
Multimodal Knowledge Transfer of Foundation Models for Open-World Video Recognition
编辑论文链接:https://arxiv.org/pdf/2402.18951
论文来源:arXiv 2024
背景
现有的视频识别模型使用的是在理想条件下收集的经典视频数据集,但在实际场景下存在复杂的相机拍摄环境,目标分辨率低,光照条件差,视频场景不寻常的多种问题,现有的大多数视频识别模型由于缺乏外部领域知识而不能很好地泛化,应用效果差。
基础模型包含了多样化的语义知识,可以适应低概率泛化,但是利用这些模型的知识进行开放世界视频识别的方法还有待研究。
动机
开放世界视频识别面临的挑战在于传统网络在复杂环境变化下的泛化能力不佳。作者希望利用和整合来自基础模型的外部多模态知识,以提升开放世界视频识别的性能。
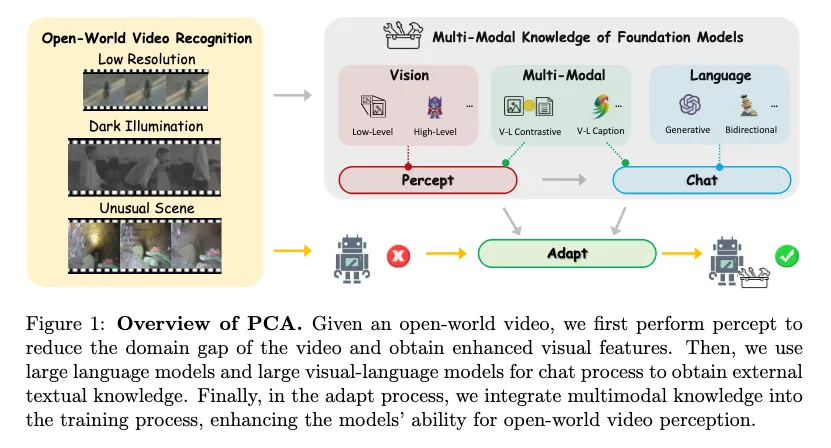
提出通用的知识转移范式 PCA(Percept,Chat and Adapt)
Percept:通过低级视觉模型增强视频以减小领域差异,使用主干的视觉编码器中提取增强视频的外部视觉知识。
通过与大型语言模型或多模态语言模型交谈,进一步生成关于预测标签或视频的文本描述,这种多样化的描述被用作关于视频的外部文本知识。
引入了独特的多模态知识自适应模块,灵活地将各种互补知识融合到视觉主干中,以增强开放世界视频识别。
方法
Framework
Percept
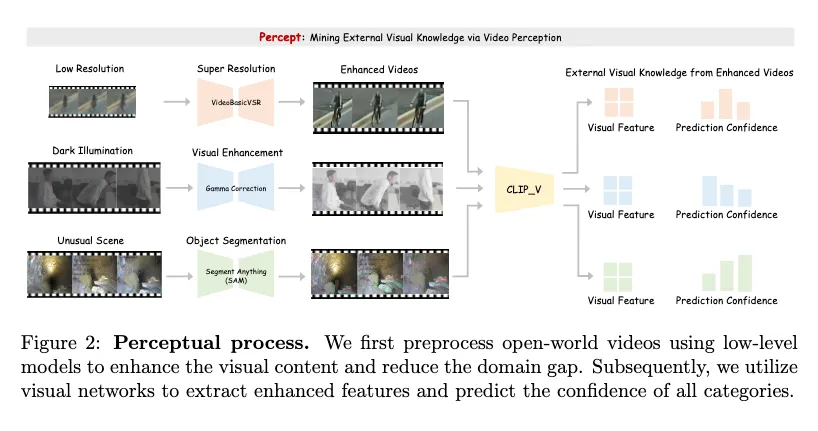
减少开放世界视频之间的领域差异
采用视觉增强模型F对给定视频V进行预处理以减小领域差异,丰富视频的视觉信息。
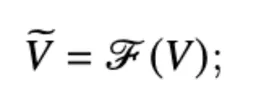
其中等式左边的V代表通过F增强后的视频 随后使用视频基础模型B提取增强的视频特征FV和预测分数S(S代表每个预测标签的可信度)
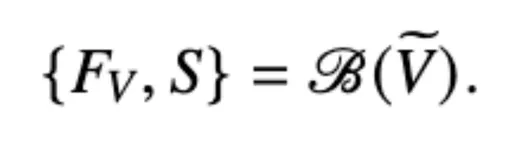
Chat
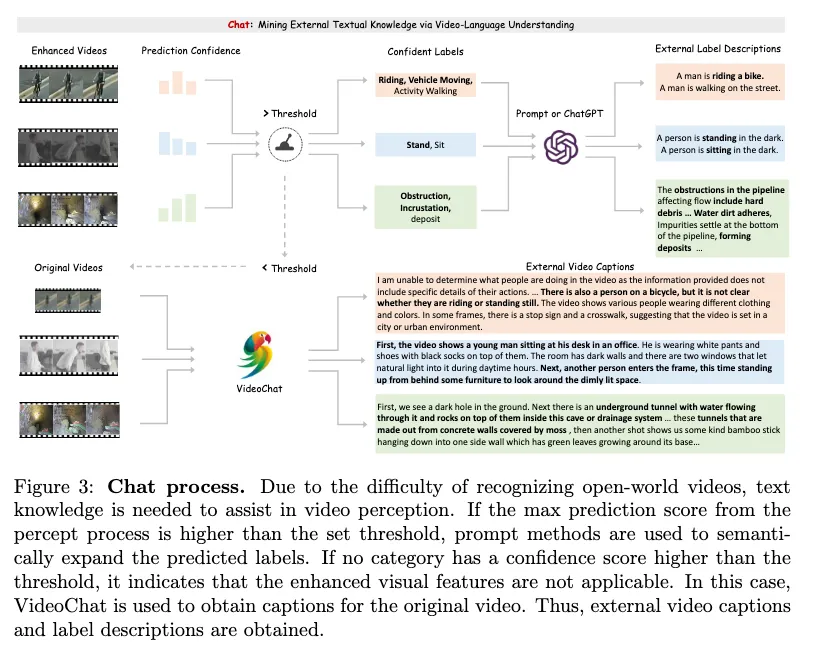
视频语言理解挖掘外部文本知识 通过VLM和LLM提取额外的外部文本知识以补充Percept阶段得到的增强视觉特征。
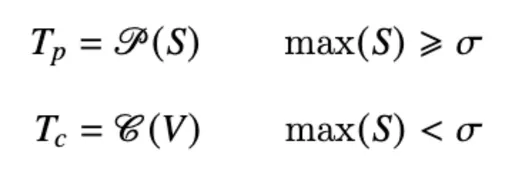
其中S代表Percept阶段得到的Scores。
当最大的Score超过阈值σ时,执行提示方法或GPT(P)来获取补充标签的文本知识(TP)。
当最大的Score小于阈值σ时,则直接将原始视频输入VideoChat(C),获取外部视频文本描述(Tc)。
最后使用BERT模型(L)得到包含外部文本知识的特征。
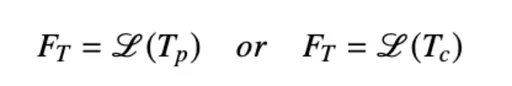
Adapt
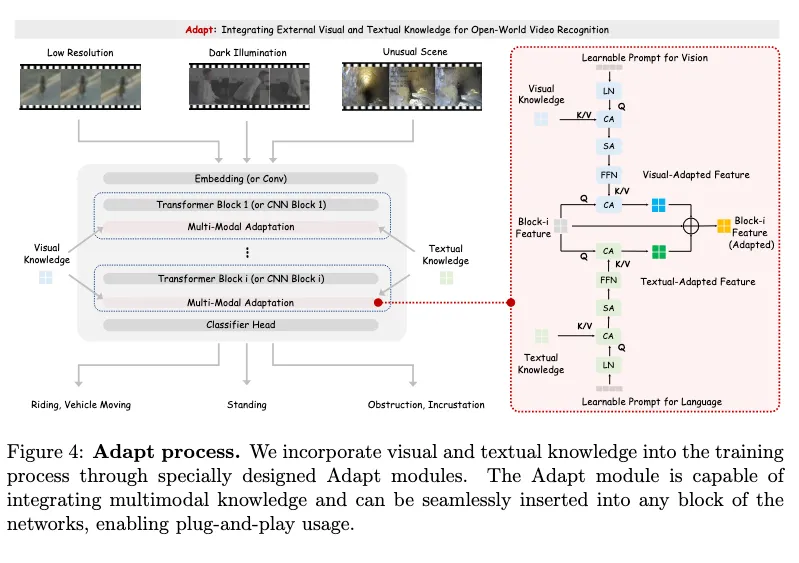
集成外部的视觉和文本知识进行视频识别 引入可学习的提示和注意机制以整合外部知识。通过Cross-Attention(CA)和规范的可学习提示符PL ,再经过SA和FFN处理获取压缩后的知识表示。

随后获取文本自适应特征GT和视觉自适应特征GV,其中FB为query。
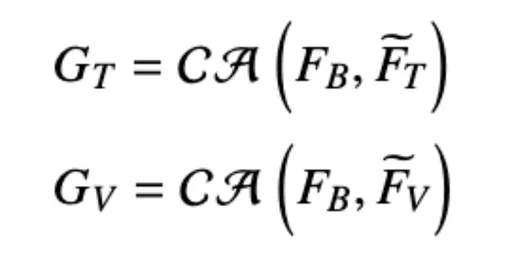
通过加权加法将文本自适应特征GT和视觉自适应特征GV与基础模型的中间层特征FB进行融合。
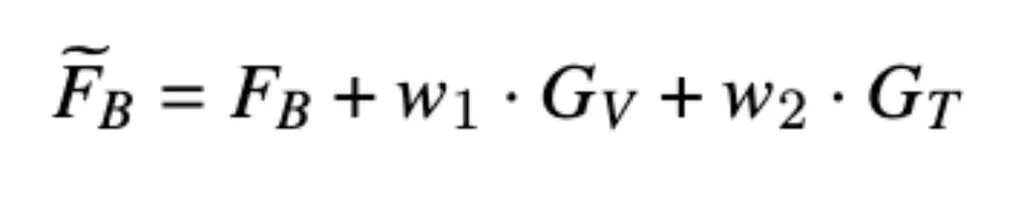
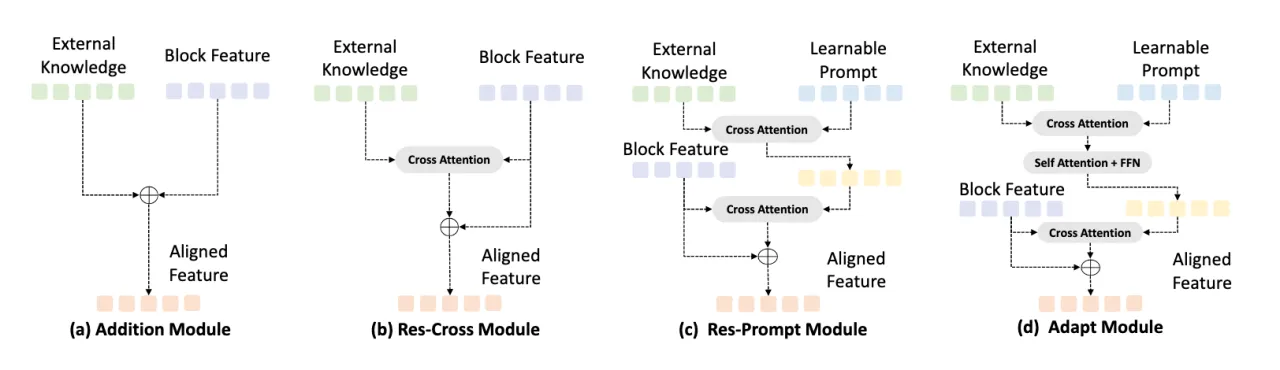
随后本文探索了四种融合结构来整合外部知识,之后实验结果也证明了Adapt Module的作用。
实验
Dataset
TinyVIRAT:真实世界低分辨率动作识别数据集,数据集中视频的分辨率从10到128像素不等,共26个分类,每个视频可以有多个标签。
ARID:针对暗光场景的动作识别的数据集,由3780个视频片段组成,分为11个动作类。
QV-Pipe:城市地下水管道异常检测专用数据集,与普通分类数据集相比有显著的领域差异。共有17个类别,包括1个正常类和16个缺陷类。
Metrics
F1-Score(TinyVIRAT)
Top-1 Accuracy and Top-5 Accuracy(ARID)
mAP(QV-Pipe)
Result
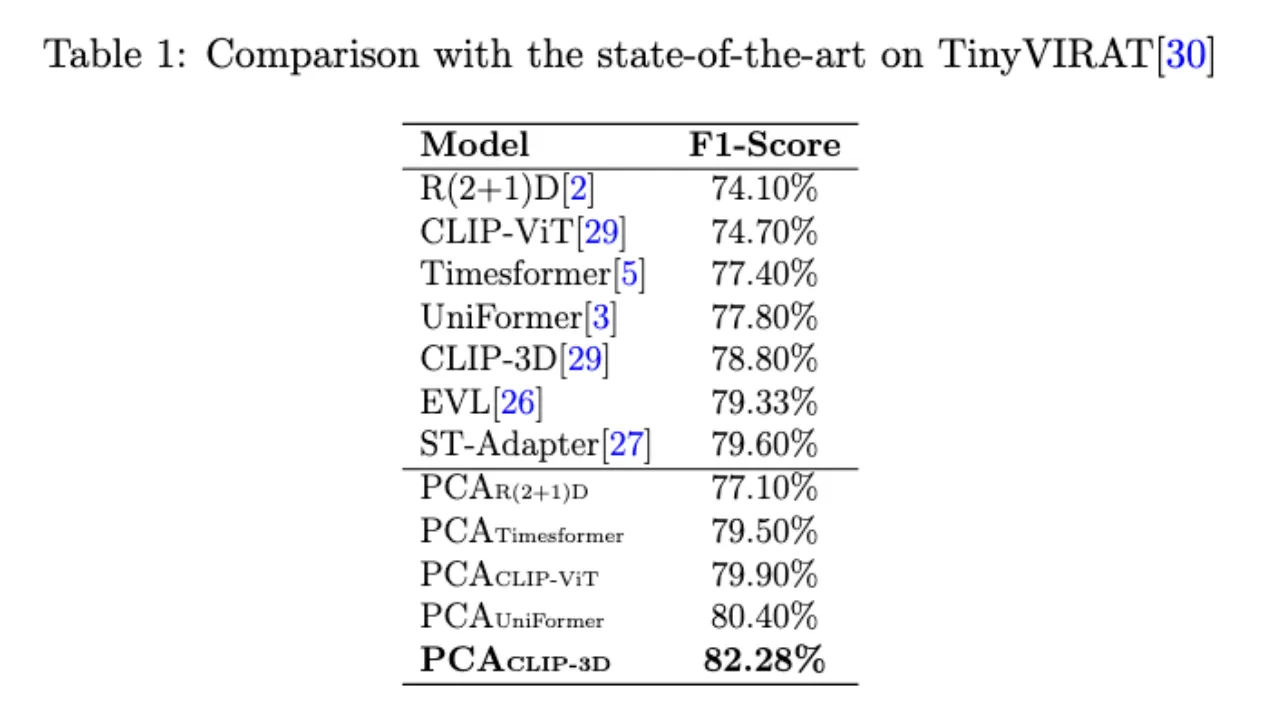
带adapter的model表现优于baseline,其中PCACLIP-3D 性能最好。
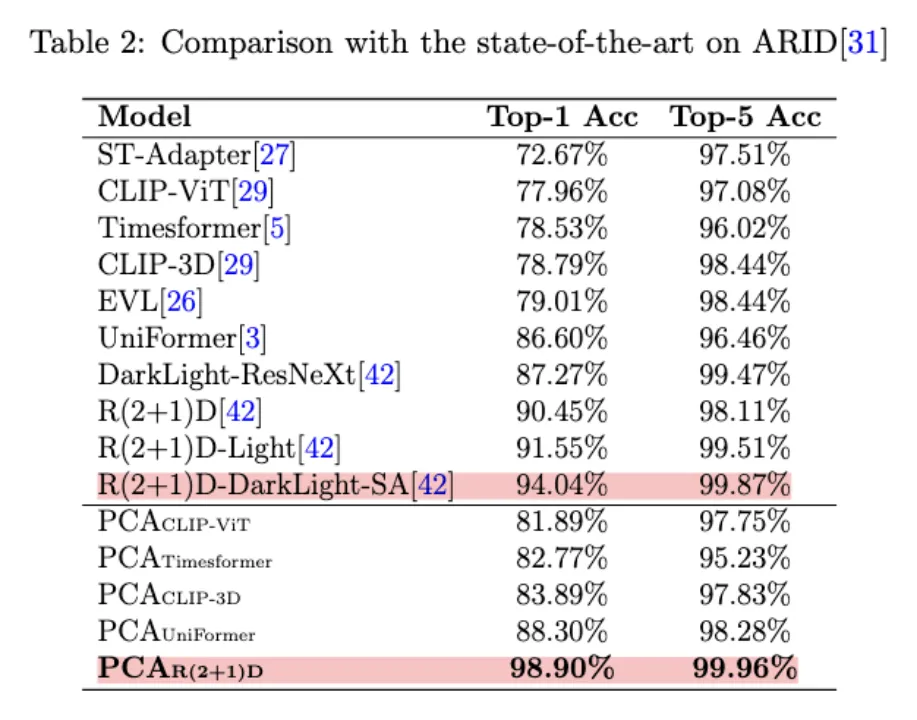
由于视频数量有限,使用transformer模型会过拟合,这使得带有transformer组件的模型性能比使用CNN组件的模型差一些。
R(2+1)D模型创新的双路径结构和自注意力机制,以及其对低光照条件的特别适应性使得其取得baseline模型中最好的效果。
在PCA的作用下,所有对应baseline模型的性能均有提升,其中PCAR(2+1)D 取得最好的效果。
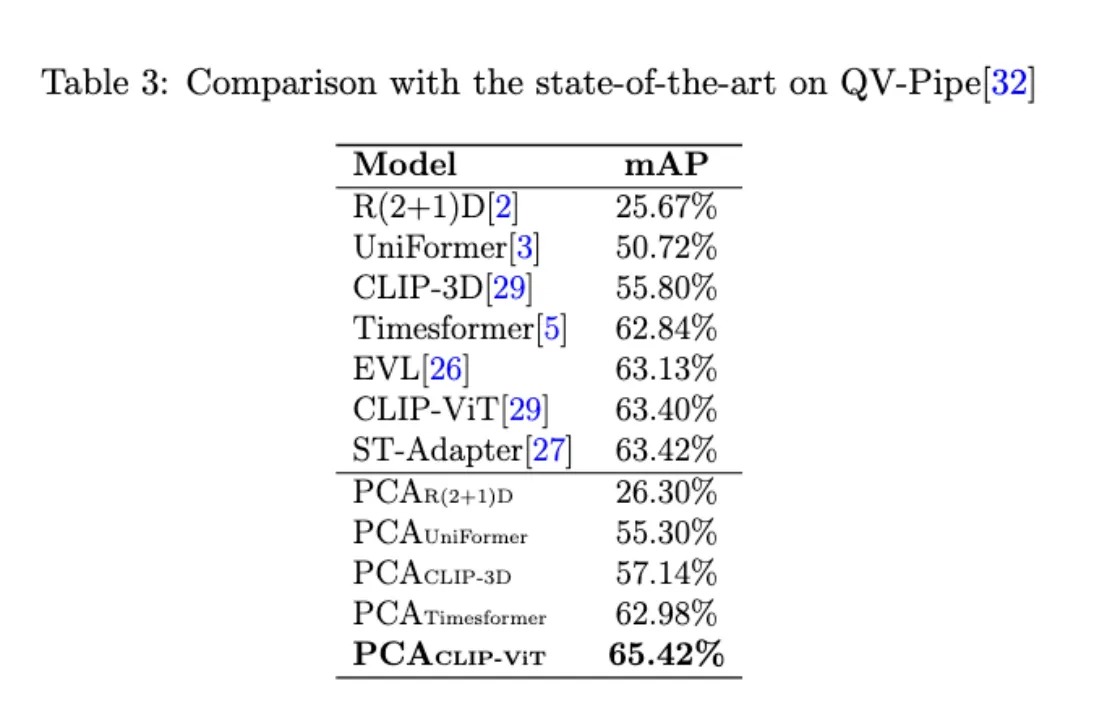
纯卷积网络集成全局信息的能力有限,不能很好地泛化,故比基于Transformer的模型效果要差。
Ablation Study
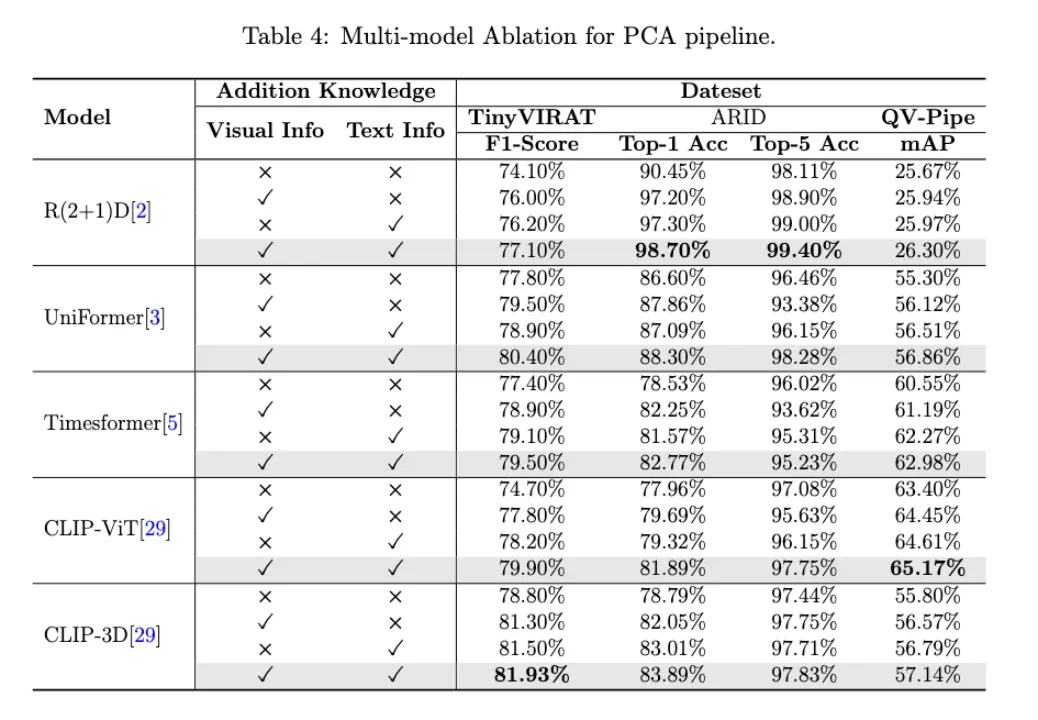
实验结果表明无论是文本形式还是视觉形式的外部知识,都对提高模型的准确性有积极的影响。并且视觉知识和文本知识的结合进一步提高了模型的性能。
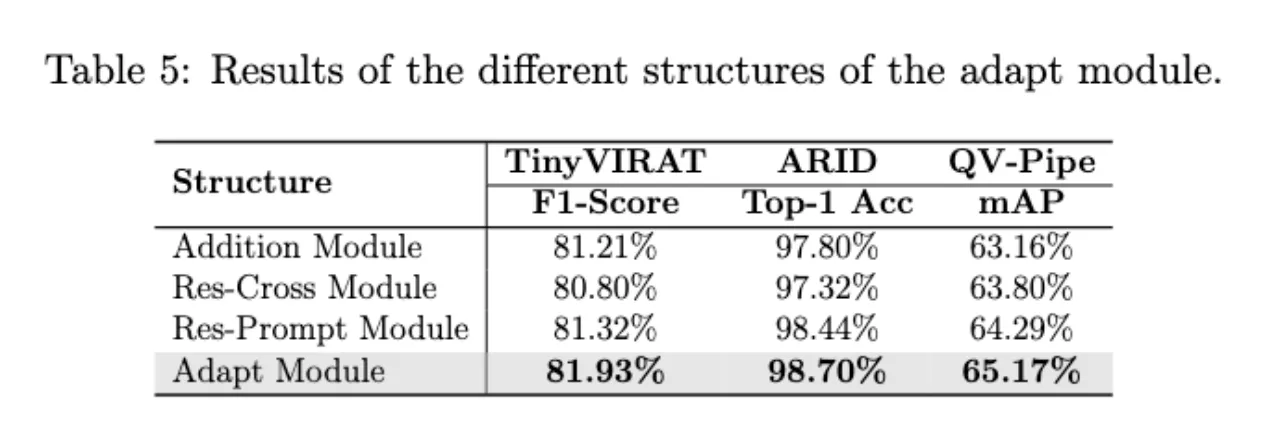
Res-Prompt Module增加了一个基于ResCross的可学习查询,进一步提升了性能,表明可学习查询可以帮助集成外部信息。 使用ResCross的可学习查询和Self-Attention+FFN的Adapt Module取得了最好的效果。
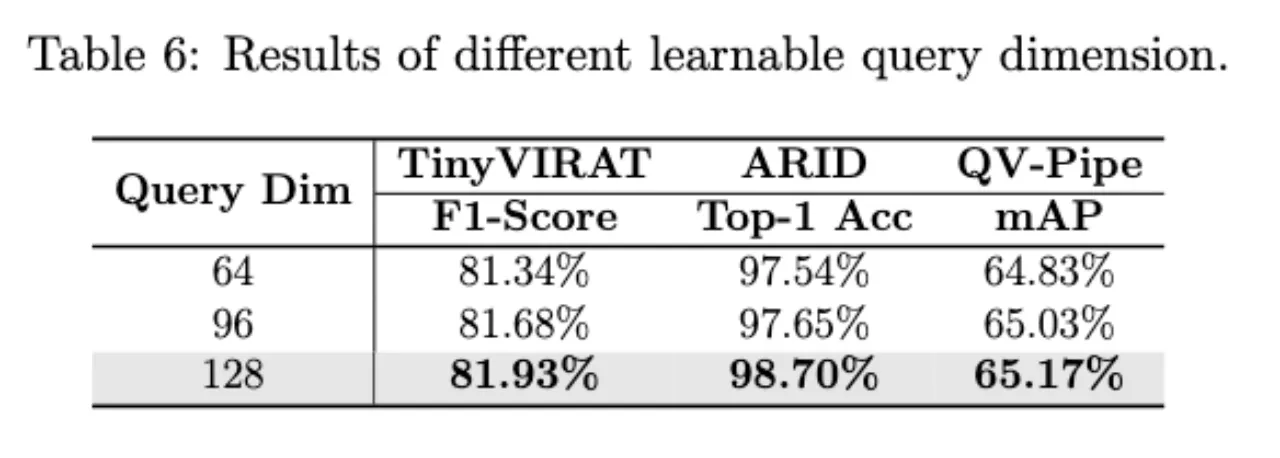
随着提示查询维数的增加,模型的性能也略有提高,选择128维以平衡计算成本和性能。
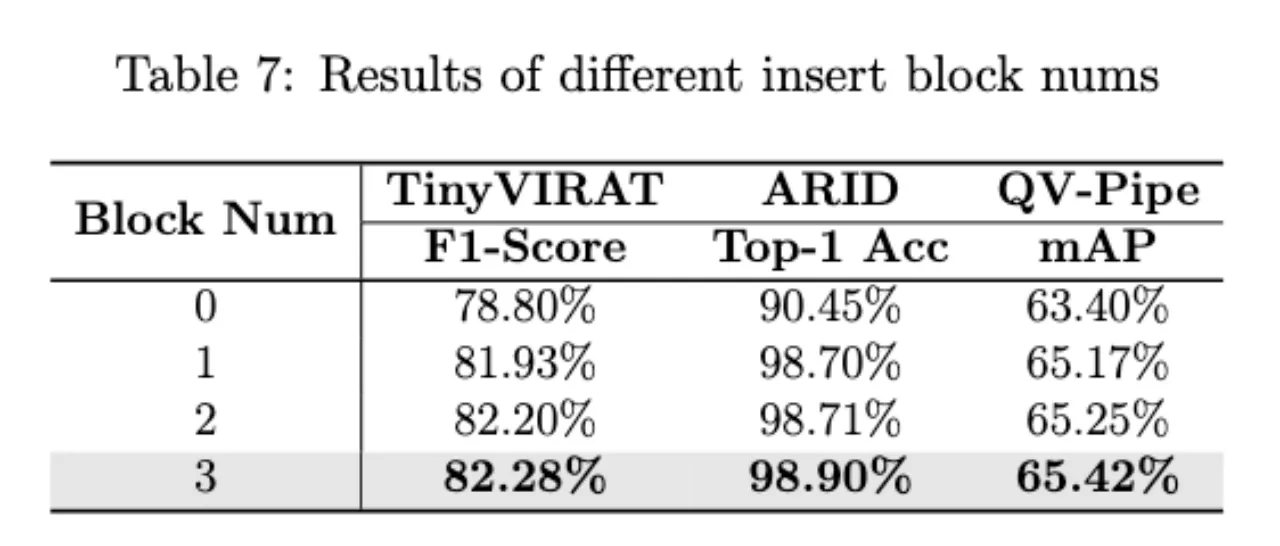
Block Num=3在三个数据集上的效果最好。随着插入块数量的增加,结果有所改善。
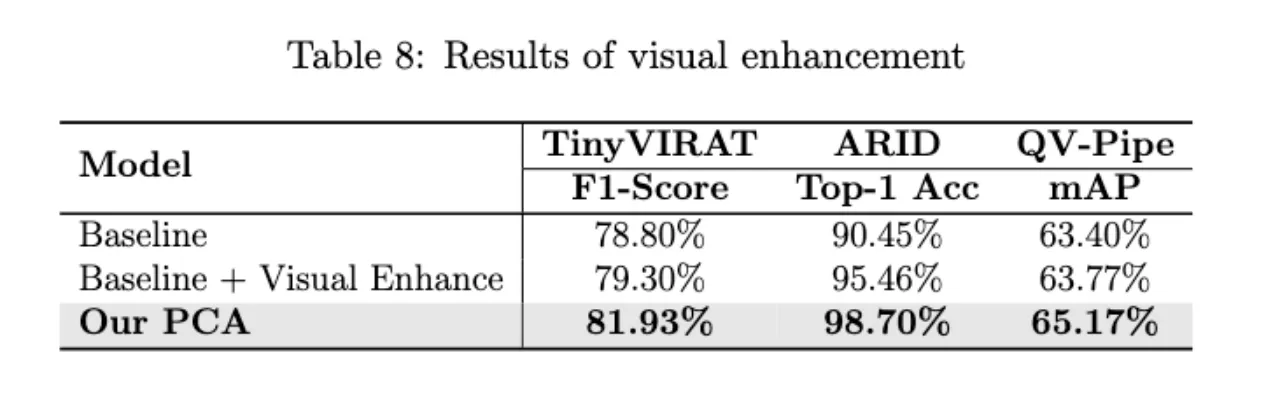
在PCA中引入视觉单模态知识进一步提高了性能,而整合视觉和文本知识使网络获得更好的结果。
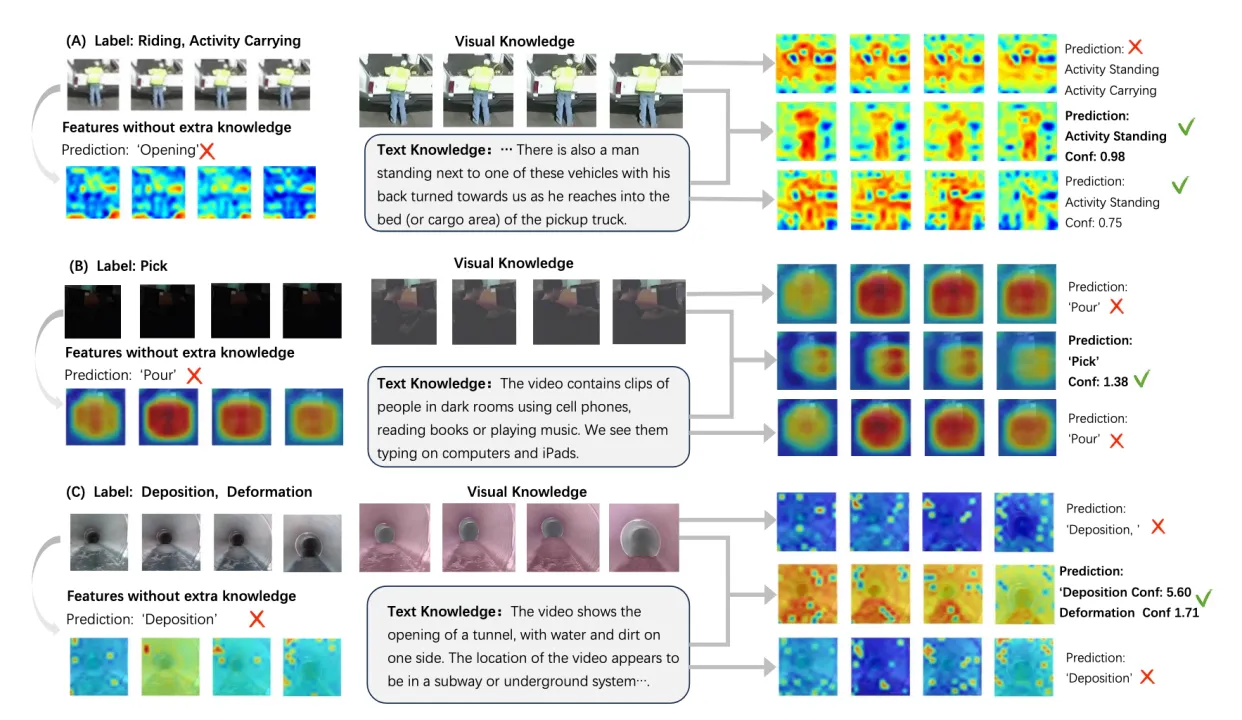
Attention Visualization
总结
提出了通用知识转移框架PCA,通过Percept(感知)、Chat(聊天)和Adapt(适应)三个阶段,从基础模型中挖掘各种External Knowledge(外部知识),提升开放世界视频识别的性能。
引入了一个即插即用的多模态知识适配模块,允许将PCA灵活地整合到各种视频骨干网络中,用于开放世界识别。
PCA在QV-Pipe排水管异常检测数据集上成为SOTA方法。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享