
PyTorch——MNIST数据集手写数字识别
编辑介绍
PyTorch是一种流行的深度学习框架,具有多个核心优势,使其在研究和工业界广受欢迎:
动态计算图:
PyTorch采用动态计算图(Define-by-Run),这意味着计算图在运行时构建,允许用户在每次迭代中修改网络结构。这种灵活性使得调试和开发更加直观和方便。
强大的GPU加速:
PyTorch支持GPU加速,能够高效地处理大规模的张量运算。这使得训练深度学习模型的速度显著提升,尤其是在处理复杂的神经网络时。
易于使用和学习:
PyTorch的API设计简洁明了,易于上手,特别适合初学者。其与Python的紧密集成使得用户能够利用Python的丰富生态系统。
丰富的社区支持:
PyTorch拥有一个活跃的社区,提供大量的教程、文档和开源项目。这使得用户能够快速找到解决方案和学习资源。
与NumPy兼容:
PyTorch的张量操作与NumPy非常相似,用户可以轻松地在两者之间切换,利用NumPy的功能进行数据处理。
自动微分:
PyTorch提供了强大的自动微分功能,用户可以轻松计算梯度,这对于训练神经网络至关重要。
PyTorch因其灵活性、易用性和强大的性能,成为了深度学习领域的重要工具,适合从研究到生产的各种应用场景。
MNIST(Modified National Institute of Standards and Technology)数据集是一个广泛使用的手写数字识别数据集,常用于机器学习和深度学习的研究与实验。它包含了大量的手写数字图像,具体特点如下:
数据规模:
MNIST数据集包含60,000个训练样本和10,000个测试样本。这些样本都是28x28像素的灰度图像,表示数字0到9。
数据来源:
数据集由美国国家标准与技术研究院(NIST)提供,经过修改和标准化,以便于机器学习算法的训练和测试。
应用广泛:
MNIST是机器学习领域的“Hello World”数据集,因其简单性和易用性,成为了许多算法和模型的基准测试数据集。
分类任务:
任务是将每个28x28的图像分类为对应的数字(0-9),这使得MNIST成为图像分类问题的经典示例。
性能评估:
研究人员和开发者通常使用MNIST来评估新算法的性能,许多现代深度学习模型在该数据集上取得了很高的准确率。
MNIST数据集因其简单性和广泛的应用,成为了机器学习和深度学习领域的重要基准数据集,适合用于初学者的学习和研究。
步骤
加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader定义超参数
BATCH_SIZE=64
DEVICE = torch.device("cuda" if torch.cuda.is_available()else "cpu")
EPOCHS=20 # 训练次数构建pipeline,对图像进行处理
pipeline=transforms.Compose([
transforms.ToTensor(), # 将图片转换为Tensor类型
transforms.Normalize((0.1307),(0.3081)) #正则化,模型过拟合时降低模型复杂度
])下载并加载数据集
train_set=datasets.MNIST("data",train=True,download=True,transform=pipeline)
test_set=datasets.MNIST("data",download=True,transform=pipeline)
train_loader=DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True)
test_loader=DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)查看数据
with open("C:/Users/ASUS/Python/PyTorch/data/mnist","rb") as f:
file=f.read()
image1=[int(str(item).encode('ascii'),10)for item in file[16:16+784]]
print(image1)
import cv2
import numpy as np
image1_np=np.array(image1,dtype=np.uint8).reshape(28,28,1)
print(image1_np.shape)
cv2.imwrite("digit.jpg",image1_np) # 保存图片构建网络模型
class Digit(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(1,10,kernel_size=5)
self.conv2=nn.Conv2d(10,20,kernel_size=3)
self.fc1=nn.Linear(20*10*10,500)
self.fc2=nn.Linear(500,10)
def forward(self,x):
input_size=x.size(0)
x=self.conv1(x)
x=F.relu(x)
x=F.max_pool2d(x,2,2)
x=self.conv2(x)
x=F.relu(x)
x=x.view(input_size,-1)
x=self.fc1(x)
x=F.relu(x)
x=self.fc2(x)
output=F.log_softmax(x,dim=1)
return output定义优化器
model=Digit().to(DEVICE)
optimizer=optim.Adam(model.parameters()) # 选择Adam优化器定义训练方法
def train_model(model,device,train_loader,optimizer,epoch):
# 模型训练
model.train()
for batch_index,(data,target) in enumerate(train_loader):
# 部署到DEVICE上面
data,target=data.to(device),target.to(device)
# 梯度初始化为0
optimizer.zero_grad()
# 前向传播获取结果
output=model(data)
# 计算损失
loss=F.cross_entropy(output,target) # 多分类用交叉验证
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if batch_index%3000==0:
print("Train Epoch :{} \t Loss :{:.6f}".format(epoch,loss.item())) 定义测试方法
def test_model(model,device,test_loader):
# 模型验证
model.eval()
# 定义正确率
correct=0.0
# 定义测试损失
test_loss=0.0
# 计算损失
with torch.no_grad():
for data,target in test_loader:
# 部署到device上
data,target=data.to(device),target.to(device)
# 测试数据
output=model(data)
# 计算测试损失
test_loss+=F.cross_entropy(output,target).item()
# 找到概率最大的下标
pred=output.argmax(1)
# 累计正确的值
correct+=pred.eq(target.view_as(pred)).sum().item()
test_loss/=len(test_loader.dataset)
print("Test--Average Loss:{:.4f},Accuarcy:{:.3f}\n".format(test_loss,100.0 * correct / len(test_loader.dataset)))调用方法
for epoch in range(1,EPOCHS+1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)结果
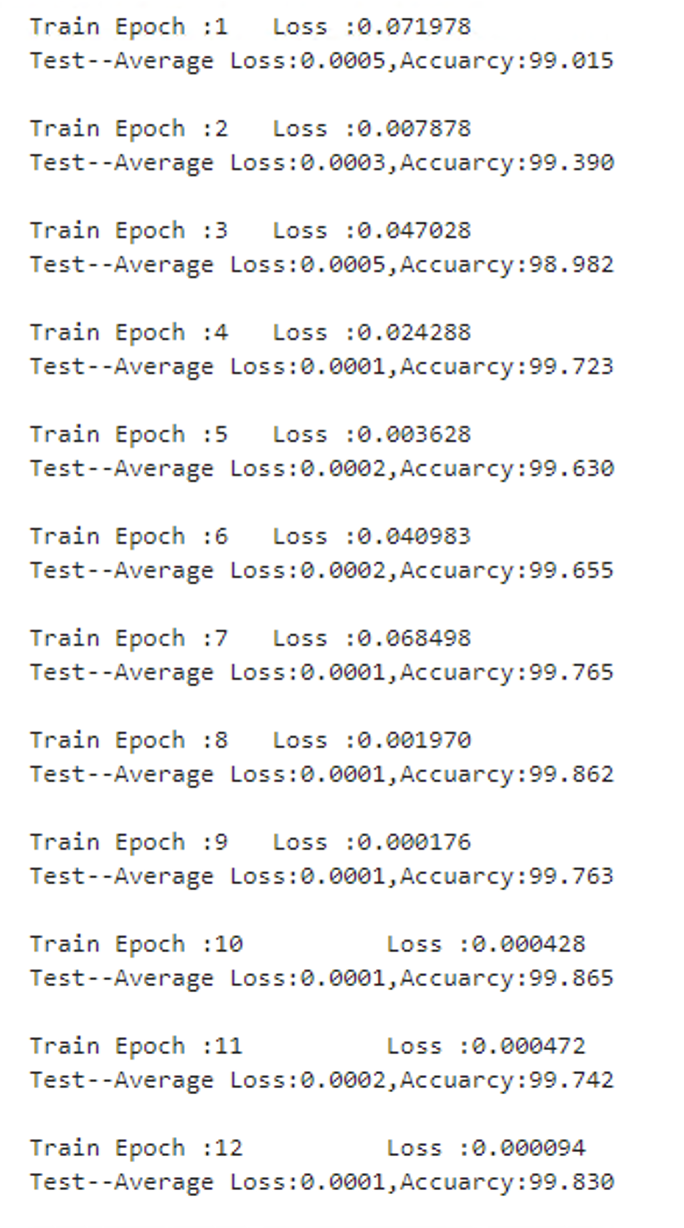
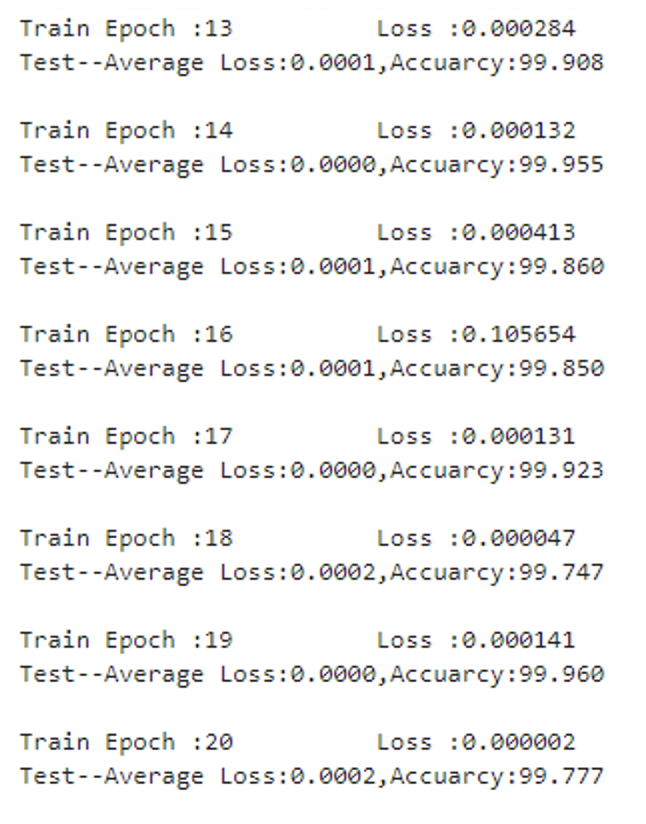
总结
MNIST数据集为深度学习研究提供了一个良好的起点,以下是一些详细的总结要点:
易于上手:
MNIST因其数据集规模适中且数据清晰,成为初学者学习深度学习和机器学习的首选。新手可以通过MNIST快速理解数据预处理、模型构建、训练和评估的整个流程。
基准测试:
由于MNIST数据集的广泛使用,许多研究和算法都以其为基准进行测试。开发者可以通过在MNIST上验证模型性能,来展示其在更复杂任务上的潜力。
深度学习模型:
尽管MNIST数据集相对简单,但它仍然可以用来训练各种深度学习模型,如卷积神经网络(CNN)、全连接网络等。这些模型能够学习到输入图像的特征,并有效地进行分类。
可扩展性:
在掌握了MNIST数据集后,研究人员可以轻松扩展到更复杂的图像数据集,如CIFAR-10、ImageNet等。这为深入学习计算机视觉领域提供了良好的基础。
工具与库的支持:
PyTorch及其
torchvision库为MNIST数据集的使用提供了强大的支持。通过简单的API,用户可以快速加载数据集,进行数据增强和预处理,极大地提高了开发效率。
在MNIST数据集上进行实验,不仅能够掌握深度学习的基本概念,还能为其后的研究和应用打下坚实的基础。MNIST的成功应用展示了神经网络在图像分类任务中的强大能力,也激励了更复杂的深度学习模型的发展。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享