
Long-Tailed Anomaly Detection with Learnable Class Names
编辑论文链接:https://ieeexplore.ieee.org/document/10655523
长尾数据集分割链接:https://zenodo.org/records/10854201
这篇论文发表在CVPR 2024上
背景
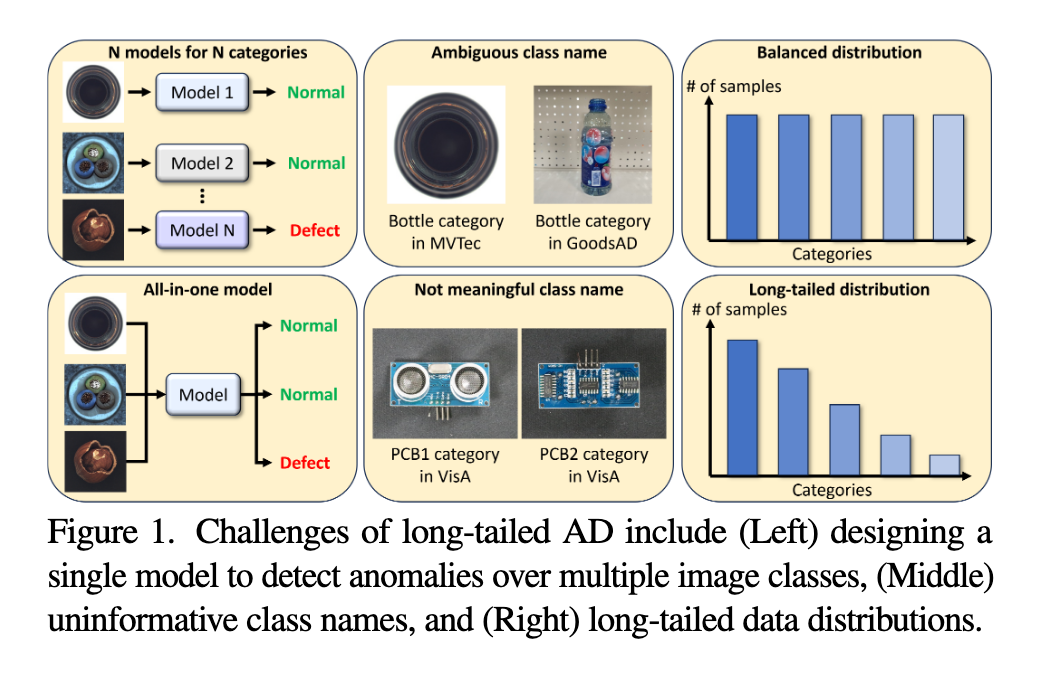
异常检测(AD)在工业制造等领域非常重要,旨在识别有缺陷的图像及其缺陷位置。传统方法在多个图像类别上扩展性较差,并且需要手动定义类别名称,难以应对长尾数据分布。
长尾数据分布是实际工业应用中常见的现象,其中部分类别数据样本显著少于其他类别。
动机
提高异常检测模型的扩展性,使其在无需依赖类别名称的情况下处理多类别的长尾分布数据。
解决现有方法中对类别名称依赖过强及在数据不平衡情况下性能退化的问题。
基于重构和语义的异常检测模块的LTAD(Long-Tailed Anomaly Detection)
重构模块 使用基于 Transformer 的重构网络,将图像投影到正常图像的流形上,通过重构误差计算异常分数。
语义模块 利用预训练的 ALIGN 模型,将异常检测任务转化为二分类问题,基于学习的伪类别名称构建分类器。
方法
Framework
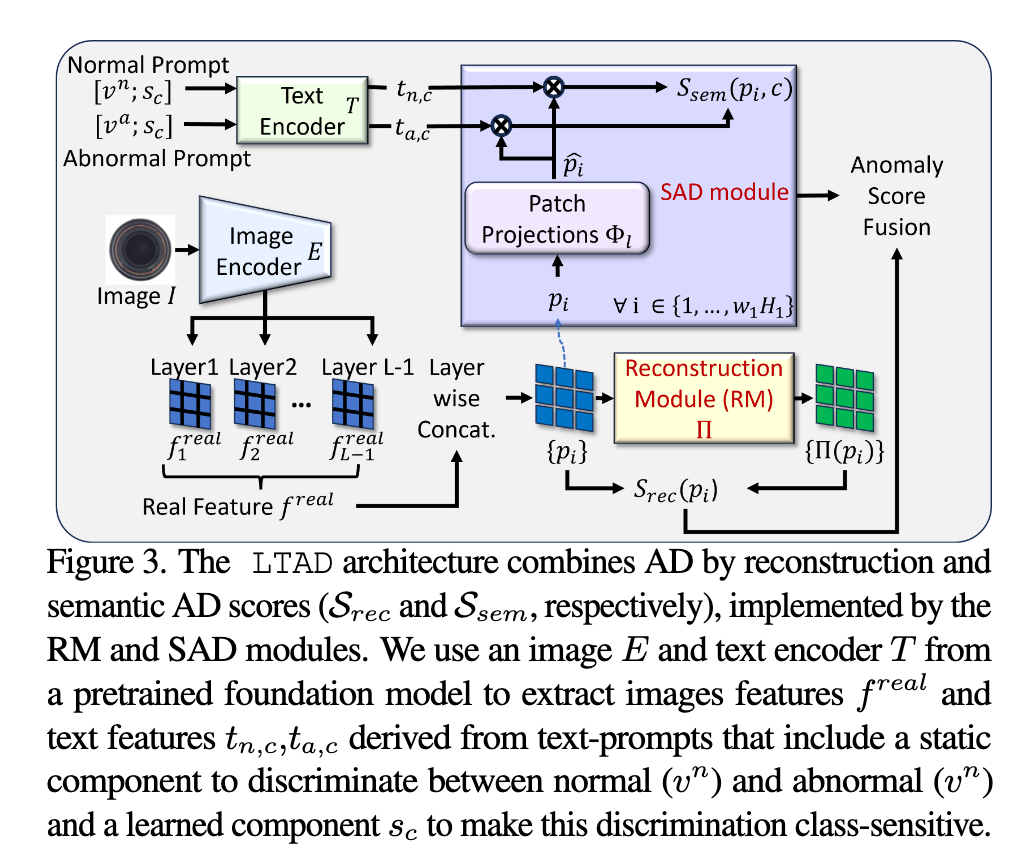
AD by reconstruction
RM (Π)是一个通过L层的预训练编码器E来重建从图像I中提取的特征的Transformer。
给定一张属于类别C的image
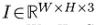
E提取1到L层的特征张量
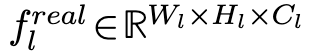
由于最后一层L的特征代表全局的语义信息,可能会影响异常检测的性能,需要局部语义,因此将其丢弃并将L-1层的特征沿空间维度的双线性插值重新映射到$f^{real}_1$的维度。
随后定义
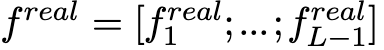
为提取到的共L-1层的feature tensor。
随后被分割为W1*H1的patches
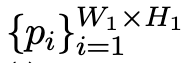
这些patches作为Reconstruction Module(RM)的输入。 对于给定的patch i,重建AD的异常分数为
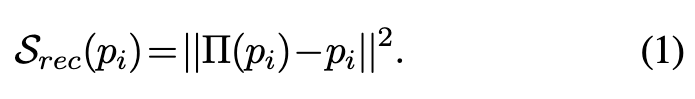
Semantic AD (SAD)
SAD的两个目标是:
给出异常检测器对正常/异常类的敏感度
利用大型基础模型中关于正常/异常的先验知识。
这允许AD在不需要异常图像进行训练的情况下区分两种情况。
语义AD模块是patch pi的投影pi hat到正常/异常类的二值分类器。每一个投影器Φl都是由线性层实现的
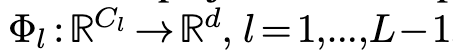
其中d是text embedding的维度。
层级的特征通过max pooling layers被聚合为单个patch上的特征
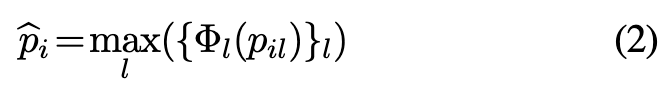
结果向量pi hat随后作为输入送到参数为tn,c (normal) 和ta,c (abnormal)的二元分类器,二元分类器计算异常的后验概率
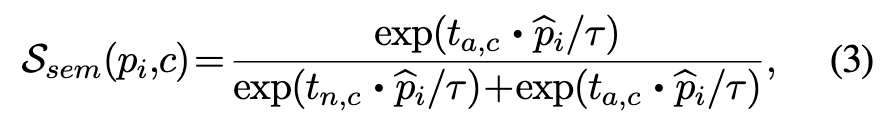
其中“•”表示点积,Ssem为类别C的图像的语义AD分数。 属于类别C的图像的patch feature pi的anomaly score为
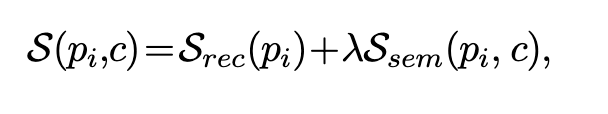
因为没有异常的训练图像,分类器参数tn,c, ta,c没有明确的监督学习。通过向ALIGN模型提供适用于所有类的正常文本提示符vn和异常文本提示符va来利用ALIGN模型提供的正常/异常分类的先验。通过设置vn =“a”和va =“a broken”可以实现最佳AD性能。为了进一步使异常分数对图像语义敏感,使用每个类c学习到的伪类名sc。生成的语义敏感AD提示符P = {[vn;sc]、[va;sc]}c通过ALIGN模型的文本编码器T映射到一组分类器参数{(tn,c, ta,c)}c。
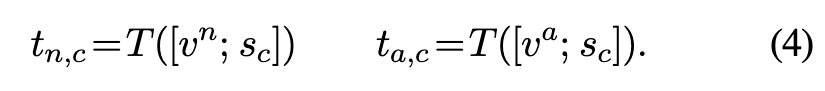
Training
Phase 1: Class sensitive data augmentation
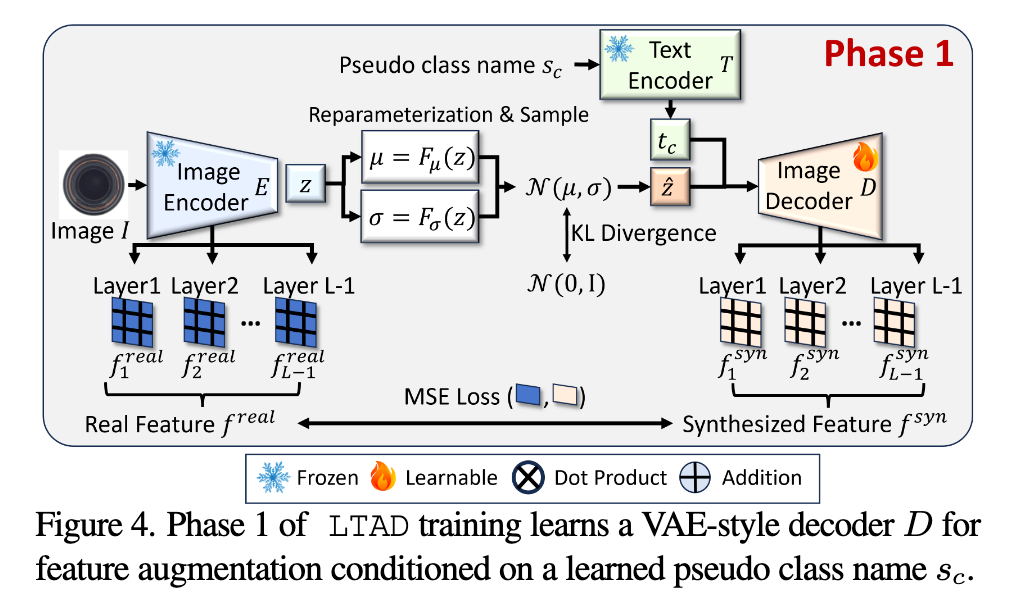
给定一张属于类别C的image
预训练的编码器E提取特征张量
加上潜在码
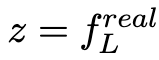
,训练图像解码器D对相应的特征向量进行采样,其结构是E的镜像副本。潜在特征z hat从参数μ = Fμ(z)和σ =Fσ(z)的正态分布N(μ, σ)中采样,其中Fμ和Fσ是学习的线性变换。然后解码器D从z hat合成一个特征张量。
D是由关于类的先验知识决定的,以文本衍生的原型特征向量tc的形式,表示用于特征合成的类c,tc = T (sc)。然后将特征原型与图像相关的潜在特征z hat连接起来作为D的输入,D最终合成特征张量
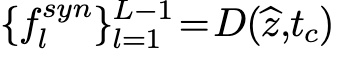
使用以下损失函数进行优化
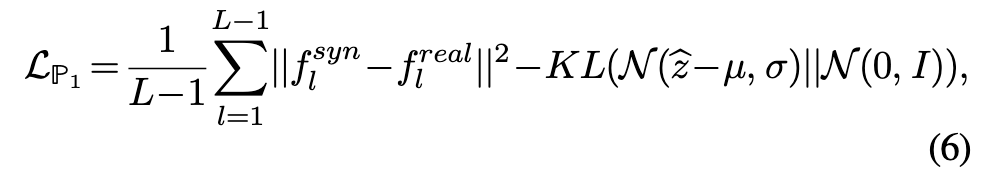
其中的Kullback-Leibler散度(KL)正则化约束以鼓励正态分布。
Data augmentation
Long-tailed classes: 为了抵消长尾数据集的不平衡性,通过选择概率分别为(pc, 1−pc)的$f^{𝑟𝑒𝑎𝑙}$或合成 $f^{𝑠𝑦𝑛}$特征向量来实现数据增强。选择的特征向量f被分割成W1×H1补丁特征向量
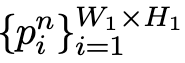
,其中上标n表示这些是正常特征。
Anomalies:
为了抵消训练过程中异常的缺失,将随机噪声(从正态分布中采样)添加到正态补丁特征p_i^n 中,产生伪异常补丁特征p_i^a 。在训练期间,对所有normal patches重复此过程。在推理过程中不添加随机噪声。
Phase 2: Anomaly detection
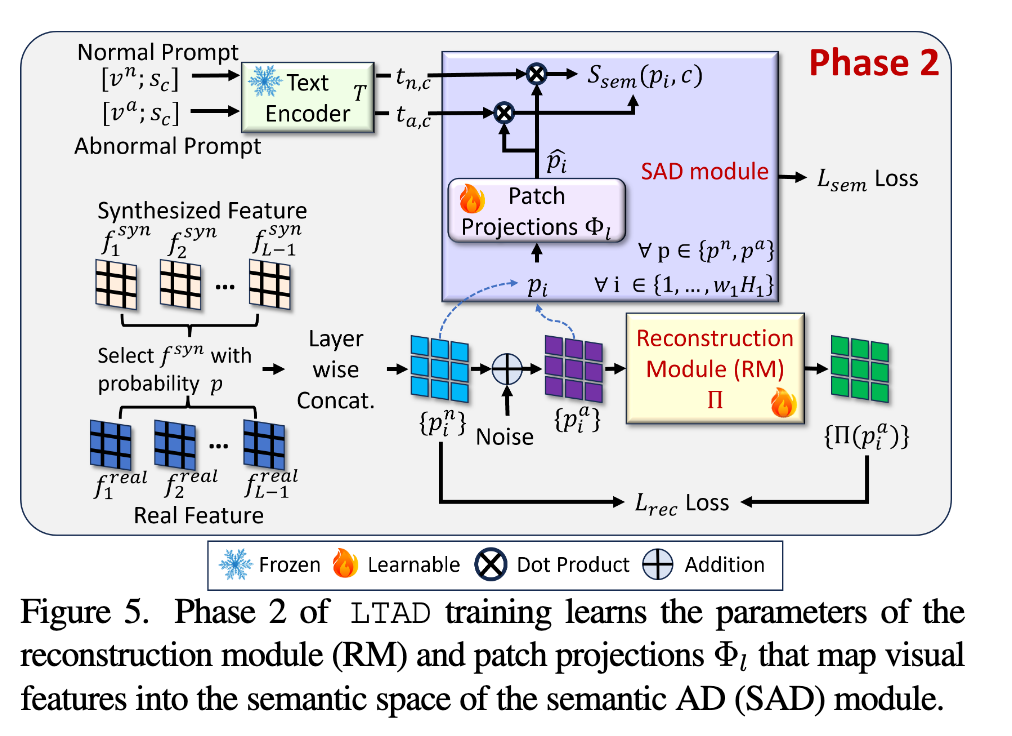
重建模块RM (Reconstruction Module): 训练RM Π(.)在正常patch feature $𝑝_𝑖^𝑛$的流形中,将伪异常patch feature $𝑝_𝑖^a$投影到重建patch feature Π( $𝑝_𝑖^a$ )中。
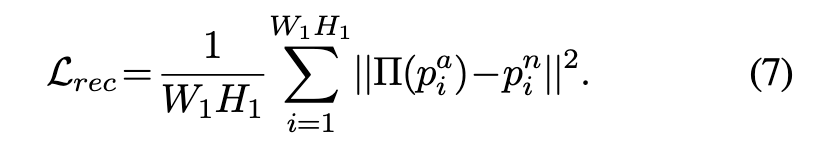
语义patch投影:Φl函数计算patch pi到ALIGN语义空间的投影,通过最小化二值交叉熵损失,训练函数Φl来鼓励投影补丁特征和文本特征之间的对齐
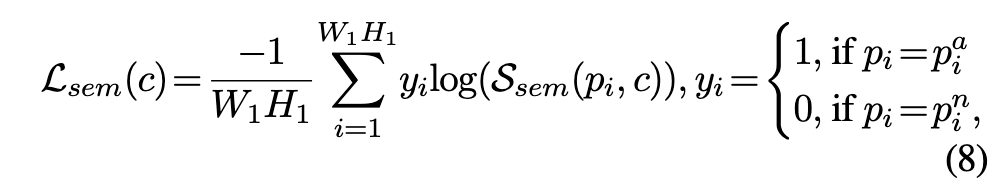
实验
Datasets
MVTec:用于工业异常检测的综合数据集,包含15种类别的真实制造缺陷图像(如瓶子、金属零件),广泛用于评估无监督异常检测方法。
VisA:视觉异常数据集,涵盖更多复杂的工业场景(如电路板和组件)和细粒度的异常类型,是检测和定位多样化缺陷的重要基准。
DAGM:一个经典的合成工业缺陷数据集,包含纹理均匀的背景和人工生成的缺陷,用于评估工业表面缺陷检测方法的性能。
Metrics
AUROC(image and pixel level for AD and AS),在长尾实验中具体为average performance (Avg)、average performance for majority classes (High)、average performance for minority classes (Low)
Result
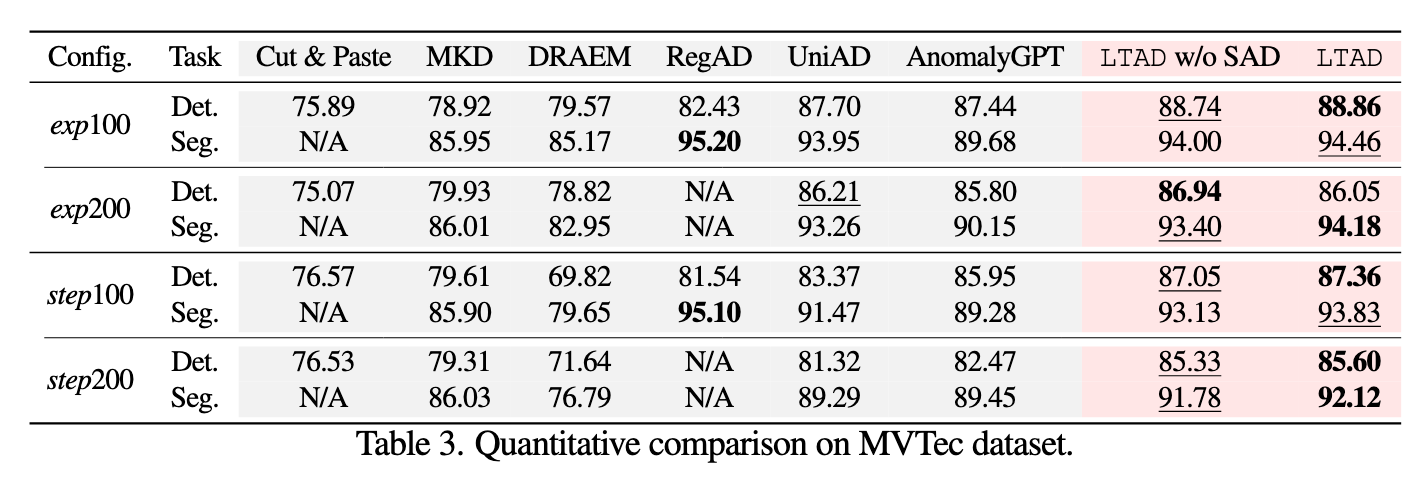
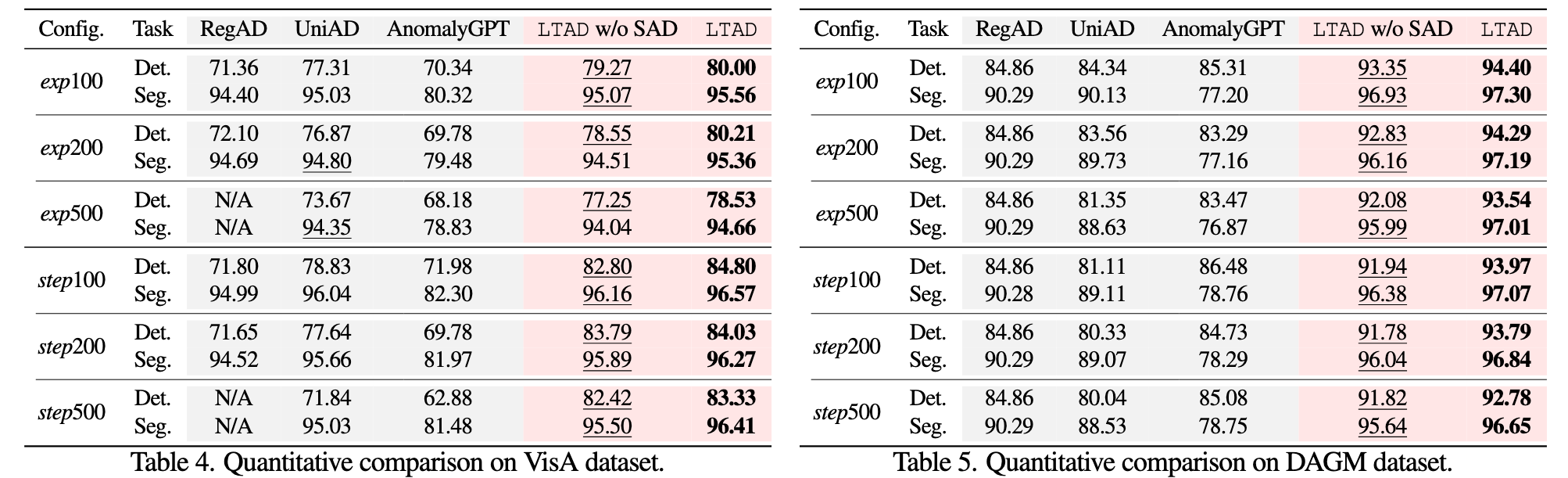
每个数据集配置的最佳和次优性能分别以粗体和下划线突出显示。
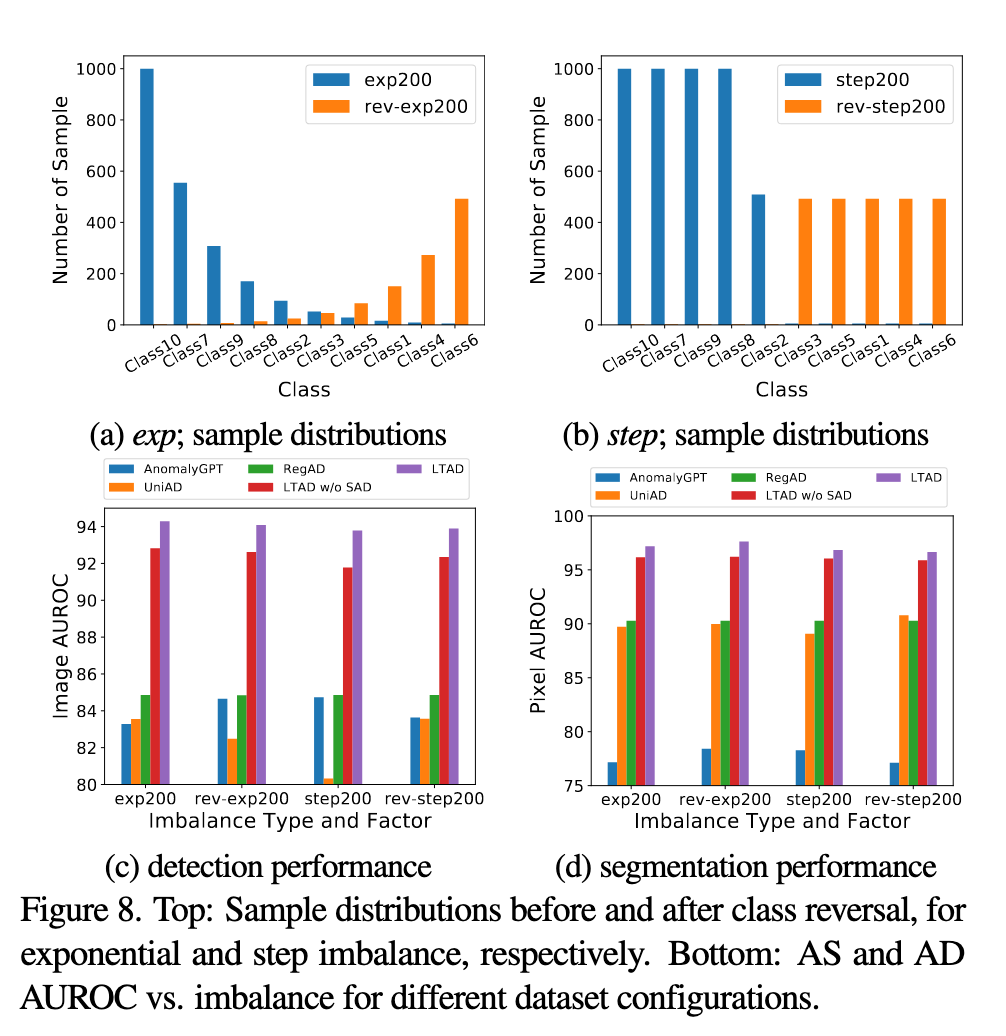
Result Visualization

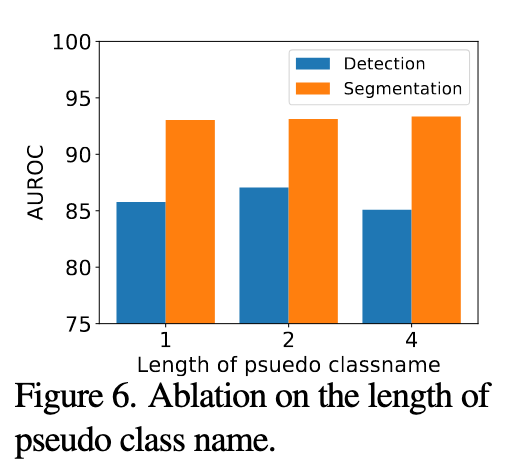
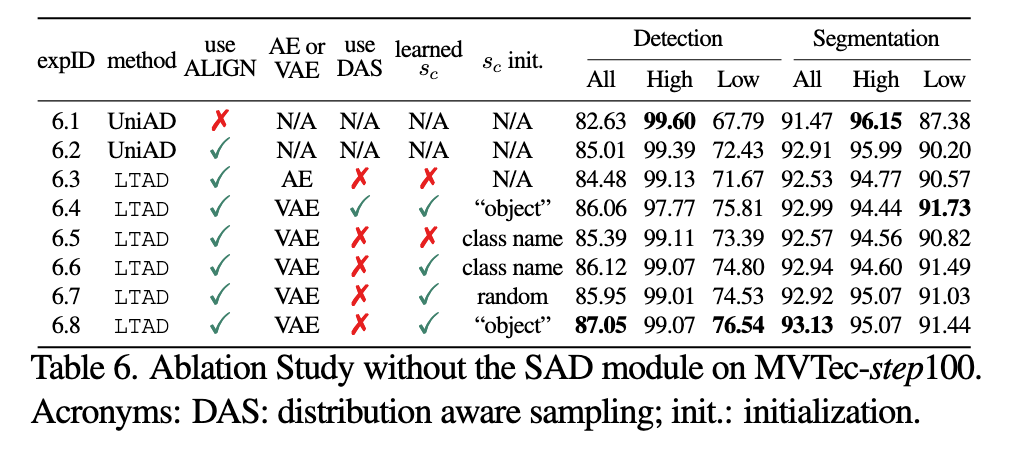
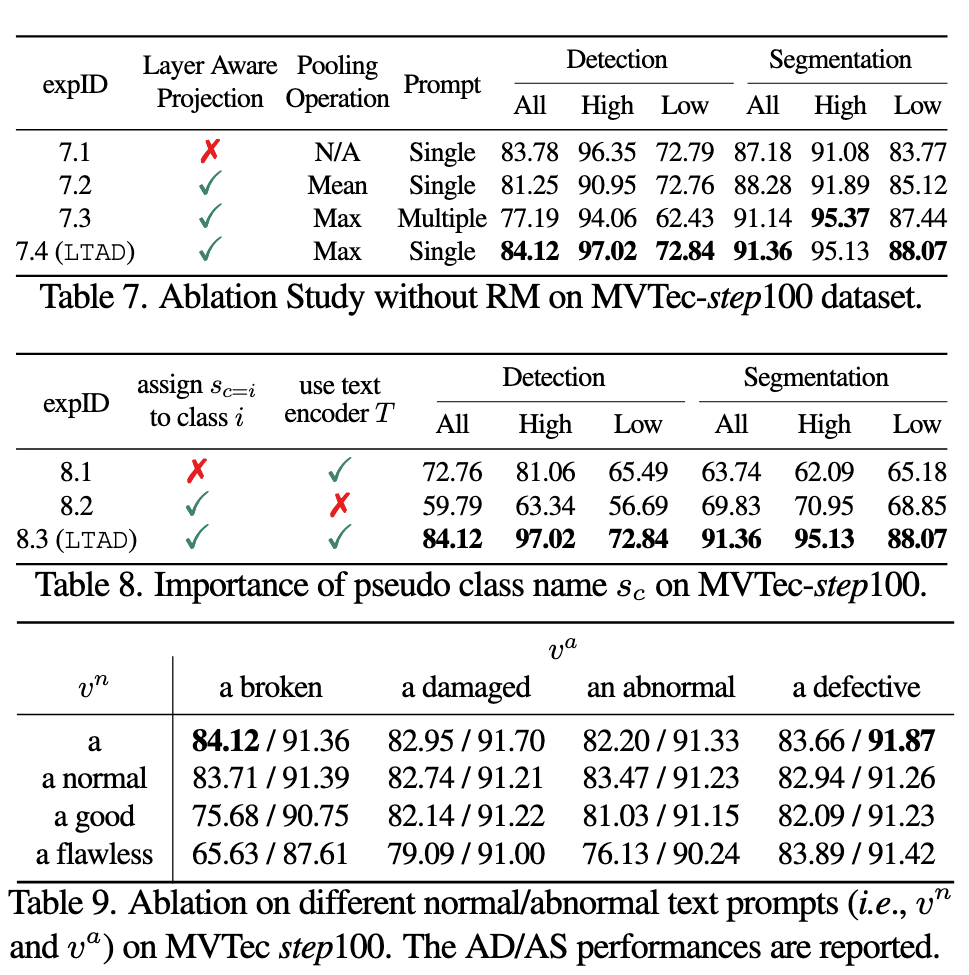
Ablation Study
总结
本文提出的 LTAD 方法不依赖于数据集中的分类名,通过结合基于重构与语义的AD模块,实现了对长尾分布下多类别异常检测的高效处理。
提供了一种解决实际应用中数据样本分布不均和类别名称未知等问题的通用框架,为长尾异常检测问题的研究奠定了基础。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享