分类,三个默认权重均为1.0,整体适应损失为四层损失相加。
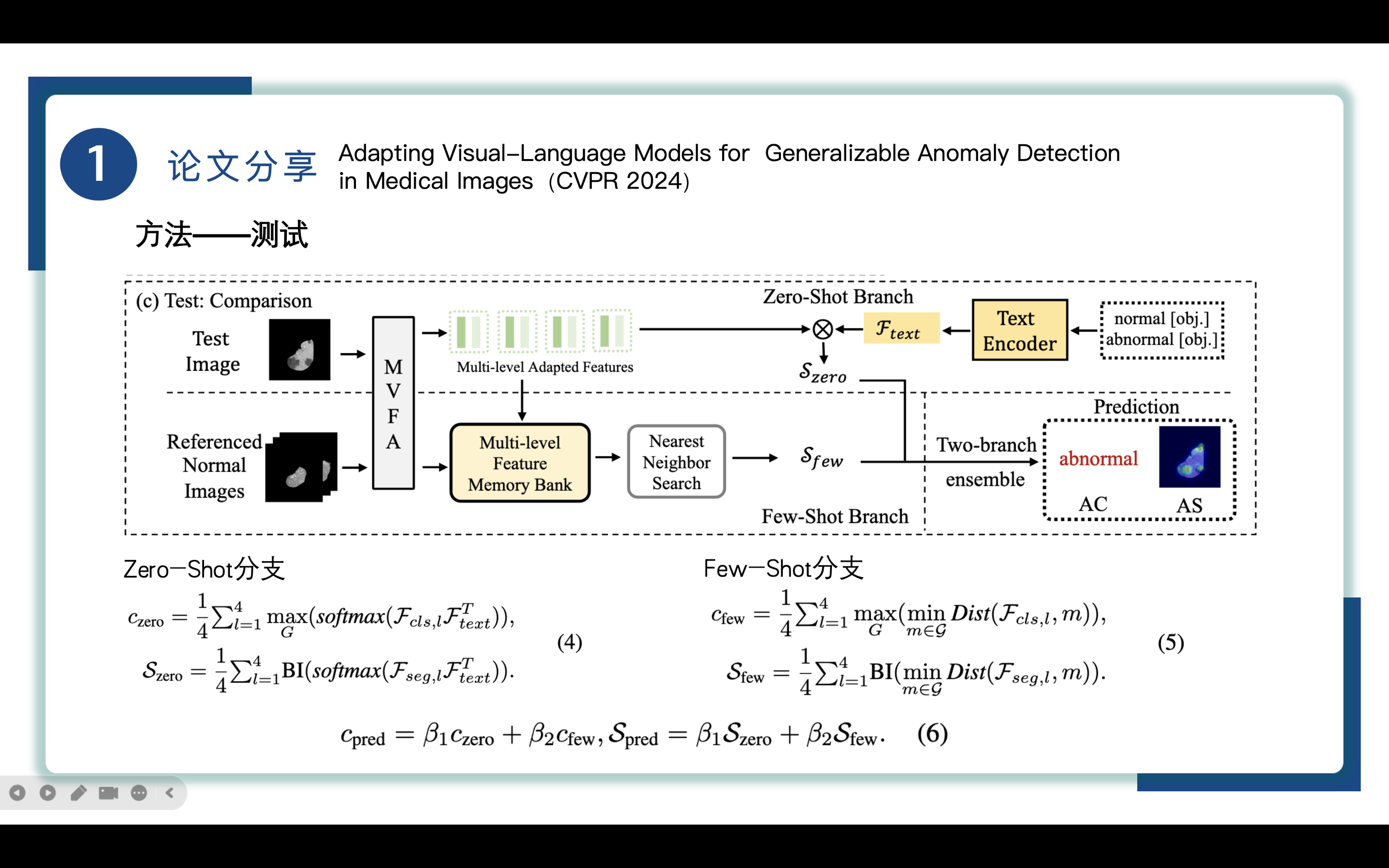
来到测试阶段,为了准确地预测图像级(AC)和像素级(AS)的异常,我们的方法采用了两分支多级特征比较架构,有zero-shot和few-shot两个分支。
在这里先对zero-shot和few-shot进行一个简单介绍,"zero-shot"和"few-shot"学习是两种不同的学习范式,它们处理的是模型在面对未见过的任务或类别时的泛化能力。
Zero-shot Learning (零样本学习)指的是模型在没有任何特定于任务的训练数据的情况下进行学习。换句话说,模型在没有见过某些类别的任何示例的情况下,就能够识别或作用于这些类别。零样本学习的一个关键挑战是,模型需要能够理解新类别的描述,并将其与已有的知识结合起来,以做出正确的预测。
而Few-shot Learning (少样本学习)是指模型在只有很少的样本可供学习新任务或新类别时进行学习。这通常意味着模型在训练时对于新任务只有少量的示例。这适用于实际应用中常见的情况,即某些医学图像模态或解剖区域的标注数据难以获得,但可以获取到少量的标注样本,与零样本学习相比,少样本学习提供了一些特定于任务的数据,但数量远少于传统监督学习所需的数据量。
同时使用零样本(zero-shot)和少样本(few-shot)两个分支的原因是为了提高模型在不同训练数据条件下的泛化能力和灵活性,医学图像具有高度的多样性,包括不同的成像模态和解剖区域。这两个分支使得模型能够同时处理多种类型的医学图像,提高检测的准确性和可靠性。
①Zero-Shot分支
通过MVFA对test image测试图像X_{test}进行处理,产生多级自适应特征,然后将这些特征与通过Text Encoder得到的文本特征F_{text}使用公式(4)进行计算,其中BI(·)将异常图重塑,得到零样本AC和AS结果,记为C_{zero}和S_{zero}。
①Few-Shot分支
参考正常图片,少量标记的正常图像的所有多层次视觉特征都有助于构建一个多层次特征记忆库multi-level feature memory bank记为G。然后通过最近邻搜索过程,从每一层的测试特征与记忆库特征之间的最小距离中得到少量的AC和AS分数,使用公式(5)进行计算,其中Dist(·,·)函数表示余弦距离,得到计算结果记为Cfew和Sfew。
③few-shot分支和zero-shot结合
最终预测的AC和AS结果结合了两个分支的结果,使用公式(6)进行计算。
其中β1和β2分别为零样本和少样本的权重因子,默认为0.5。
实验

来到实验部分,实验使用了来自五个不同医学领域生成的六个数据集。
分别是脑MRI、肝脏CT、视网膜OCT、胸部x线检查和数字组织病理学检查。其中,BrainMRI、LiverCT和RESC数据集用于异常分类(AC)和异常分割(AS),而OCT17、ChestXray和HIS仅用于异常分类(AC)。
通过接收机工作特性曲线(AUROC)下的面积用于量化性能。该指标是AD评估中的一个标准,单独考虑AC中的图像级AUC和AS中的像素级AUC。
实验使用ViT-L/14的CLIP,输入图像分辨率为240。模型共24层,分为4个阶段,每个阶段包含6层。使用Adam优化器,在一个NVIDIA GeForce RTX 3090 GPU上,以恒定的学习率为1e-3,批处理大小为16,进行50次epoch的训练。
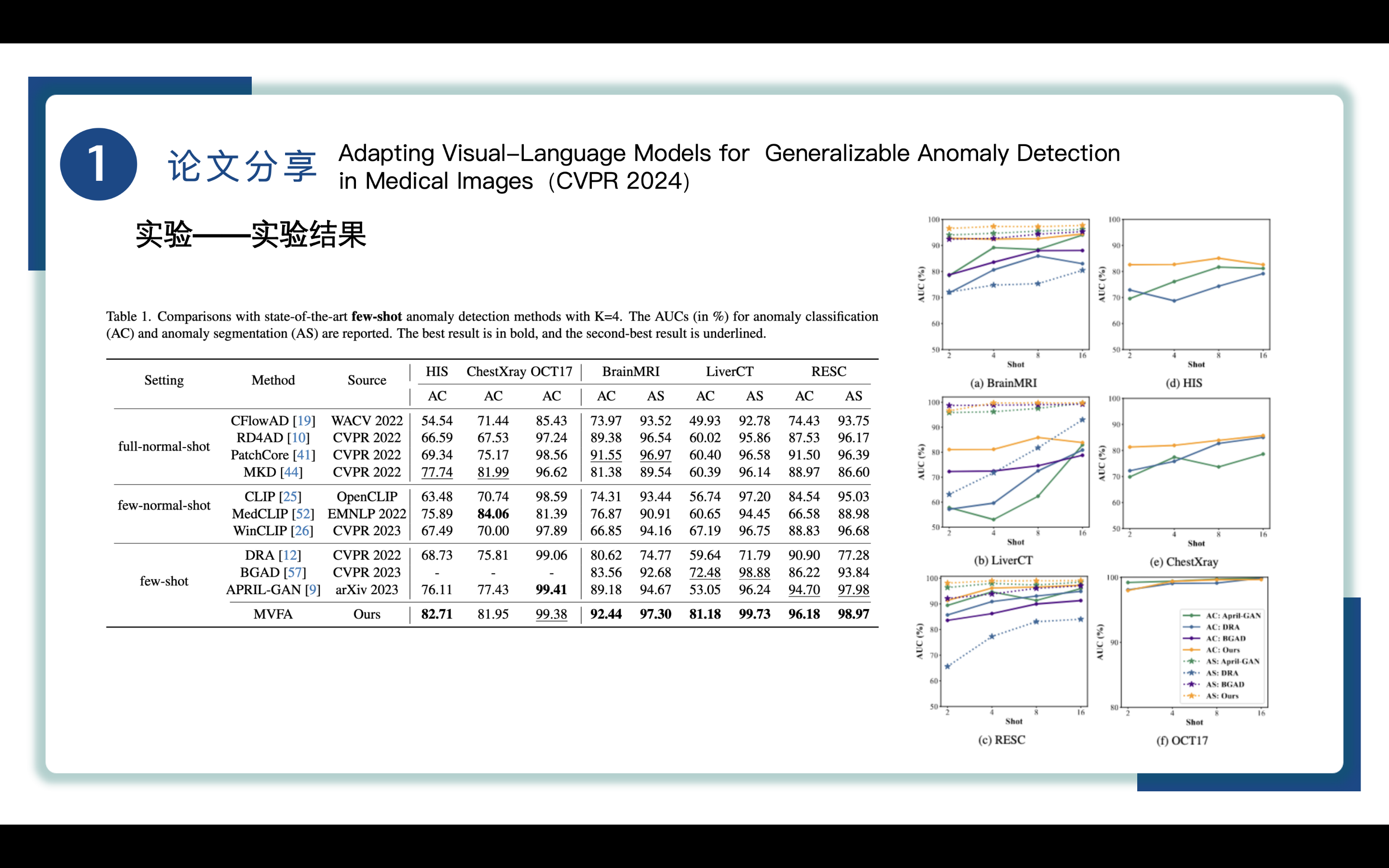
Table1展示了 few-shot模式下MVFA方法与其他主流方法在六个数据集上AC和AS的AUC数据,粗体数据为最好,下划线数据为次好,通过表一和右侧折线图(两条黄线分别代表MVFA的AC、AS)我们能清楚看到MVFA表现出极好的性能,在few-normal-shot设定下比基于CLIP的CLIP、WinCLIP方法表现更加出色,本文的MVFA也是基于CLIP定制的,相较于其余基于CLIP的方法来说,MVFA 的优势在于它能够有效利用一些abnormal samples,以此达到更好的性能。
还要解释一下MedCLIP在ChestXray上的最佳表现,因为MedCLIP是在与实验数据集大规模重叠的 ChestXray 数据上进行训练的,但它缺乏广泛的泛化能力,这从它在其他数据集上的性能中可以看出。
除此之外,MVFA比full-normal-shot的AD方法更佳,full-normal-shot这类AD方法需要依赖于大量数据集。而MVFA在few-shot上表现极佳,说明将一些异常样本作为监督是很有用的,尤其是在仅能获取有限数量的异常数据的医学诊断中可能更实用。
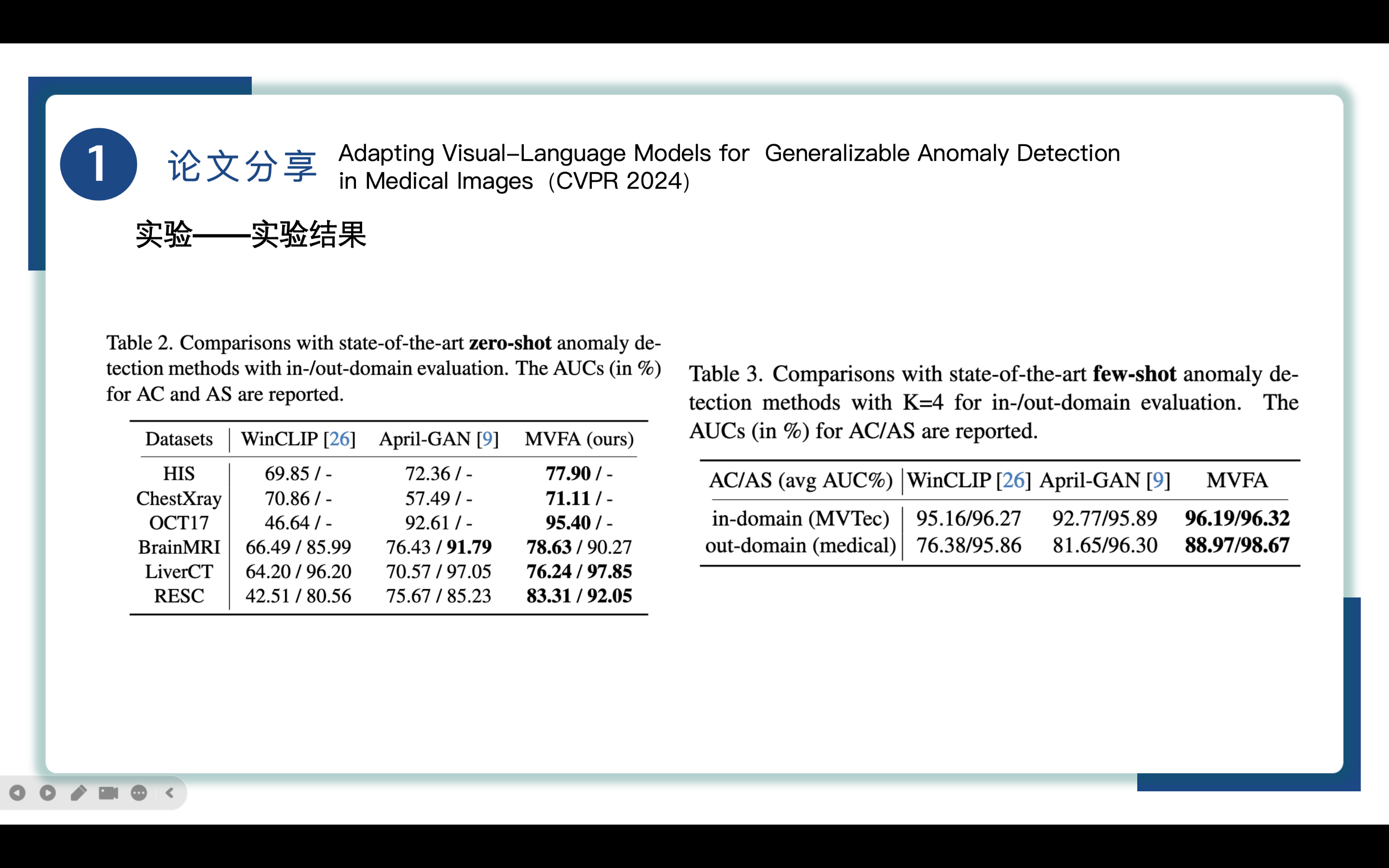
Table2展示了 zero-shot模式下MVFA方法与其他两大主流方法在六个数据集上AC和AS的AUC数据,可以看到MVFA也表现出极好的性能。
在异常检测中,假设数据集A,B,利用A训练一个模型,然后利用A,B分别作为输入去做测试,此时A就是域内数据in-domain,B叫out-domain
Table3展示了in/out domain的实验结果,其中MVTec是工业缺陷检测数据集,被认为是域内评估,即便本文的MVFA方法主要关注点不是域内场景,MVFA仍然拥有出色的性能.
在我们主要关注的域外评估中,MVFA 明显优于竞争方法,凸显了其卓越的泛化能力。
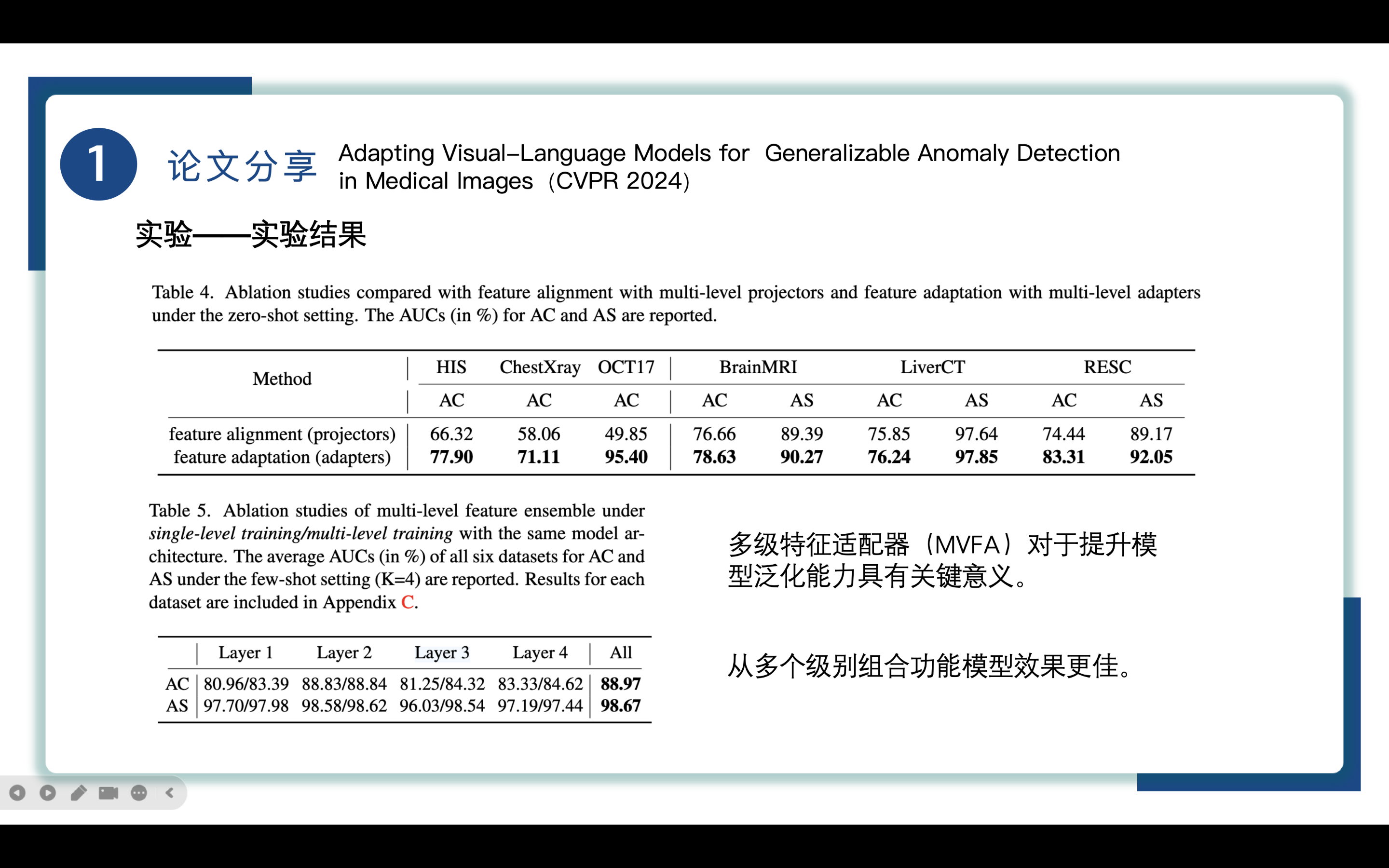
随后作者在zero-shot设定下进行了消融实验,以此评估多级特征适配器(MVFA)在增强跨模态泛化方面的有效性。
在不同层上使用multi-level feature projectors代替multi-level feature adapters,保持参数和损失函数不变。唯一的不同就是每层的projectors都是独立优化的,而adapters是统一优化的。
实验结果如表4,feature adapters 方法优于feature projectors方法,揭示了多级特征适配器(MVFA)在提升模型的泛化能力中的关键作用。
接着评估了集成来自不同层的特征的集成方法的有效性,如表5所示,表5的结果表明在四层中第二层拥有最好的性能。但是集成所有层特征的集成方法的性能优于单层方法,在 AC 中记录了 88.97% 的 AUC,在 AS 中记录了 98.67% 的 AUC。这强调了从多个级别组合功能的有效性。多级训练的性能始终超过单层训练,这表明了在所有层的多级适应方法的突出优势。

接着作者进行了一些更加直观的可视化分析。
如图 4 是来自各个层的视网膜异常分割的可视化结果。结果表明通过协同整合来自不同层的特征 AD 有显著的改进。
为了知道多级特征适应方法(MVFA)是如何提高异常分割性能,文章给出了来自 BrainMRI、LiverCT 和 RESC 数据集的几个病例的可视化结果,如图5所示,MVFA(列 e)生成的分割比最先进的方法 April-GAN(列 c)产生的分割更接近真实值(列 f)。这说明了所提出的多层次视觉特征适应的有效性。

此外文章给出了可视化的 RESC 中学到的特征,如图 6 所示。每个点对应于测试集中正常或异常样本的特征。可以看到适配器adapter增强了属于不同状态的sample之间的隔离程度,这有利于识别 AD 决策边界。
总结

最后做个总结:
本文将自然域预训练的视觉语言模型应用于医学AD,具有不同形态和解剖区域之间的跨域泛化性。自适应不仅包括从自然域到医学域的自适应,还包括从高级语义到像素级分割的自适应。
为了实现这一目标,本文引入了一种协作的多层次特征自适应方法,其中每次自适应都由相应的视觉语言对齐指导,便于从医学图像中分割各种形式的异常。结合基于比较的AD策略,该方法能够灵活地适应具有大量模态和分布差异的数据集。
该方法在零/少样本AC和AS任务上优于现有方法,为未来的探索指明了有前途的研究途径
参考资料
- 1
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享