
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
编辑论文链接:https://arxiv.org/pdf/2404.05726
代码链接:https://github.com/boheumd/MA-LMM
背景
随着视频内容的爆炸性增长,对长期视频数据进行有效理解变得愈发重要,这涉及到对视频内容中的时间动态和上下文信息的深入分析。
为了处理视频数据中的时间跨度和上下文信息,需要模型具备记忆和回忆关键信息的能力,这对于长期视频理解尤为重要。
通过将LLM与视觉编码器集成,可以将图像和视频作为输入,并在各种视觉理解任务(字幕生成、问答、分类、检测和分割)中显示出强大的能力。
动机
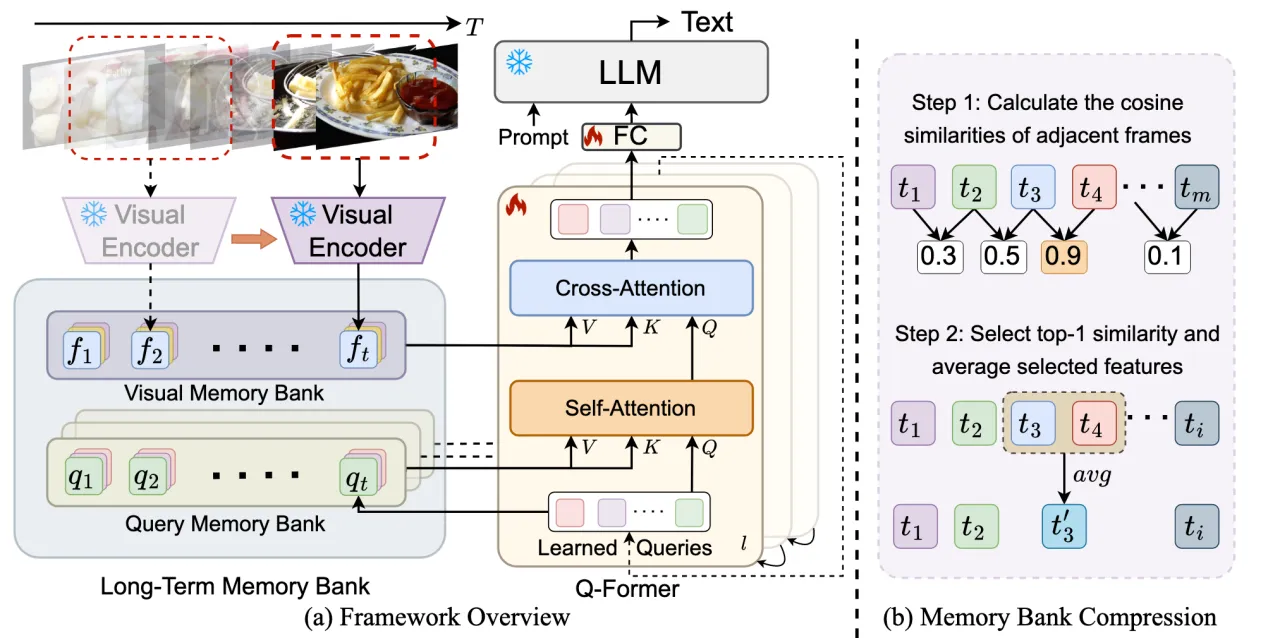
现有的基于LLM的多模态模型只能在有限的帧中理解短视频,这些模型大多直接将每帧沿时间轴连接的查询嵌入馈送到llm中,llm固有的上下文长度限制和GPU内存消耗限制了可以处理的视频帧的数量,这使得这些模型无法对长视频(>=30 sec)进行理解。 提出Memory-Augmented Large Multimodal Model (MA-LMM)
Visual Encoder:按照时间序列提取视频帧的特征,并存入Visual Memory Bank。
Long-Term Memory Bank:记忆库以自动回归的方式聚合过去的视频特征,可在随后的视频序列处理期间引用。
Querying Transformer:将visual features、query和learned queries做自(交叉)注意力操作对齐视觉和文本嵌入空间,输出对应图像的tokens。
Large Language Model:通过tokens与prompt得到对应video的text描述。
方法
Framework
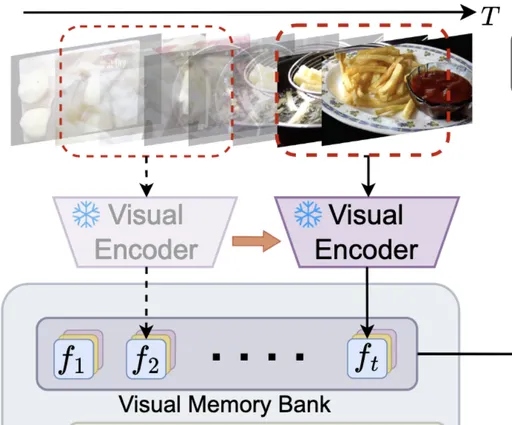
Visual Feature Extraction
在线方式自动回归处理视频帧
MA-LMM按顺序处理视频帧,动态地将新帧输入与存储在长期记忆库中的历史数据相关联,确保仅保留判别信息供以后使用。 给出由T个视频帧组成的序列,通过pretrained的visual encoder得到各个frame对应的visual feature
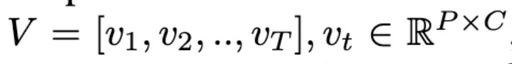
其中P代表patch的数量,C代表图像的channel数量
随后通过位置嵌入层(pe)将时序信息注入帧级特征
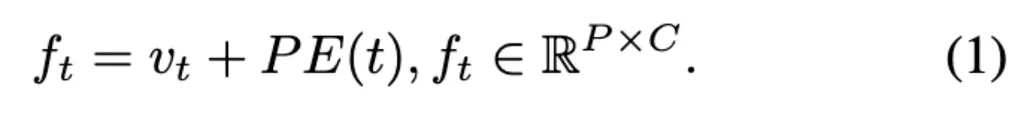
Long-term Temporal Modeling
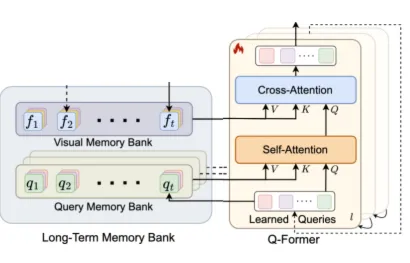
将视觉嵌入对齐到文本嵌入空间
Q-Former采用Learned Queries来捕获视频时间信息,Q-Former为每张图像输出32个tokens用于LLM的输入。
一个Q-Former块包含两个子模块:
Cross-Attention Layer与raw visual embedding(f)交互
Self-Attention Layer与input queries(q)交互
由Visual Memory Bank和Query Memory Bank组成的Long-Term Memory Bank积累过往视频信息,并将输入增强到交叉和自注意层,实现有效的长时视频理解。
Visual Memory Bank
视觉记忆库存储从冻结的视觉编码器中提取的每帧的原始视觉特征。
对于任意timestep t 都有
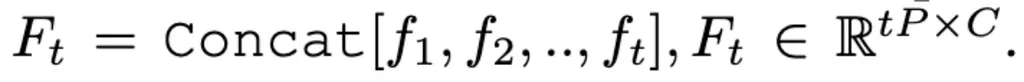
给定input query zt ,visual memory bank的值为
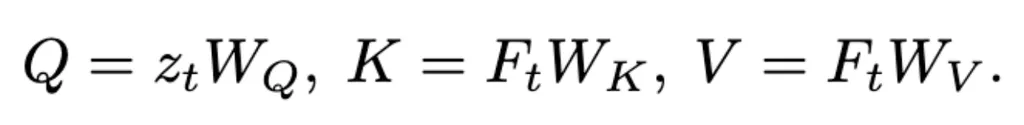
随后使用cross-attention操作:
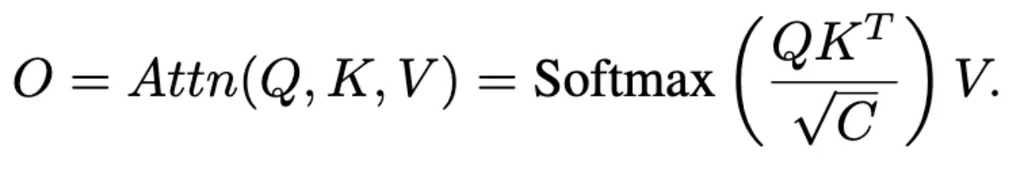
对缓存的具有长期上下文的视觉记忆库使用交叉注意力以关注过去的视觉信息,提升模型对于长视频的理解能力。所有交叉注意层都关注相同的视觉特征,因此只有一个视觉记忆库在所有Q-Former块之间共享。
Query Memory Bank
查询存储库累积每个时间步的输入查询。
输入查询被表示为
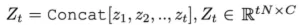
通过Q-Former保持模型对每帧的理解和处理的动态记忆,直到当前时间步长。
query memory bank的值为
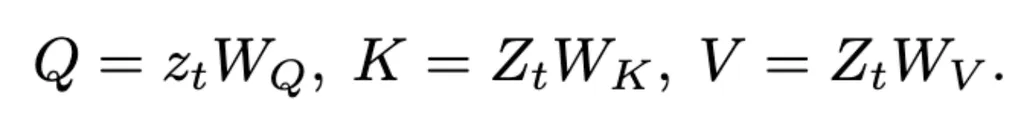
随后使用self-attention操作:
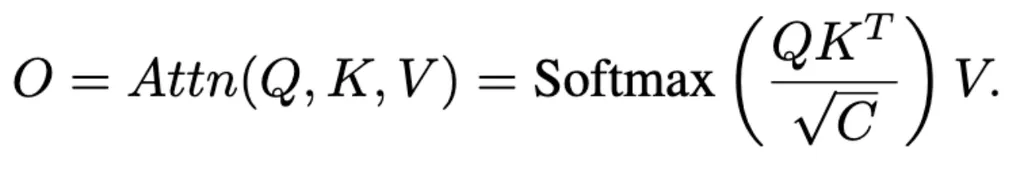
在模型训练期间,输入查询zt通过级联的Q-Former块进化,在不断增加的抽象级别上捕获不同的视频概念和模式。每个自注意层都有一个唯一的查询记忆库,其中包含的输入查询在训练期间不断更新。
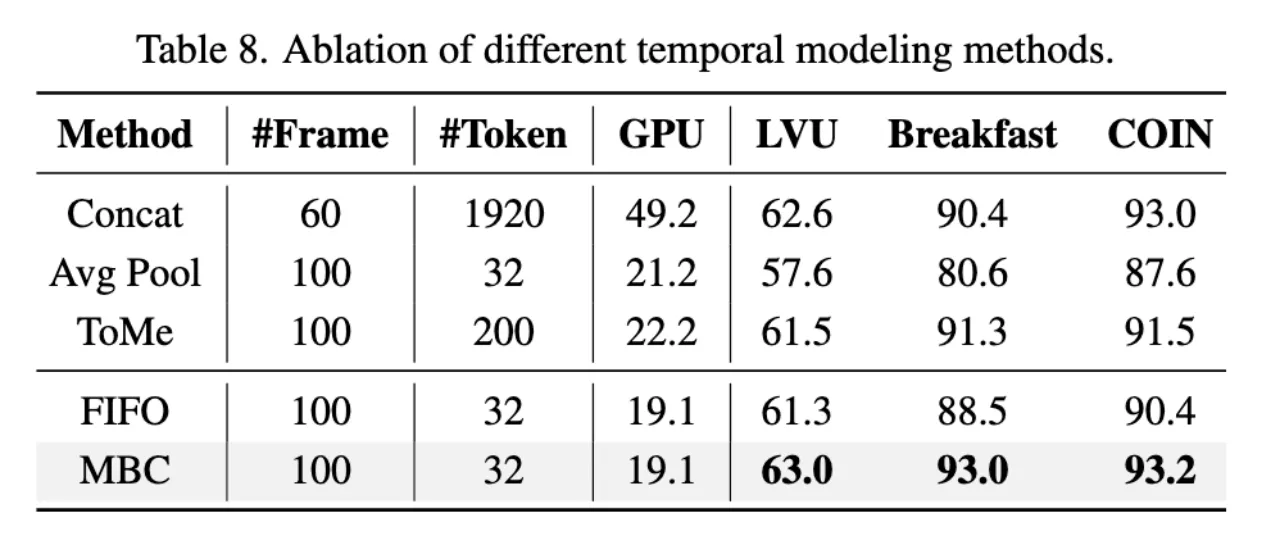
Memory Bank Compression
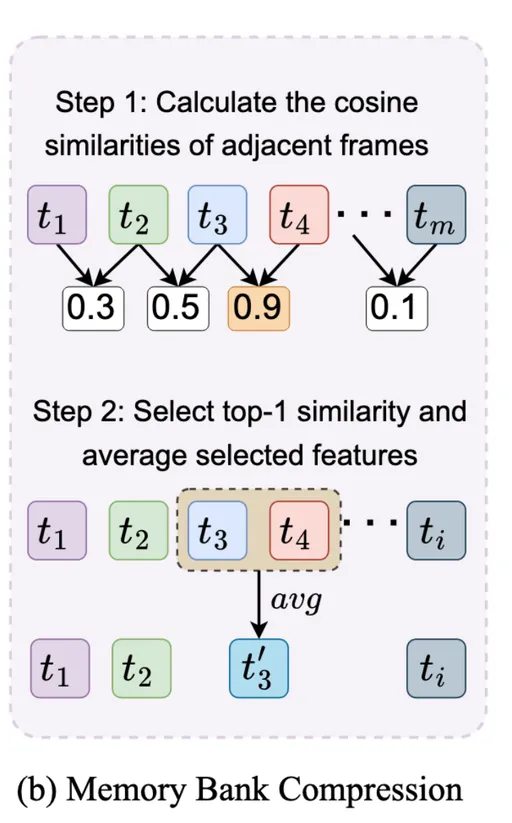
提出memory bank compression(MBC)技术,在保留早期历史信息的同时,根据相邻特征的相似性对视频信息进行聚合和压缩。 给定一个visual memory bank
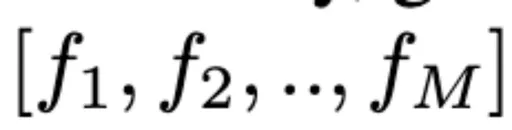
,当一个新的frame feature
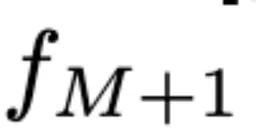
到来后,对于每个空间位置 i,计算所有时间相邻tokens之间的余弦相似度
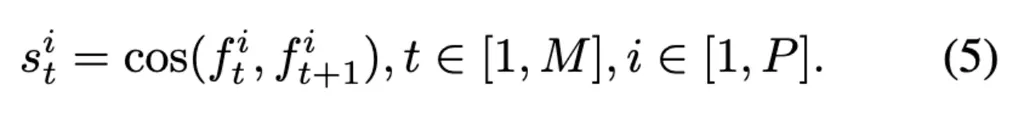
随后选择最高相似性的时间,理解为时间上最冗余的特征。
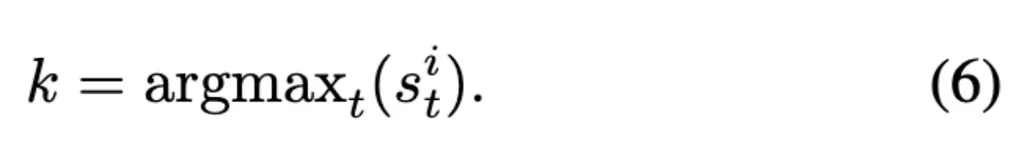
最后简单地在所有空间位置上平均所选的token features,以将memory bank长度减少1。
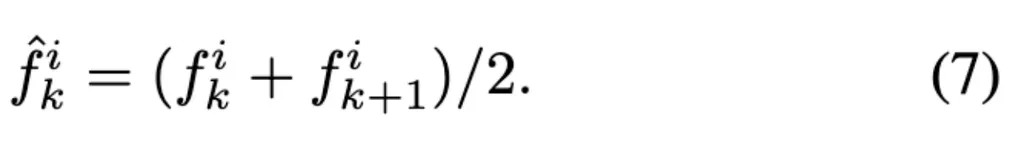
Text Decoding
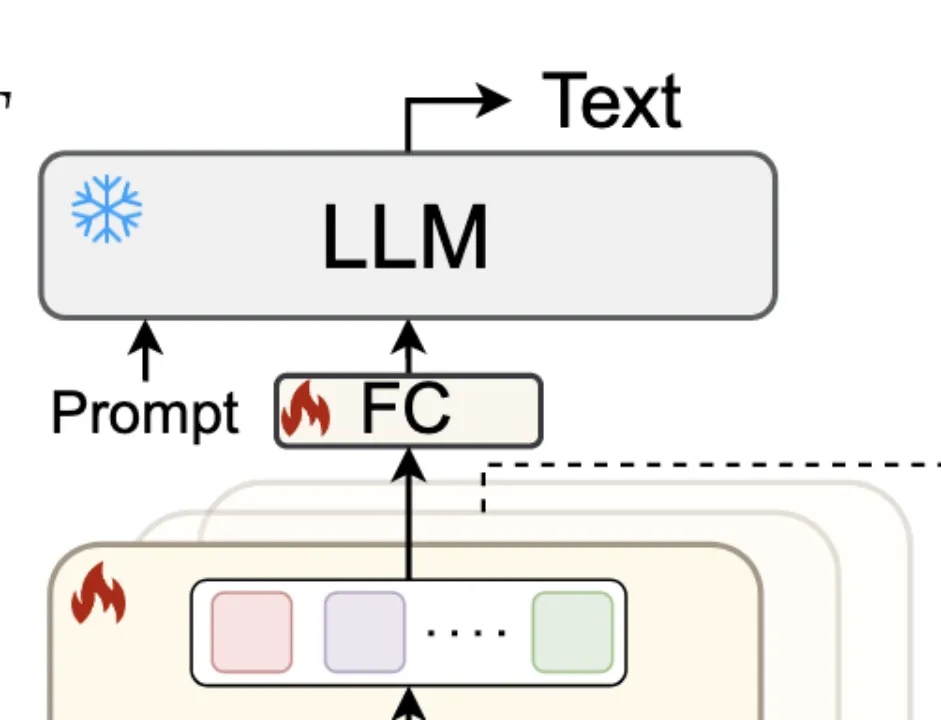
解析具有历史信息的空间特征以得到文本
Q-Former在最后时间步长的输出包含所有历史信息,然后将其输入LLM,通过这种方式将input text tokens的数量从N * T减少到N。 在训练过程中,给出包含视频和文本对的带标签的数据集,通过标准交叉熵损失函数进行优化训练
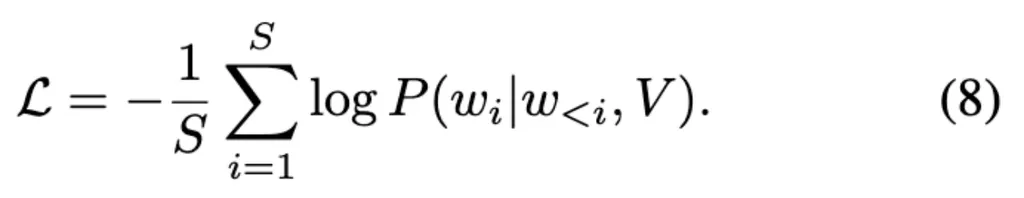
其中V代表输入的视频,wi 代表第i层的真实text token,同时在训练过程中冻结visual encoder和LLM的参数。
实验
Dataset
LVU、Breakfast、COIN(Video Understanding Task)
MSRVTT-QA、MSVD-QA、ActivityNetQA(Video Answering Task)
MSRVTT、MSVD、Youcook2(Video Captioning Task)
EpicKitchens-100(Online Action Prediction)
Metrics
Top-1 Accuracy(Video Understanding Task、Video Answering Task)
METEOR (M) and CIDEr (C)(Video Captioning Task)
Top-5 Accuracy and Top-5 Recall(Online Action Prediction)
Result
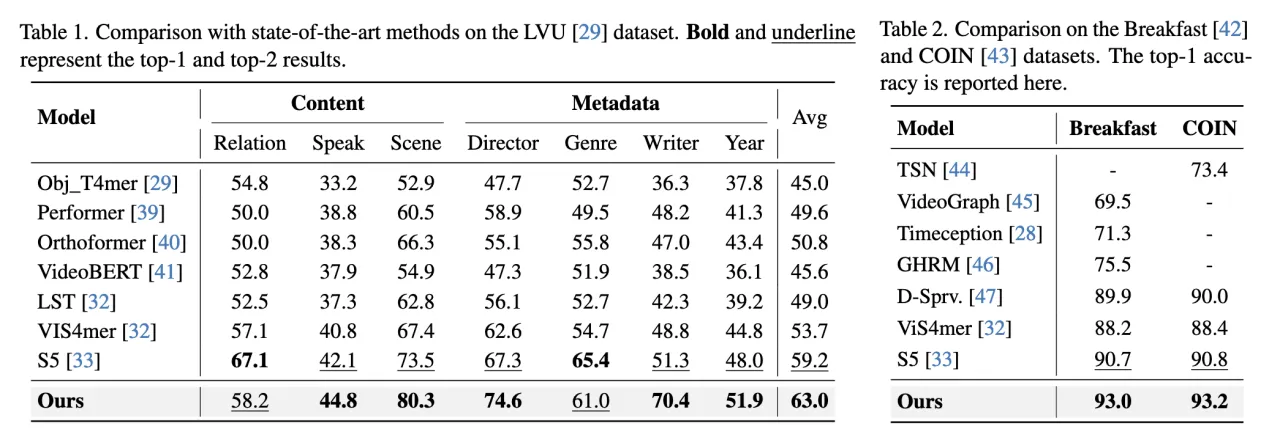
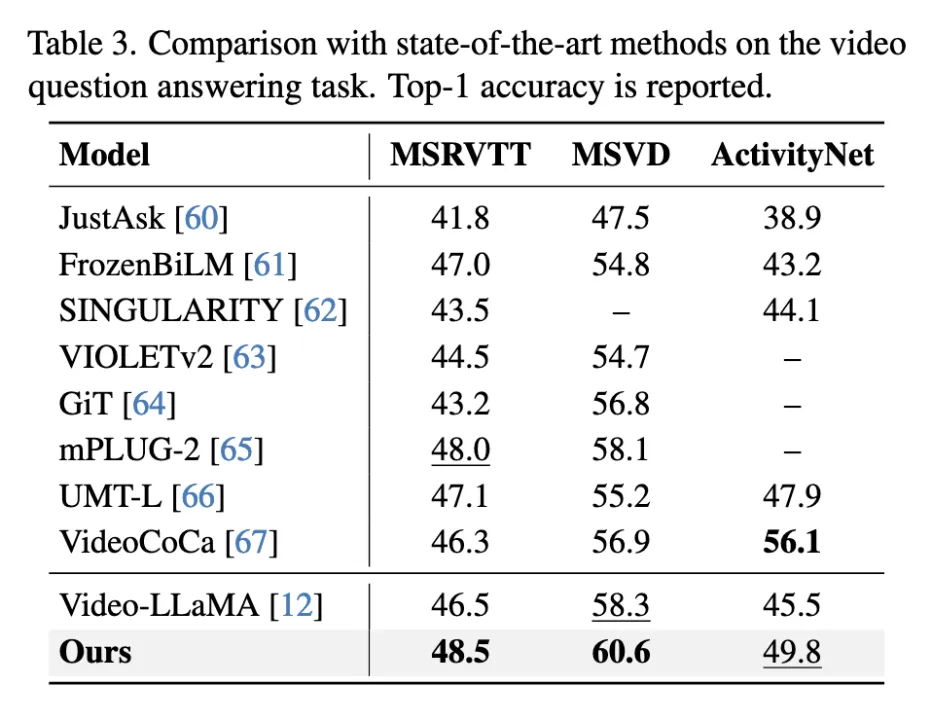
这些视频大多是短视频,memory bank的效果没有那么显著。VideoCoC利用大规模视频文本数据集进行预训练,MA-LMM只使用在图像文本数据集上预训练的模型权重,这是MA-LLM在ActivityNet数据集上不如VideoCoCa的原因。

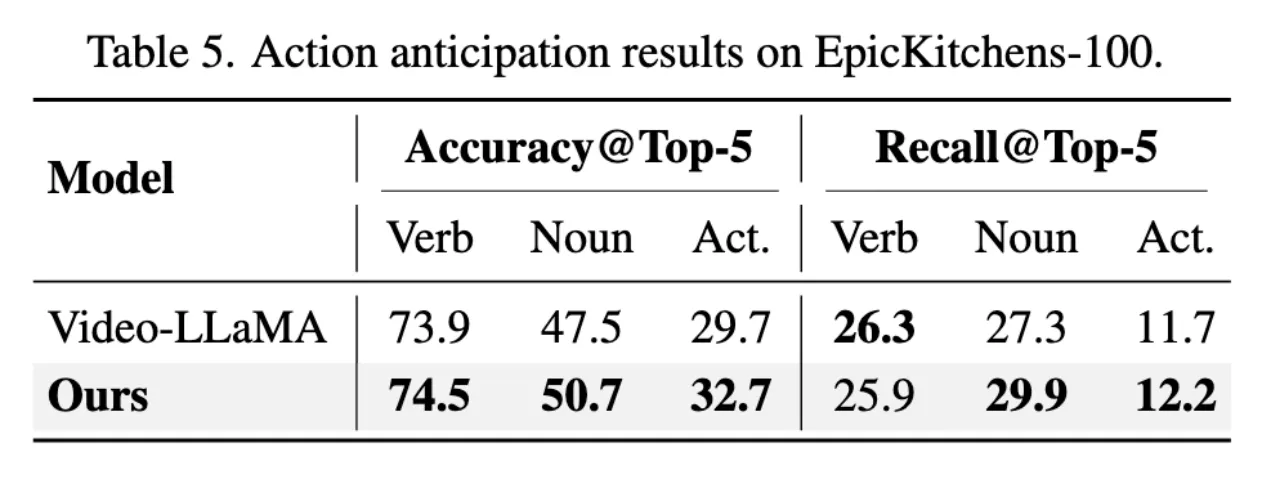
MA-LMM优于VideoLLaMA,在Top-5准确率和召回率方面都取得了更准确的结果。展示了模型对实时分析的突出能力。
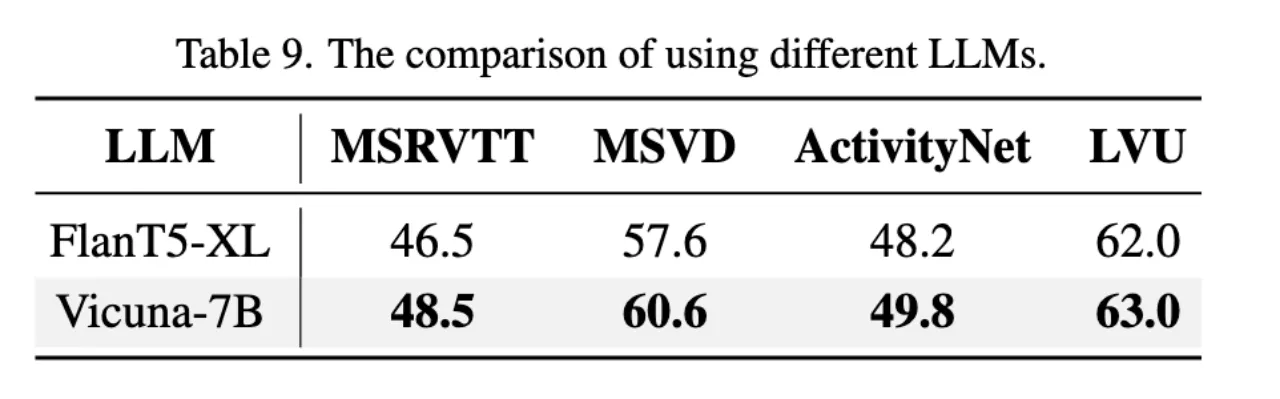
Ablation Study
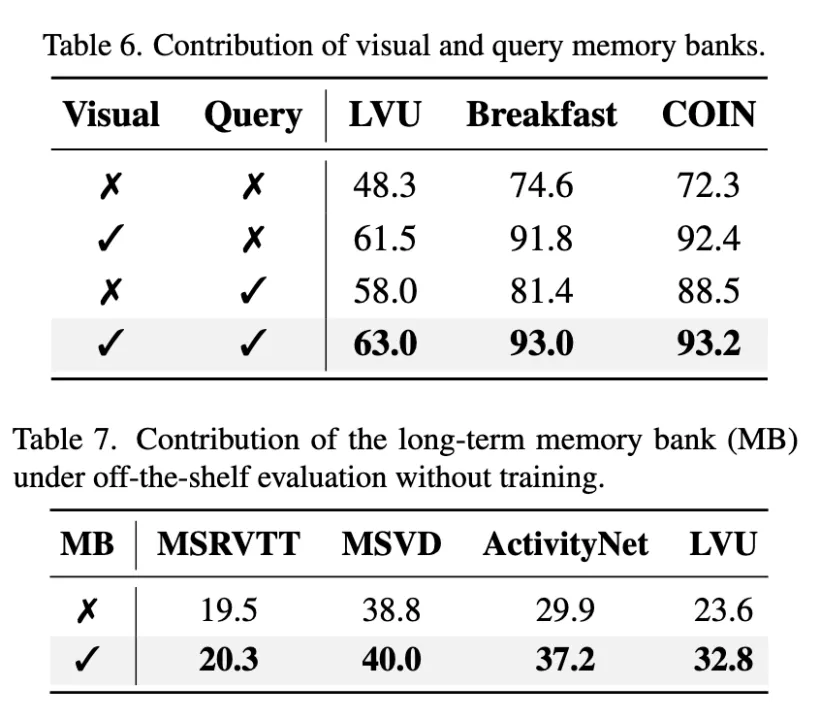
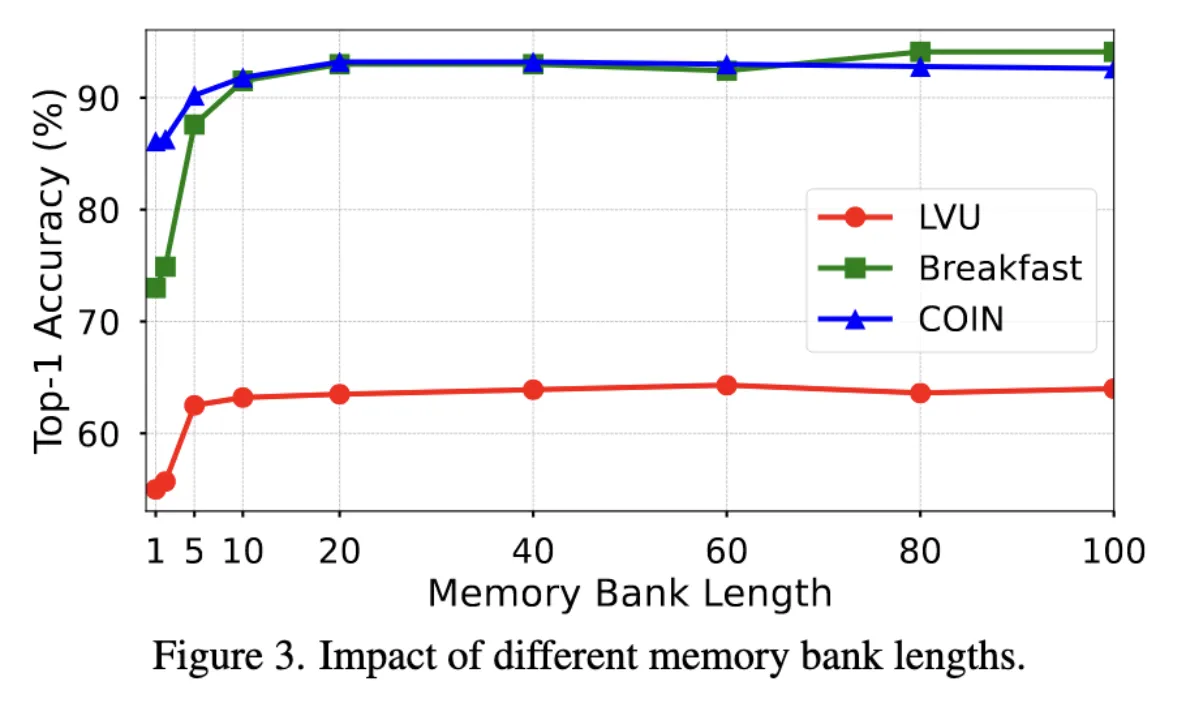
Visualization

总结
本文介绍了一个长期记忆库,旨在增强当前的大型多模态模型,使它们具有有效和高效地建模长期视频序列的能力。
MA-LMM按顺序处理视频帧,并将历史数据存储在内存库中,解决了llm的上下文长度限制和长视频输入带来的GPU内存限制。
长期记忆库是一个即插即用的模块,可以很容易地以现成的方式集成到现有的大型多模式模型中。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享