
ViT——Vision Transformer介绍
编辑论文:AN IMAGE IS WORTH 16 X 16 WORDS :TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICCV 2021)
背景

在自然语言处理(NLP)领域,Transformer架构已经成为标准,但其在计算机视觉(CV)中的应用仍然有限。传统的卷积神经网络(CNN)在图像识别任务中表现优异,但随着网络深度的增加,训练变得更加困难。研究者们希望能够将Transformer的优势引入图像识别领域,以提高模型的性能和训练效率。
在NLP领域,Transformers的计算效率和可扩展性使得训练前所未有的大规模模型变成可能。
在CV领域,已经存在将self-attention与CNN结合或直接更换卷积的尝试,但都不够成熟。
动机

基于此种背景,探索Transformer在图像识别任务中的有效性,尤其是在大规模数据集上的表现。研究者们发现,尽管CNN在图像处理上表现良好,但Transformer在处理大规模数据时,能够以更少的计算资源实现更好的性能。因此,作者希望通过直接将Transformer应用于图像块(patches),来验证其在图像分类任务中的潜力。
简要概括为将不做过多修改的标准架构的Tansformer直接应用到图像处理上
标准的架构的Transformer在中小型数据集上表现不如ResNets,主要原因是Transformer缺少一些CNN网络固有的inductive biases 归纳偏执,例如locality 局部性和translation equivariance 平移不变性,当在不充足的数据集上训练时,transformer表现不尽如人意。
然而当使用大型数据集时,ViT在多个图像识别基准上接近或超越了最新水平,这是很让人惊喜的。
方法
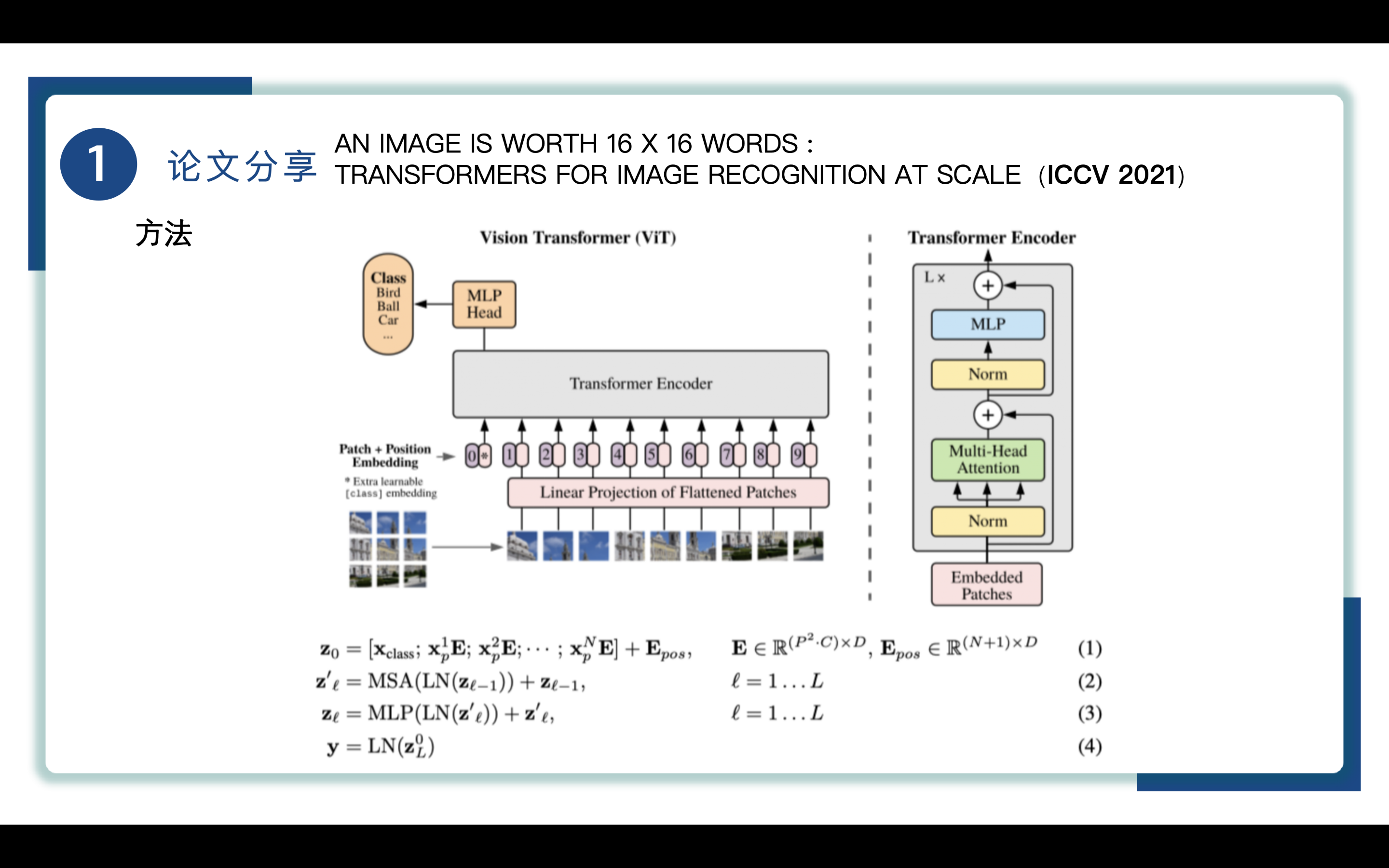
具体的模型如图所示,标准的Transformer接受一个1D的token序列向量,为了处理2D的图片,将图片进行patch块的划分,输入图片会被P P大小的patch块划分为N个patch,其中N = H W / P^2,在这里我们使用D代表Transformer所有层的向量大小,在这张图中我们就需要把划分的9个patch按序列展开与D相匹配,进行线性投射的操作,这里的线性投射的作用是将每个展平的块通过一个线性层映射到一个固定的维度,通过投射得到的结果我们称之为patch embeddings。到这里我们其实已经把一个CV问题转换为了NLP问题。
为了最后实现分类 在这里我们添加了一个特殊的字符,也就是图上的extra learning 【class】 embedding,这个cls特殊字符只有一个token,维度与D相同,我们将cls的输出作为整个图片的特征,所以最后总体进入Transformer的序列长度应该是(N + 1)x D。最后呢我们还要加上位置编码信息,也就是position embedding
位置编码在图中就是1-9的序号,但这并不是我们真正使用的位置编码,具体的位置信息由D维度的向量表来表示,位置编码信息会被直接加到token序列上,token序列长度保持不变,到此图片的预处理就被做完了。
看右图,我们刚处理完的序列便是这里的embedded patchs,首先经过一个Norm层进行归一化,使得模型在训练过程中更加稳定,拥有更好的泛化能力,再进入一个多头的自注意力,这里变成了三份K Q V,最后将M个头的数据拼接起来得到完整的输出,再过一层Norm,最后到MLP,MLP这里会把维度相对应放大,一般是放大四倍,在缩小投射回去,最后得到结果,这就是一个Transformer的前向传播的过程。我们可以不断堆叠Transformer Blocks,堆叠的到的L层的Transformer Blocks就是Transformer Encoder
之后Transformer得到了cls输入对应的输出,该输出聚合了全局的特征,通常会进入一个MLP Head(多层感知机头)。这个MLP Head负责将CLS块的输出特征进行进一步处理,通常包括一个或多个全连接层,最后输出分类结果。通过这种方式,模型能够将提取的特征映射到具体的类别标签上,以此输出最后的分类结果。
实验
在实验部分作者使用ResNet、Vision Transformer和hybrid混合模型进行对比实验。
先来讲一下ViT
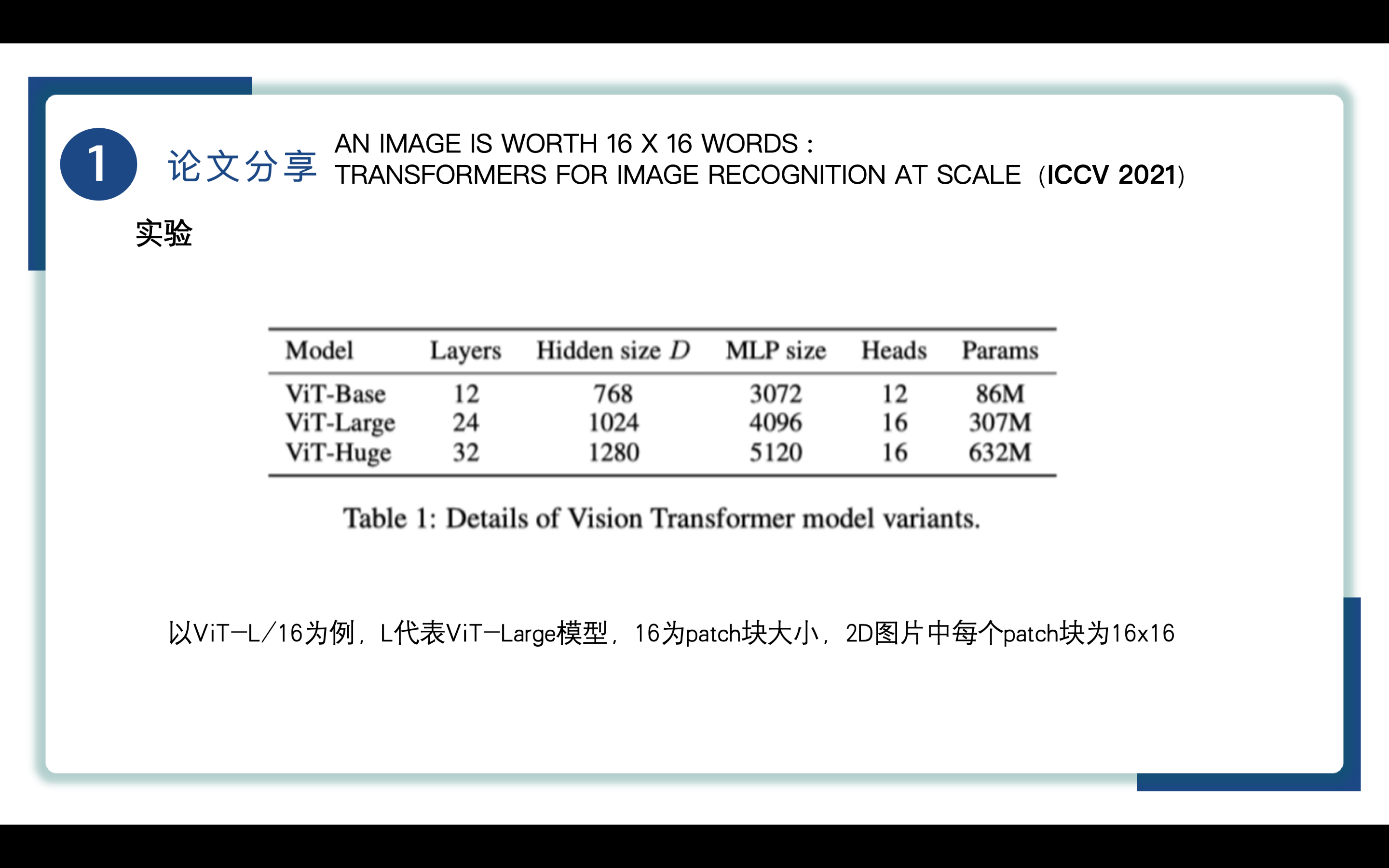
ViT共有三种大小的模型,分别是Base、Large、Huge,在数据量充足的情况下,Huge性能最好。
这里我们以ViT-L/16为例,L代表ViT-Large模型,16为patch块大小,2D图片中每个patch块为16x16
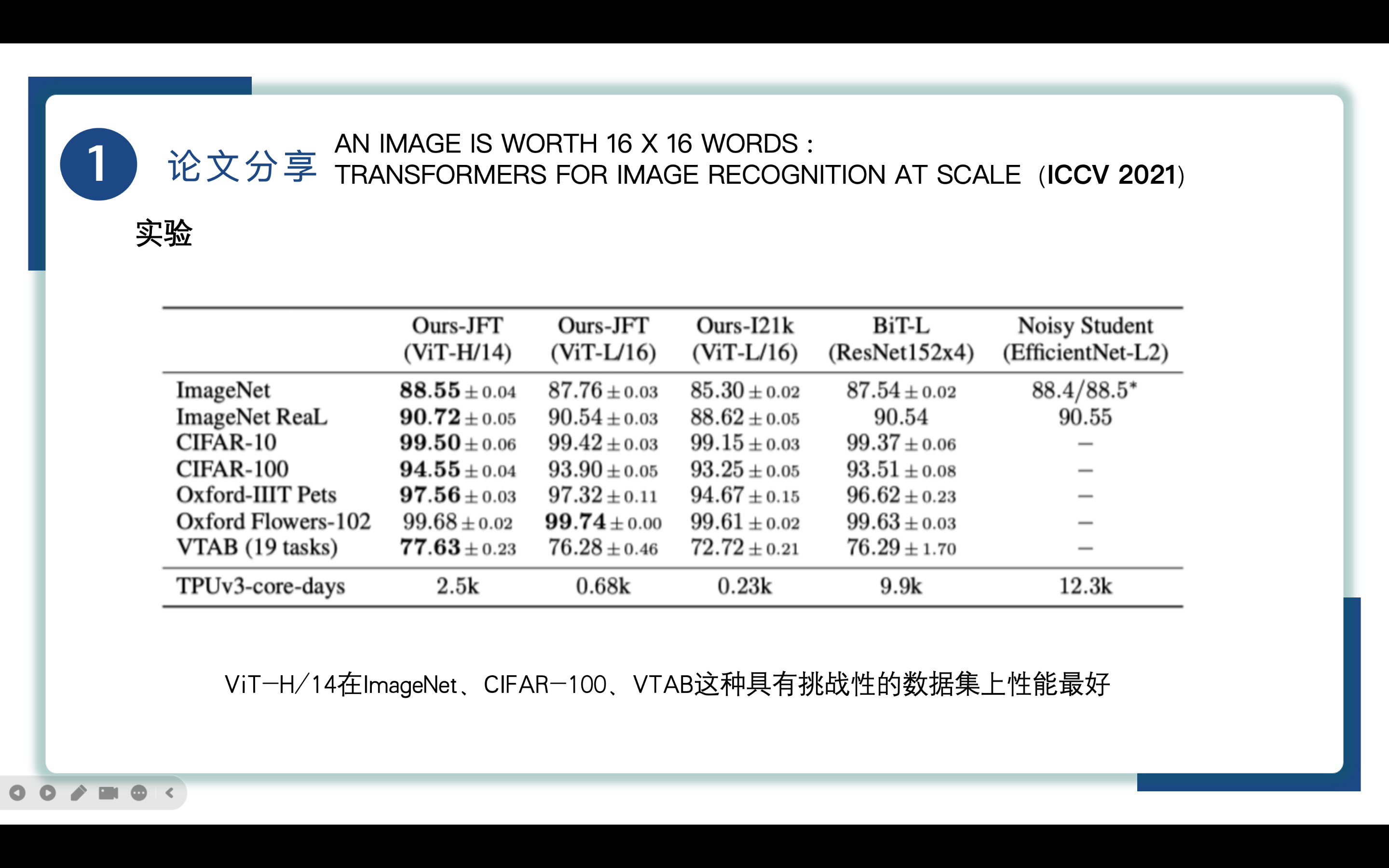
通过对比试验我们可以看到Vit-H/14在ImageNet、CIFAR-100、VTAB这种具有挑战性的数据集上性能最好,且相比之下它的预训练成本更低,可以看到即使是最大的ViT-H/14的TPUv3-core-days的训练天数也远小于ResNet和EfficientNet-L2.
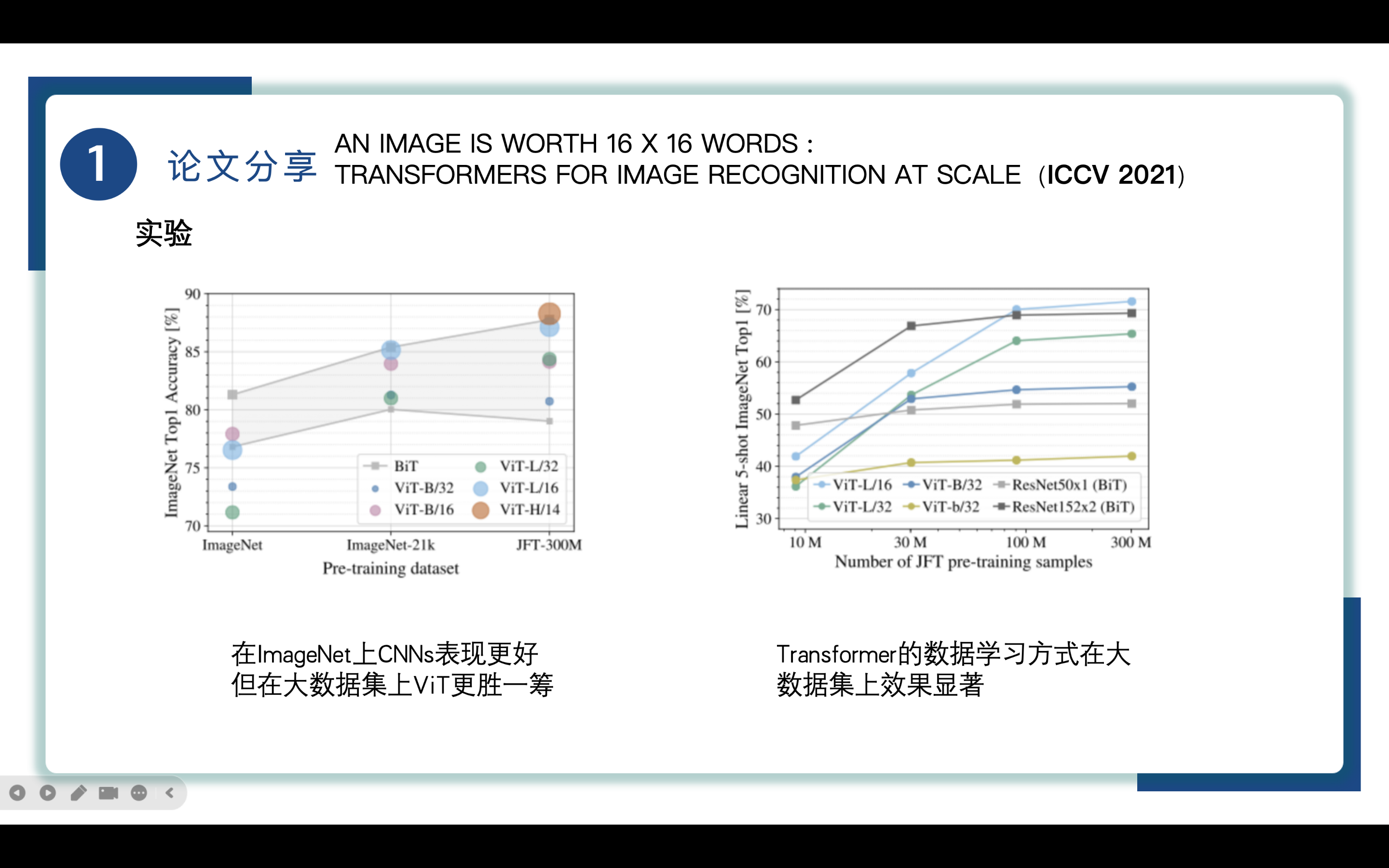
随后作者在不同数据量的数据集上进行预训练,先看左图,,这里的BiT(ReNet)的准确率是一个灰色部分的区域,在小型数据集上,ViT大型模型的表现不如ViT基础模型,且ViT总体表现没有BiT的ResNet好,当数据量进一步增大后,ViT表现能与残差网络相当,当数据量达到一定规模后,例如这里的JFT-300M,我们能够看到ViT大型模型的优势了。
再看右图,实验结果表明:卷积归纳偏差对于较小的数据集有用,但对于较大的数据集,直接从数据中学习相关模式是出色的。
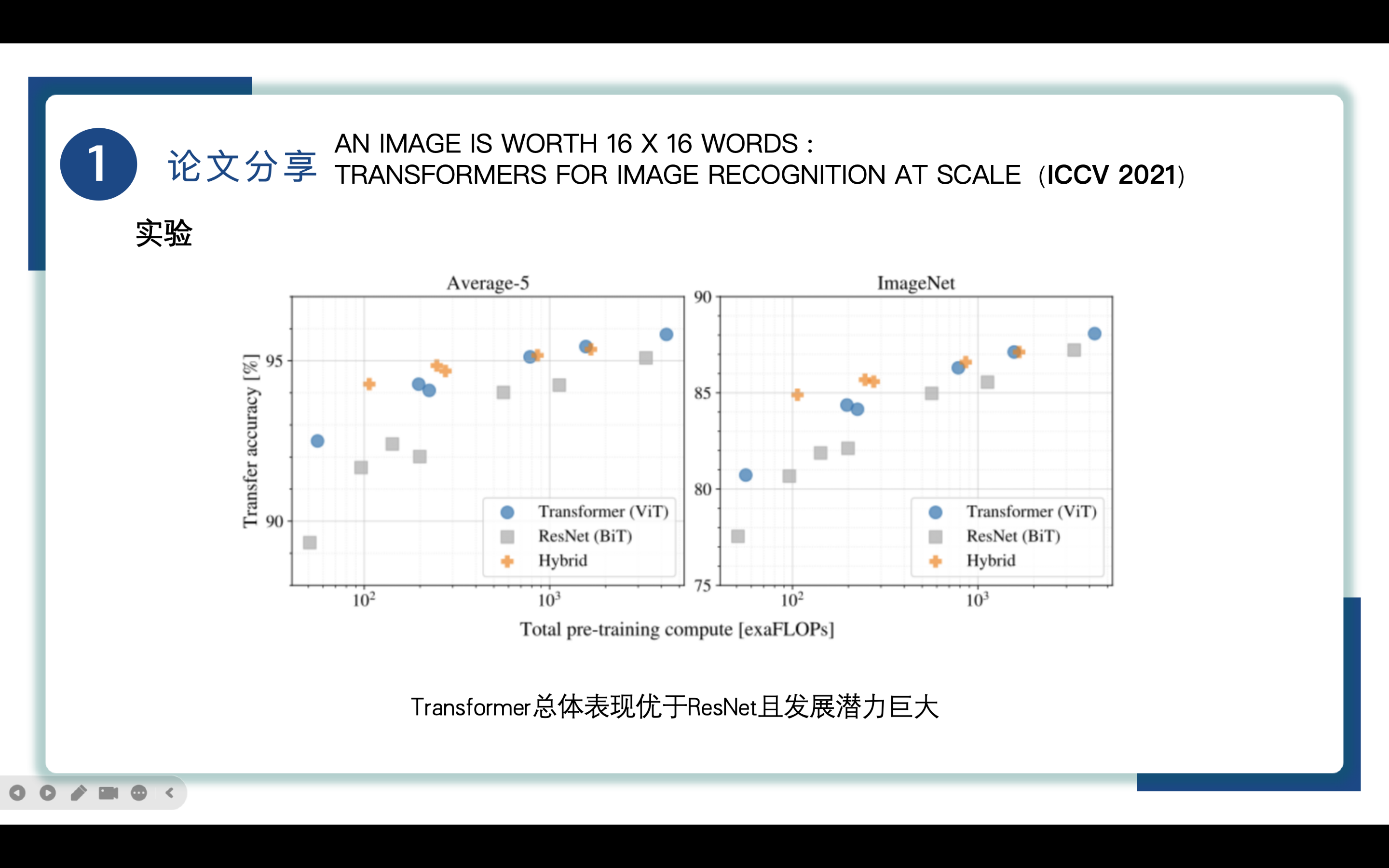
作者也从三种不同模型的迁移准确率进行实验对比,实验结果表明Vision Transformers在性能/计算权衡方面更出色。其次,混合动力在较小的计算预算下略优于ViT,但对于较大的模型,差异消失。最后,Vision Transformers似乎并未在尝试的范围内饱和,表明了Vision Transformer未来的发展潜力。
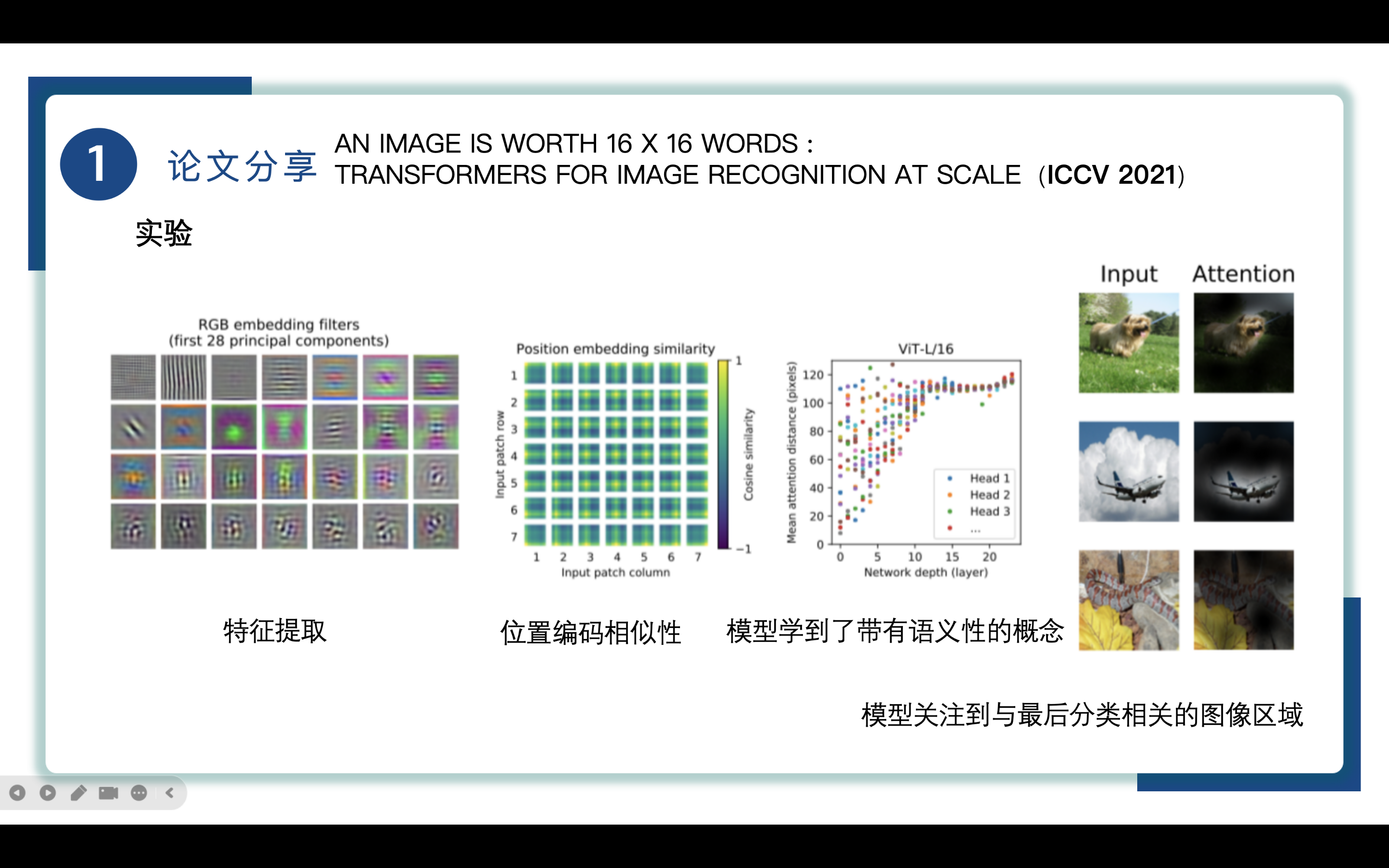
最后来总结一下ViT是如何工作的
Vision Transformer的第一层将图像切割的patch到较低维空间。左图显示了学习到的嵌入滤波器的顶部主成分,也就是输入图像的纹理、边缘等特征。
投影后,将学习到的位置编码嵌入添加到patch表示中。图7(中)显示,该模型在位置嵌入的相似性中学习对图像内的距离进行编码,即距离越近的patch往往有更多相似的position embedding。此外,出现了行-列结构;同一行/列中的patch具有相似的embedding。
self-attention允许ViT即使是在最低的层中也整合了来自网络的信息,具体来说,我们计算输出标记到输入的图像空间中信息是空间的平均距离。这个注意距离类似于cnn的感受野大小,随着网络的加深,各层之间能注意的像素空间不断增大,拥有全局视野,这意味着模型的信息整合能力、上下文捕捉能力进一步增强。
在Transformer之前应用ResNet的混合模型中,这种高度局部化的注意力不那么明显(图7,右),这表明它可能与cnn中的早期卷积层具有类似的功能。注意距离随网络深度的增加而增加。从全局来看,我们发现该模型关注到与最后分类相关的图像区域。
总结
Transformer除了开始对图片进行patch块的切割外,不依赖于CNN用到的图像局部性和平移不变性的 image-specific inductive biases归纳偏执(这也是CNN在small datasets上表现优秀的原因)
Tansformer预训练成本比CNN更低,在许多的图像分类数据集上表现突出
这篇论文展示了Transformer在图像识别任务中的潜力,尤其是在大规模数据集上的应用。通过引入Vision Transformer(ViT),作者成功地将自注意力机制应用于图像处理,证明了Transformer在CV计算机视觉领域的有效性。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享