
Toward Generalist Anomaly Detection via In-context Residual Learning with Few-shot Sample Prompts
编辑论文名称:Toward Generalist Anomaly Detection via In-context Residual Learning with Few-shot Sample Prompts(CVPR 2024)
论文链接:2403.06495v3.pdf
背景

通过论文的名称我们也能提取到几个文章的重点,Generalist Anomaly Detection GAD对应基础模型、In-context Residual Learning对应学习方式、Few-shot Sample Prompts对应参照数据。
那么为什么要提出这样的模型呢?
首先就是异常检测在工业缺陷检测、医疗图像分析和自然图像的语义异常检测等应用中越来越重要,但是当前的异常检测方法为每个特定任务的数据单独构建模型,带来了资源浪费和管理复杂性的问题,传统的异常检测方法依赖于大量的标注数据和特定的训练过程,这使得它们在面对不同数据集时的泛化能力受到限制。以及在特定的应用场景下,例如隐私政策、在部署新应用程序时无法获得大规模训练数据的困境使得目标训练集无法被用于模型训练。
动机

基于以上背景,作者提出了一种基于GAD和VLM的InCTRL模型。
该模型具有优秀的泛化性能,无需对目标数据集进行任何训练即可检测不同场景的不同数据集中存在的异常。能够使用few-shot normal images这种在实际应用中容易获取的数据作为sample prompts来支持模型进行推理运算,相较于当前其他存在的few-shot AD方法将sample prompts用于模型的训练,InCTRL的sample prompts仅被用在推理阶段测试图像的异常分数计算,这使得该模型具有更好的泛化性能,能够适应其他的数据集。模型通过残差来检测样本的异常情况,异常样本通常会比正常样本拥有更大的残差值,这也使得这种上下文残差学习的模型能够检测不同领域多种类的异常。
方法
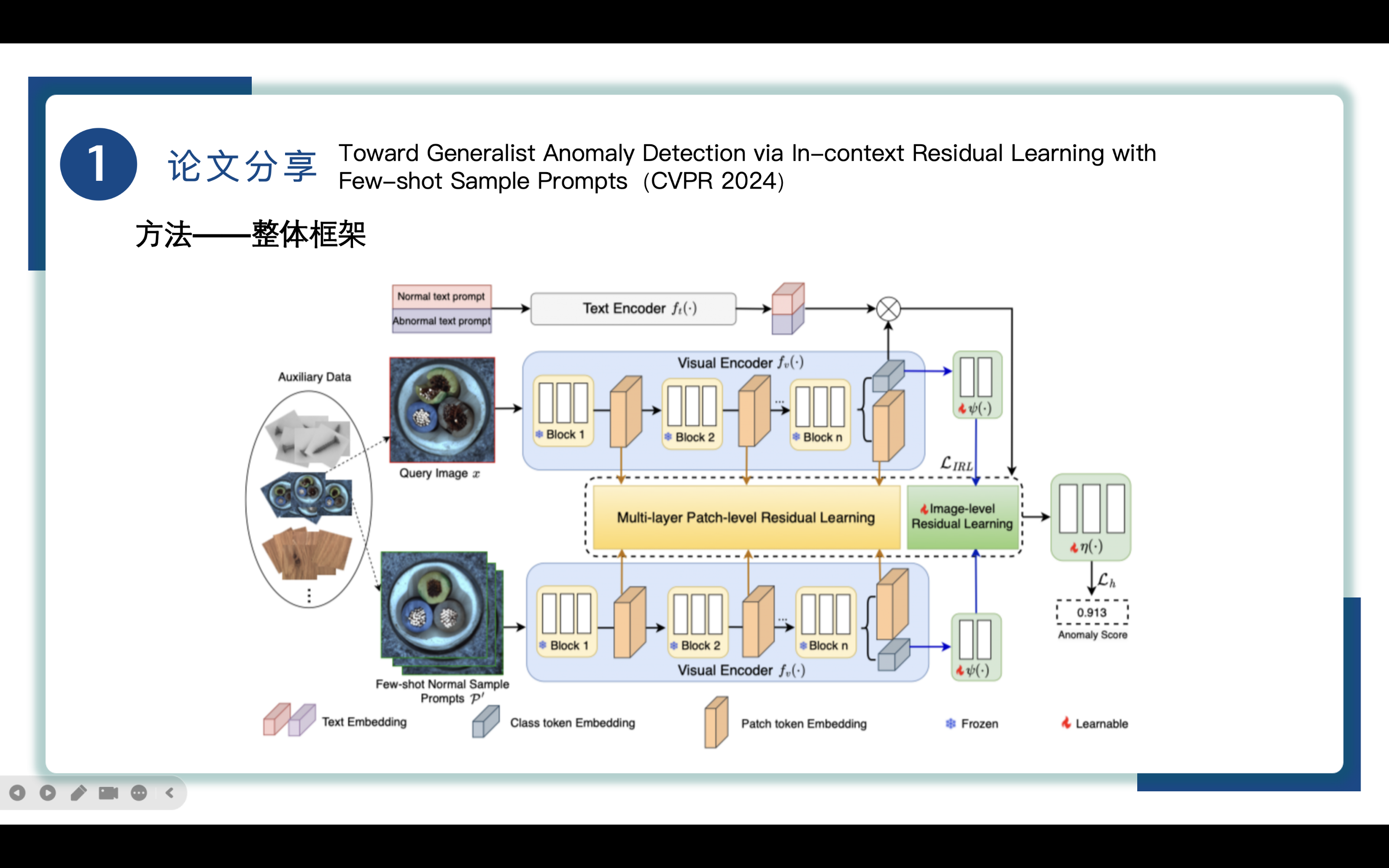
先来对模型的整体框架进行分析
1. 首先从auxiliary data中随机抽取查询图像query image x和一系列few-shot normal sample prompts P’。
2. 进入Visual Encoder,使用multilayer patch-level和image-level residual learning分别捕获查询图像和样本提示之间的局部和全局的区别。
3. 模型允许基于这些文本提示嵌入与查询图像之间的相似性,从text encoder中无缝地结合正常和异常文本提示引导的先验知识。
4. 使用adapter layer对特征进行调整,以让其适应异常检测的处理。
5. 将学习得到的残差信息,局部的异常分数进行计算得到最终的全局异常分数。

In-Context Learning ICL是一种在自然语言处理(NLP)领域中使用的学习方法,特别是在大型语言模型(如GPT-3)中。它允许模型在没有显式的微调或训练的情况下,通过上下文提示(prompts)来理解和执行任务。
ICL的关键思想是从类比中学习,左图给出了一个ICL 进行决策的例子。首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即你需要预测标签的 input)和一个上下文演示(一些相关的 cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。值得注意的是,与需要使用反向梯度更新模型参数的训练阶段的监督学习不同,ICL 不需要参数更新,并直接对预先训练好的语言模型进行预测(这是与 prompt,传统 demonstration learning 不同的地方,ICL 不需要在下游 P-tuning或 Fine-tuning)。我们希望该模型学习隐藏在演示中的模式,并据此做出正确的预测。
以上提到的是传统的ICL,采用传统的ICL的方法将注意力放在任务层面的泛化而不是异常检测的实例层面的泛化,所以作者对ICL进行了改造,改造的策略是将image prompts重新定义为特定于数据集的normal pattern,而不是作为特定任务的instruction。
具体方法是捕获query image和few-shot normal prompts之间的in-context residual。

再来讲一下两个重要的部分Multi-Layer Patch-Level Residual Learning和Image-level Residual Learning
为了更好地捕获块级别的残差,作者引入了Multi-Layer Patch-Level Residual Learning,使用CLIP的由一系列block组成的visual encoder学习不同抽象级别的视觉模式,由此从多层块中获取的patch token embedding来进行patch-level in-context residuals的建模。
patch-level in-context residuals通过计算query token embedding和image prompt token之间的距离进行捕获。通过公式(1)计算,对于查询图像x,它在每一层与提示图像之间的,其中x的每个块的残差值根据它的块嵌入和所有图像的最近块嵌入计算,形成residual map Mx,最终patch-level residual map需要再取个平均得到,即在n层残差图上取平均得到,具体为公式(2),Mx为后续的异常分数学习提供特征集。
除了局部的块级别的残差,图像级别的残差信息也十分重要,两者可以相互补充。由此作者引入了Image-level Residual Learning来捕获高级的query image和sample prompts之间的区别。
使用visual encoder最后一个block的class token embedding作为特征输入,由于CLIP最初是设计用作分类任务的,而异常检测的目标通常是属于同一个class的,这使得CLIP不太适用于异常检测任务,为了解决这个问题,作者加入具有可学习参数Θψ的adapter layerψ(·)以调整图像以进行进一步的异常检测处理,由此得到调整后的图像特征。
通过公式(3)得到image prompts的feature map Ip 和query image x的通过adapter layer调整之后的feature map,之后通过公式(4)逐元素的减法操作来计算二者之间的残差得到图像级差异特征Fx,最后使用公式(5)来计算损失进行优化,η是一个图像级别的异常分类学习器。Lb是二分类loss。

最后就是Text Prompt-based Prior Knowledge
以上提到的两个组建聚焦于残差学习,而InCTRL也使用text-prompt-guided prior knowledge,利用文本编码器提取文本提示引导的判别特征来补充之前获取的像素级和图像级的残差。
文本编码器是利用融合文本提示的先验知识,通过引入正常和异常的文本提示,利用文本-图像联合表征空间中的先验知识。这种做法帮助InCTRL利用CLIP预训练时的图像文本对齐信息,把握正常和异常样本背后的语义差异,进一步提升异常检测的性能。
通过公式(6)得到sa(x),sa(x)是x被分类为异常的概率,在后续计算全局异常分数时使用。

总结一下模型的训练和推理过程。
训练过程:
InCTRL执行整体残差学习,综合分块级别残差信息和图像级残差信息,并通过文本提示引导特征进行增强,计算查询图像对应的redisual map,计算整体的异常分数,计算损失函数不断修正模型参数以达到更好性能。
推理过程:
对于来自目标数据集的给定测试图像xt和K-shot normal image prompt P,通过visual encoder和adapter layer得到对应的residual map M和s,通过text prompt sets获取sa,最后计算全局的异常分数score。

这里给出了具体的异常分数计算和损失函数的计算公式。
异常分数的计算分为两步:
首先是计算Mx+,具体计算如公式(7)所示,这个残差图由3个部分组成:(1)Mx: 多层次图像块级上下文差异图 ;(2)si(x): 图像级残差图的异常分数,基于函数得出;(3)sa(x): 基于文本提示的异常概率,它表示了作为异常的可能性。
这些组成部分通过逐元素相加结合在一起,得到整个查询图像的残差图 。
得到Mx+后使用公式(8)计算最终的异常分数,其中ϕ()是一个全局异常分数计算函数,sp(x)用于关注局部异常区域,α是超参数,用于规定patch-level的残差分数的对整体异常分数的影响。
损失函数的计算分为两个部分,公式(5)我们在前面就已经分析过了,公式(9)是通过比较预测值和真实标签来优化最终的异常得分。
InCTRL的最终优化是通过最小化整体损失函数也就是公式(10)来实现的.
实验

来到实验部分,先给出实验用到的数据集和评价指标。
实验使用八个真实的异常检测数据集,分别是工业缺陷检测数据集、医学图像数据集、语义异常检测数据集。
我们在实验中主要关注AUROC和AUPRC两个指标,值越高性能越好。
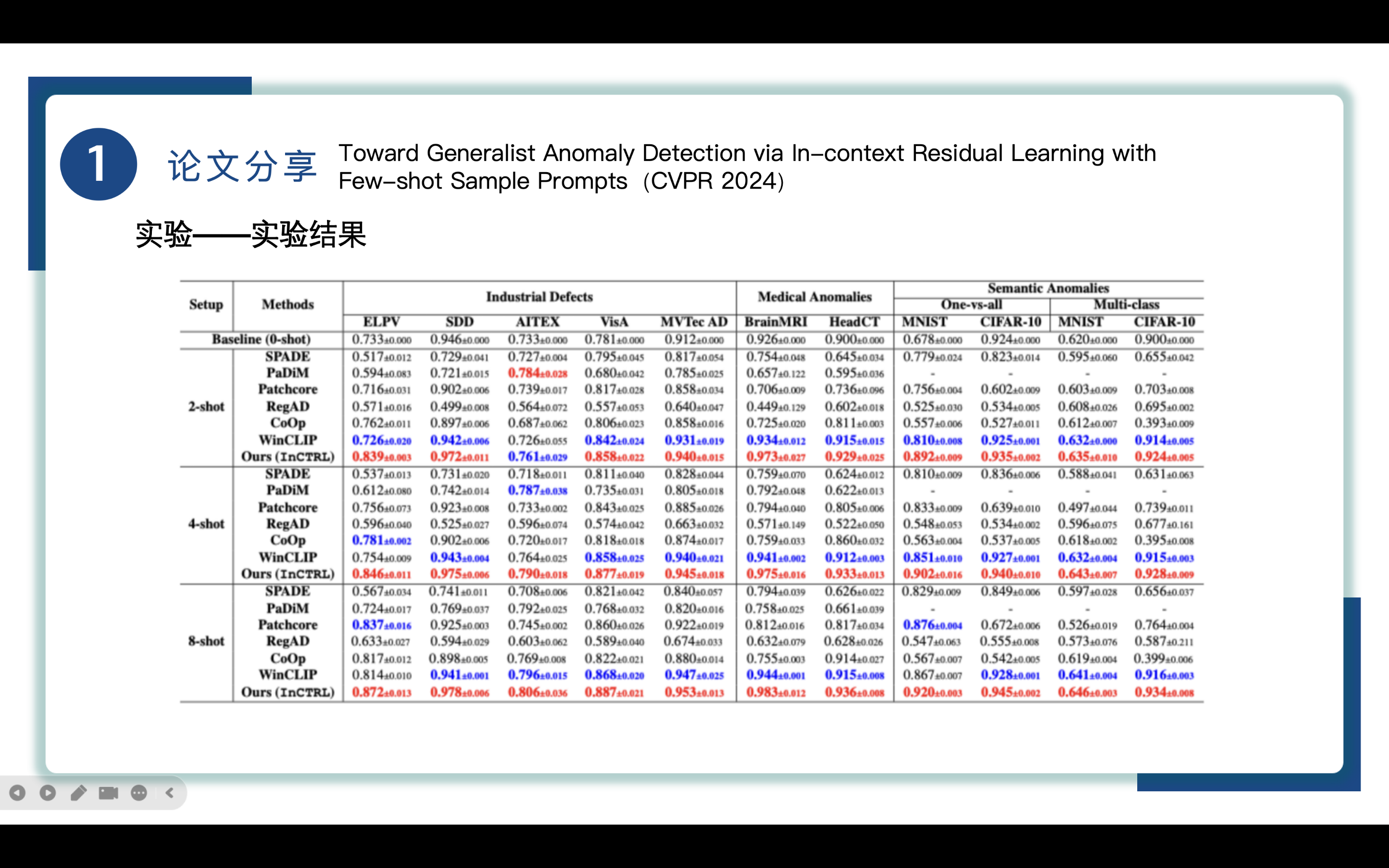
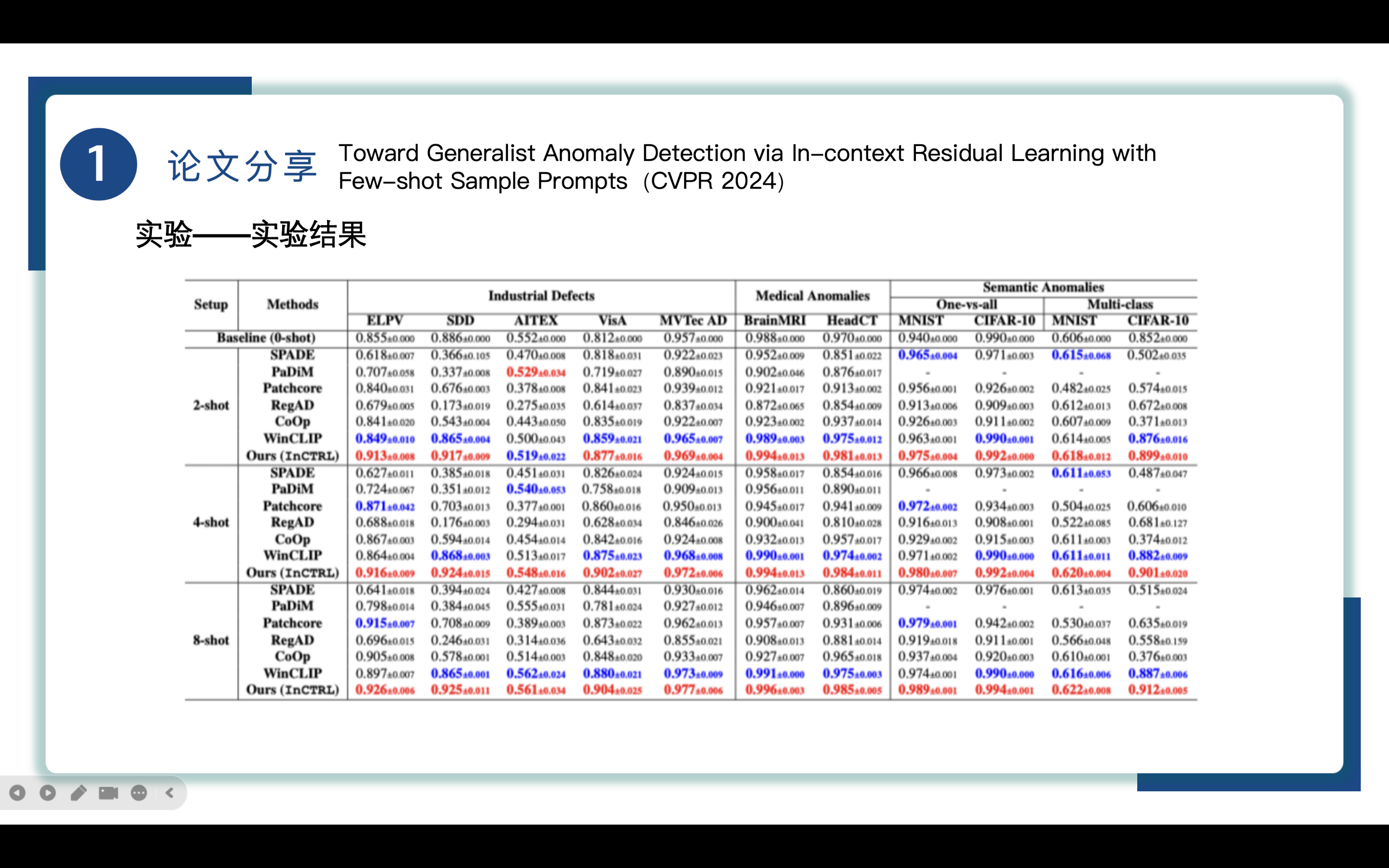
这张表展示了不同方法在不同数据集上的AUROC数值,以及下面这张表展示了不同方法在不同数据集上的AUPRC数值,红色代表最好性能,蓝色代表第二好性能,可以清楚地知道、、语义异常检测方面均表现突出。首先是工业缺陷检测方面,得益于CLIP卓越的检测性能和in-context residual information在多种数据集上的迁移能力,InCTRL方法在工业缺陷检测表现更好。来到医学异常检测领域,InCTRL表现也很出色。最后是在语义异常检测下,InCTRL能达到90%+的AUC,像RegAD和Co0p只有50%-65%的AUC,表明了InCTRL的出色性能。

InCTRL拥有这么出色的性能主要来源于三个部分,分别是text prompt-guided features (T),patch-level residuals (P), and image-level residuals (I),同时也包括它们的整合信息。我们看一下左图的实验结果,通过分析实验结果我们可以知道,对于工业缺陷检测来说视觉上的残差特征,也就是P和I比T来说更加重要。而在医学图像异常检测领域,视觉残差和文本知识互补使得模型表现突出。在语义异常检测领域,I和P更加重要。
为了理解In-context Residual Learning的重要性,作者也做了相关的实验,如左图所示,通过concatenation和average两种不同的操作进行实验,通过实验结果我们也能看到上下文残差学习比其他两种方法泛化得更好,显著提高了模型在不同领域的表现。
通过另一个实验,如右图所示,我们得到了当提示集拥有更多的normal classes时InCTRL的性能会不断提高的结论。
总结
到此我们来总结一下InCTRL这篇论文。
InCTRL通过少量正常样本提示的整体上下文残差学习实现了优越的广泛性学习泛化,展示了在不同应用领域良好的泛化能力,能够有效地识别各种类型的异常,为未来的异常检测方法提供了新的思路,尤其是在数据稀缺的情况下,具有重要的应用潜力。
参考资料
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享