
Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors
编辑论文链接:https://ieeexplore.ieee.org/document/10655393
代码链接:https://github.com/ristea/aed-mae
这篇文章发表在CVPR 2024上
背景
异常事件通常是上下文依赖的,并且不经常发生,这使得收集足够代表性的异常事件样本以训练深度学习模型变得困难。
现有的异常点检测方法将异常检测作为离群值检测任务,在推理过程中对正常事件和异常事件分别应用一个经过正常事件训练的正态性模型,将偏离学习模型的事件标记为异常。
自动编码器(AE)模型对非分布数据的样本重建能力较差。由于训练只在正常的样本上进行,因此当出现异常时,预计AE会表现出很高的重建误差。
现有的SOTA方法依赖于昂贵的目标检测方法来提高精度,将处理带宽限制为每个GPU一个视频流,约为20-30 FPS,然而以对象为中心的视频异常探测器的处理成本太高。
动机
现有的异常检测方法,尤其是基于自编码器的方法,可能在重建异常事件时表现得太好,导致无法有效检测异常。
需要一种既快速又准确的模型,能够在实时视频流中检测异常事件。
提出lightweight teacher-student transformer-based masked AE(aed-mae)
Motion gradient weighting:引入基于运动梯度的权重来关注前景对象。
Self-distillation:结合了教师解码器和学生解码器,利用两者输出之间的差异来提高异常检测的准确性。
Synthetic anomalies:通过在训练视频中加入合成的异常事件来增强训练数据。
Classification head:在模型中加入了一个分类头,用于区分正常和异常实例。
方法
Framework
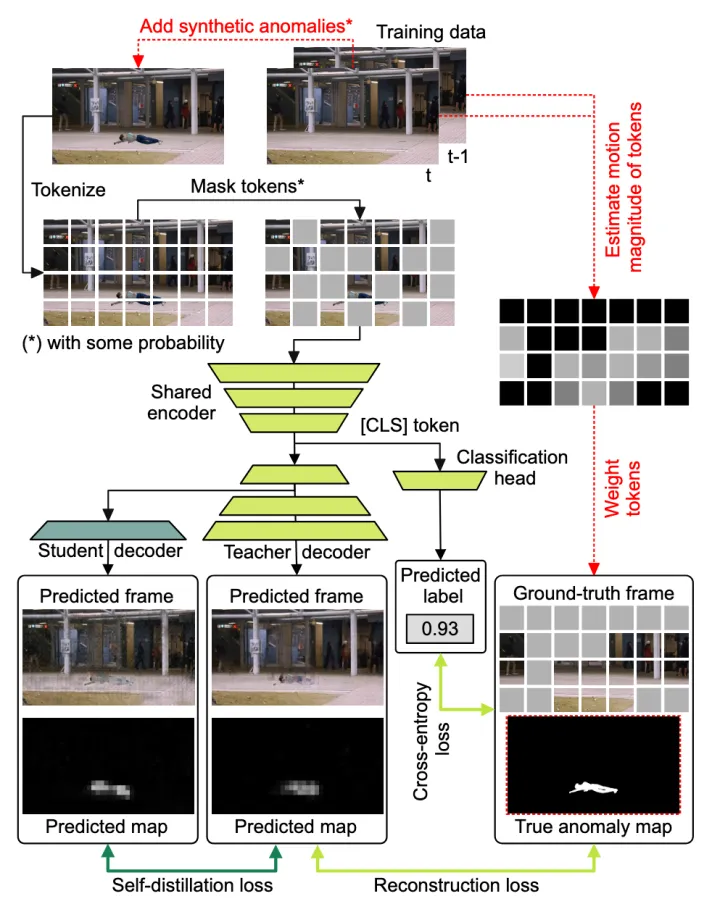
Motion gradient weighting
定义在视频的index t位置的frame为
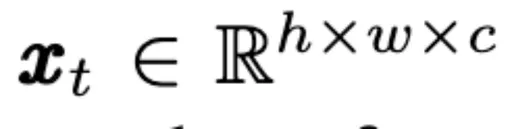
n是每一个frame xt非重叠的大小为d × d × c的visual tokens(patchs)数量。 定义
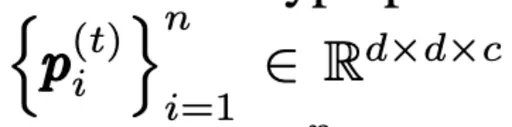
代表frame xt 中的tokens序列,定义
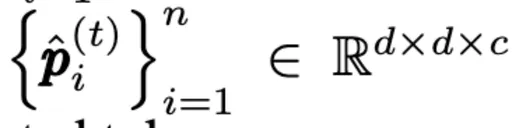
代表对应的重建tokens序列。
通过比较连续帧之间的绝对差来估计 frame xt 对应的运动梯度图motion gradient map gt。 随后将gt进行划分得到gradient patchs
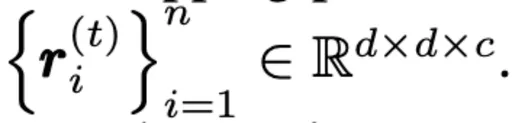
对于每一个gradient patch计算最大梯度值上的通道均值
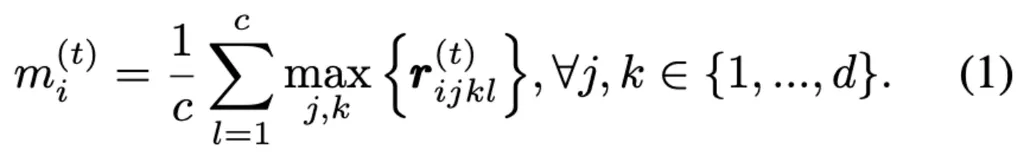
最后计算重建损失的token-wise weights
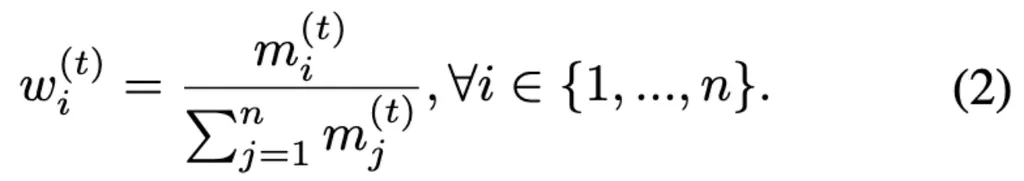
将得到的权重w引入到传统的token-level的重构损失中,可以推动masked AE专注于重构高运动幅度的patchs。 通过加权均方误差损失进行优化:
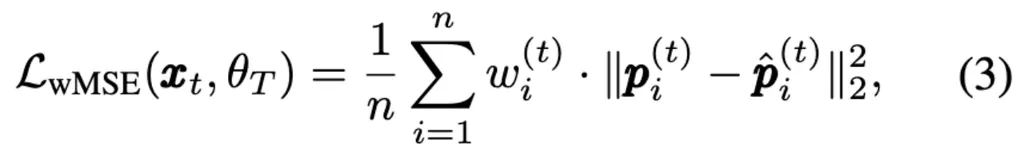
其中θT是teacher masked AE的权重。
Self-distillation
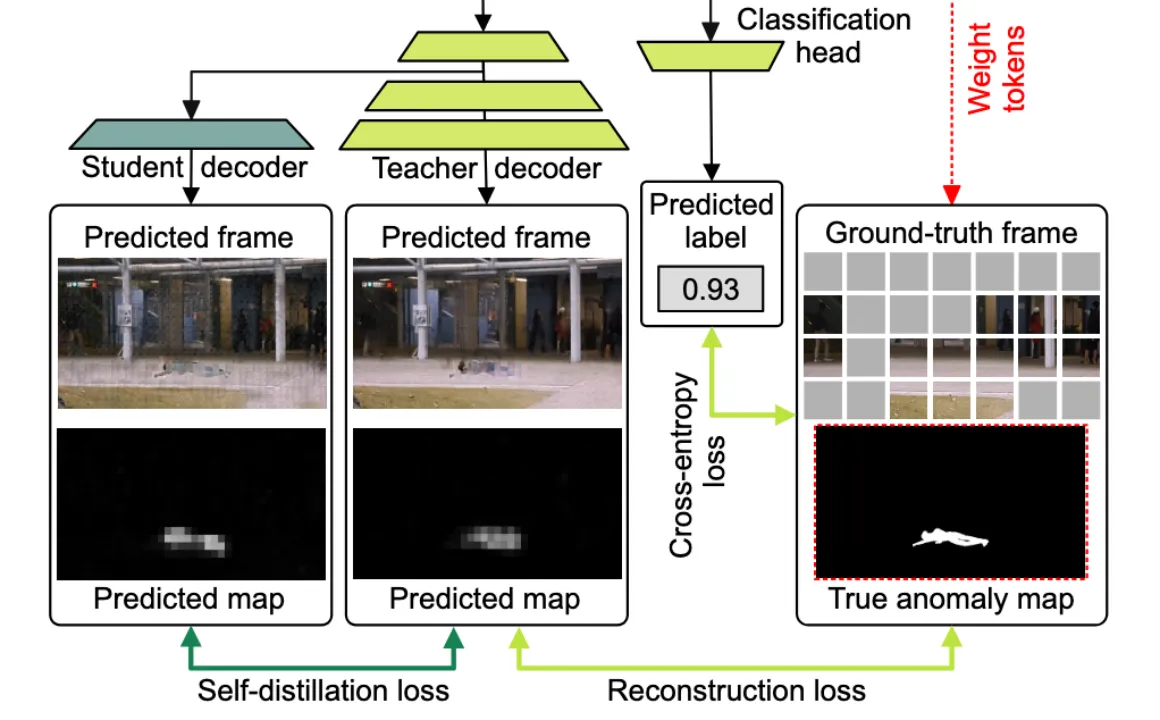
提出一种新型的self-distillation,有一个shared encoder和两个decoder,一个teacher和一个stduent。在teacher decoder的第一个transformer block之后,student从原始架构中分支出来,实际上只添加了一个transformer block。
训练过程分为两个stage:
教师网络使用重建损失进行优化
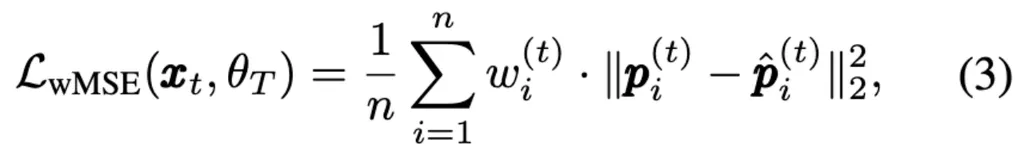
冻结shared backbone的参数,只通过self-distillation训练学生网络,学生网络使用自蒸馏损失进行优化
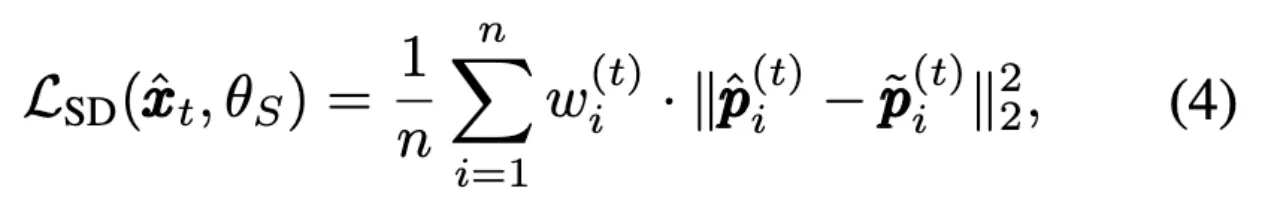
其中$\hat{x}_t$代表由教师网络重建出的视频帧(Predicted frame),w与之前保持一致。
Synthetic anomalies

利用UBnormal数据集及其精确的像素级注释来裁剪异常事件并将其混合在训练视频中,实现了数据增强。 合成异常具有三个优点:
在重建损失中考虑原始训练帧(没有叠加异常)作为gt,本质上迫使模型忽略异常。
将异常图添加为图像的附加通道。正常像素设置为0,异常像素设置为1。
使用gt anomaly map来增强权重。添加的合成异常不一定产生高量级的motion gradient。
但这样异常区域的patchs对应的weights可能也会比较低,这对于异常检测来说是不利的。
将 anomaly maps也加入到weights的计算过程中,将
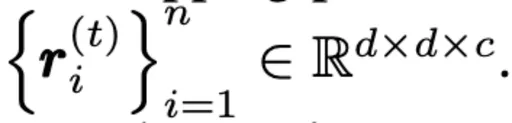
替换为
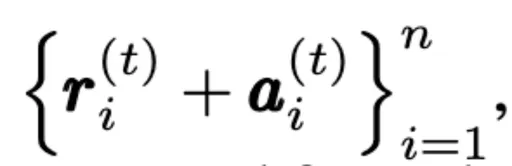
其中ai是从anomaly map中提取的patches的集合。
也就是说通过加入anomaly maps中有关于异常的patchs,使得masked AE专注于重构高运动幅度的patchs,而不会因为合成异常固有的特性降低模型进行异常检测的性能。
Classification head & Inference
Head用来区分当前视频帧中是否存在合成异常。使用binary cross-entropy对Head进行优化
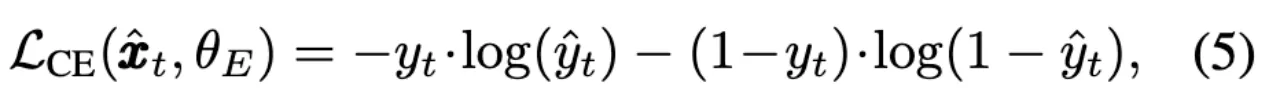
在推理过程中,将每一帧xt分别通过教师模型和学生模型,得到重构的帧$\hat{x_t}和\tilde{x_t}$.
计算像素级别的anomaly map

取每一个像素级别的anomaly map的最大值后,使用另一个时间高斯滤波器得到平滑后的帧级别的anomaly score值。
实验
Datasets
Avenue:一个流行的Benchmark,包含15K帧用于训练和另外15K帧用于测试。
ShanghaiTech:最大的数据集,有27万帧用于训练,约5万帧用于测试。
UCSD Ped2:共4.5K帧,其中2.5K用于训练。
UBnormal:第二大数据集,大约有116K个训练帧和93K个测试帧,其中训练和测试异常属于不相交的类别集,其他三个数据集中训练视频只包含正常事件,测试视频包含正常和异常场景。
Metrics
Micro AUC:通过对所有视频帧的标签和分数进行合并后计算得到的,这种方式关注的是整体的二分类性能,不区分不同视频之间的差异。
Macro AUC:通过分别计算每个视频的 AUC,然后取平均值得到的,这种方式关注的是每个视频的性能,并且对每个视频赋予相同的权重。
Result
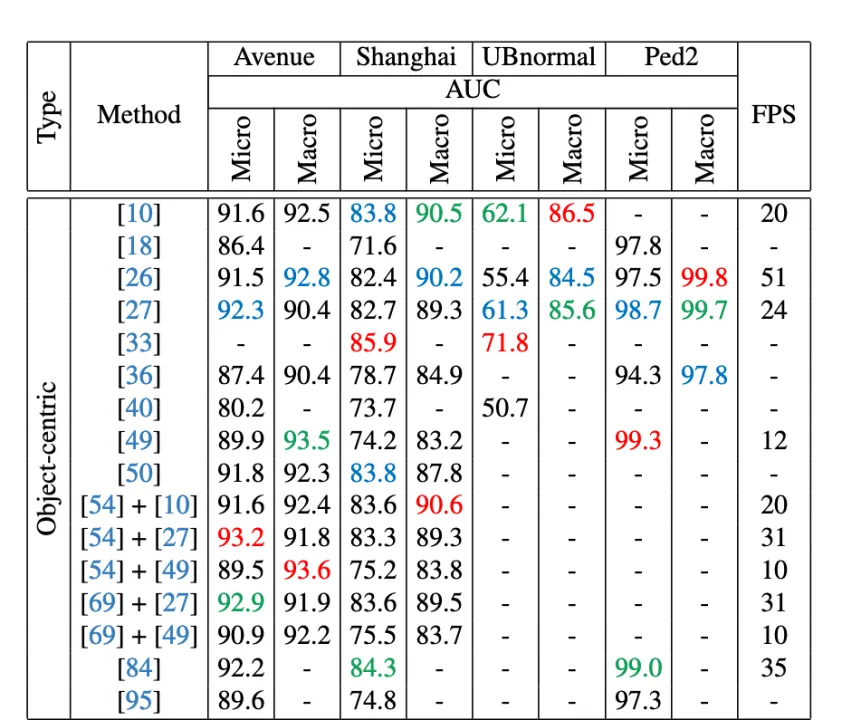
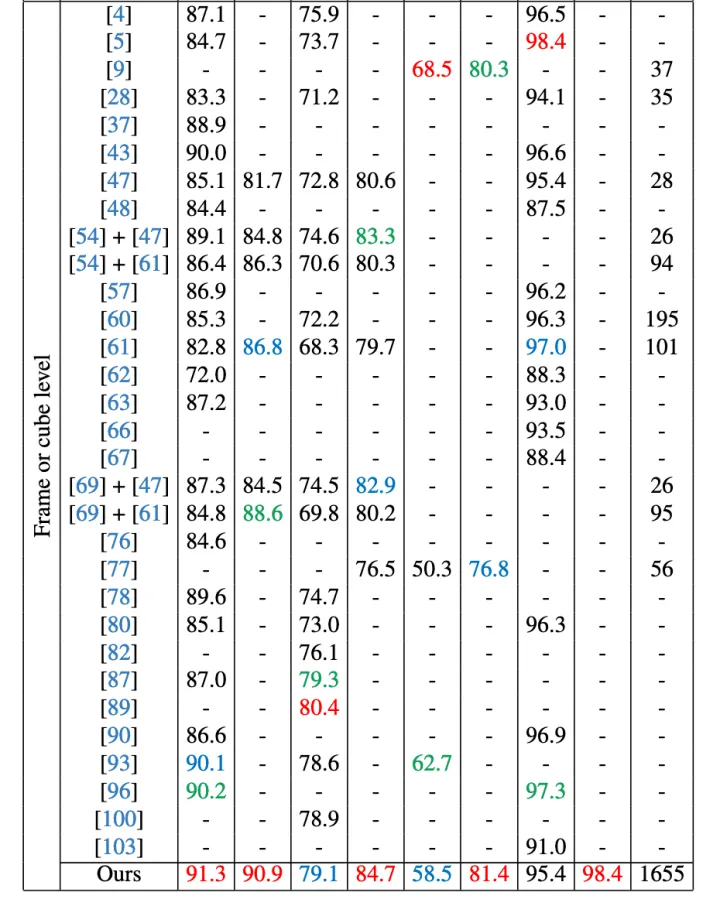
前三名分别以红色、绿色、蓝色标注
Ablation Study
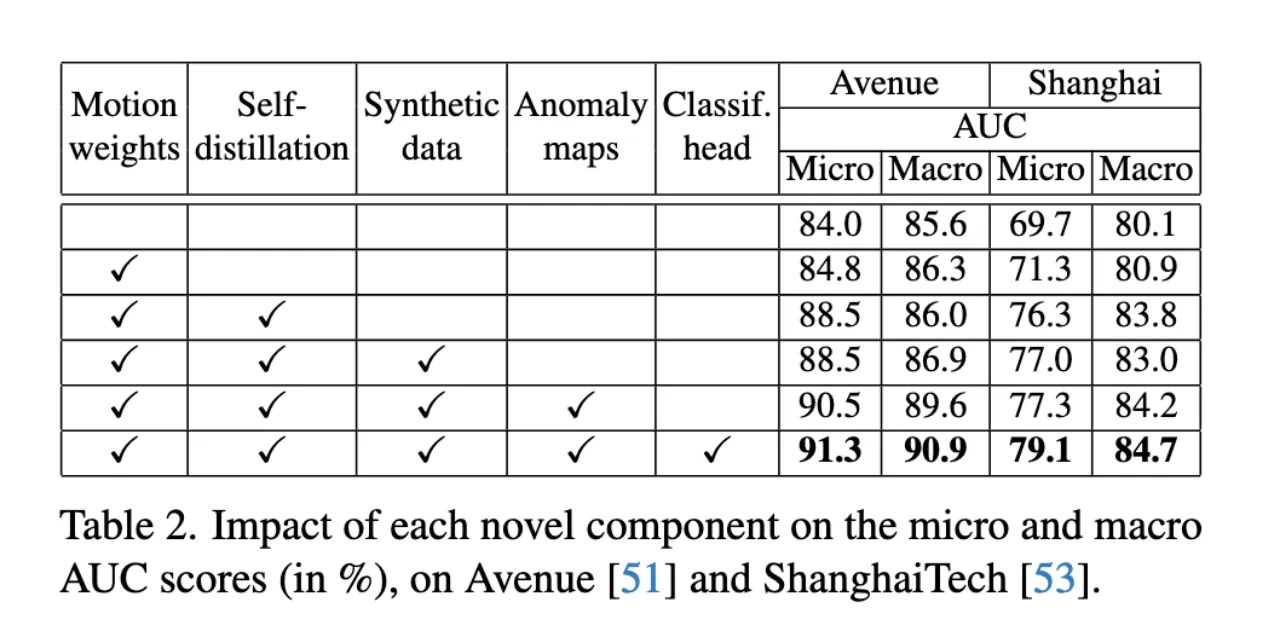
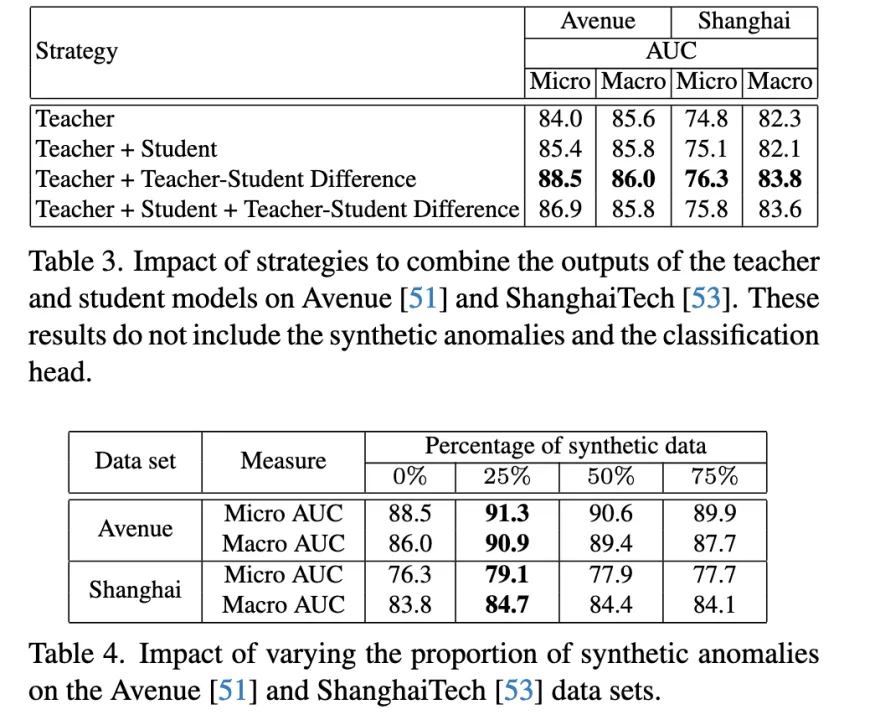
Table2验证了引入新组件带来的性能提升。 Table3表明当教师重构误差与师生差异相结合时,可以得到最佳的micro AUC。 Table4表明数据增强总是有用的,但需要适度的百分比(25%)。
Performance-speed trade-off
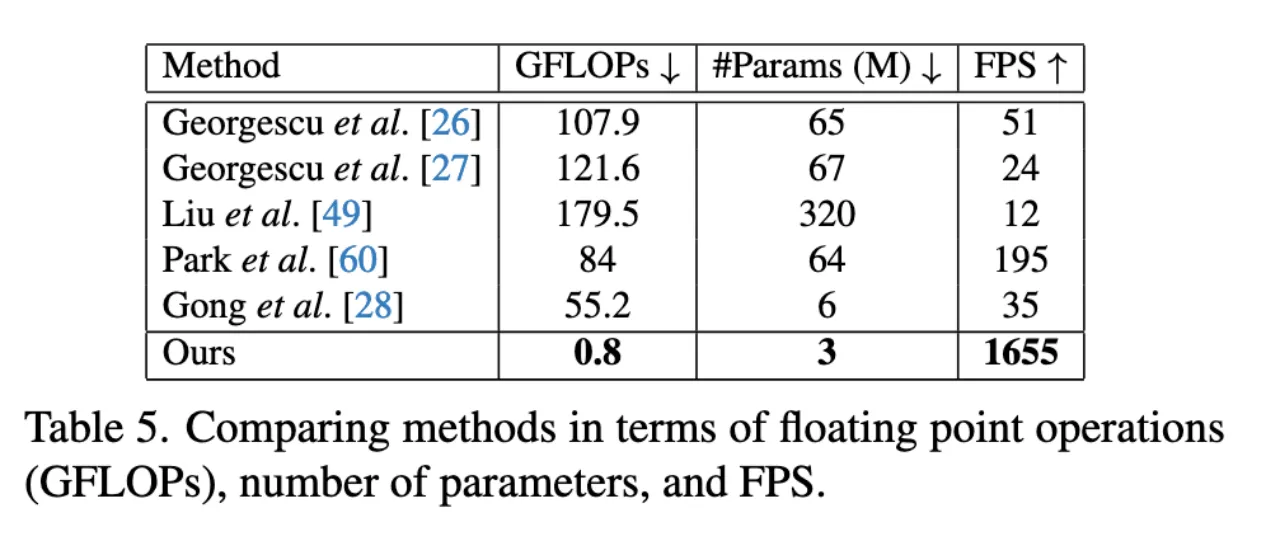
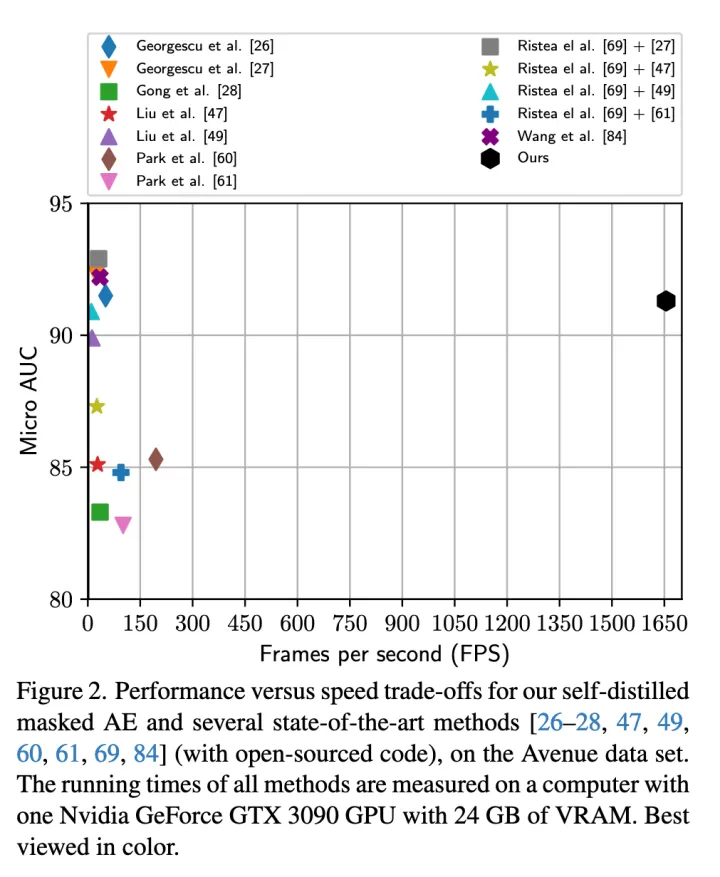
Figure2表明本文的方法在保持相对优异的性能下达到了更快的处理速度。 Table5表明本文的方法在FPS为1655的情况下,比所有竞争方法都要轻量得多。
Visualization

总结
提出了一种用于视频异常检测的轻量级掩码自编码器(3M参数,0.8 GFLOPs),该编码器学习重建具有高运动梯度的标记。基于自蒸馏,利用教师和学生解码器之间的差异进行异常检测。通过在正常训练数据上引入基于重叠合成异常的数据增强技术来提高模型的性能。
框架达到了前所未有的1655 FPS的速度,与最先进的以对象为中心的方法相比,性能差距很小,在现实世界的视频异常检测具有应用前景。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享