
DDP训练模型的数据加载问题(SSD Vs HDD)
编辑问题
目前在研究下水管缺陷多标签分类的相关内容,使用的是公开数据集Sewer-ML,该数据集共130万张照片,17类缺陷,占用存储300G。组内服务器有两个硬盘(1T的NVMe SSD和15T的HDD),目前我是将数据集存储到了HDD上。由于数据量很大,我使用DDP并行训练模型,但是在训练过程中我发现训练的剩余时间ETA不稳定,猜想应该是数据加载的问题。
排查过程
使用df -h查看当前服务器的硬盘列表,我的数据集文件存储在/data目录下,所以sda就是我提到的HDD。
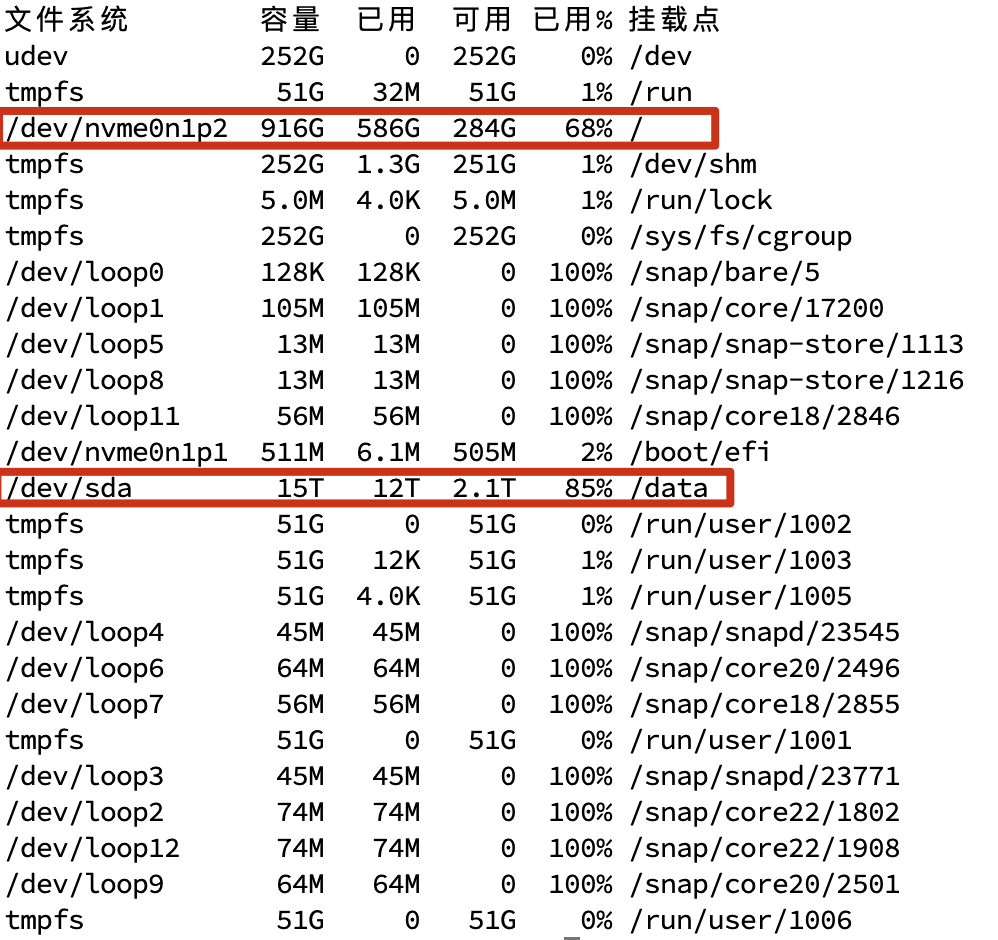
使用sudo hdparm -Tt /dev/sda测试HDD的顺序读取速度,由于我在拷贝数据,实际的读取速度应该在200MB/sec左右。

使用sudo hdparm -Tt /dev/nvme0n1p2测试SSD的顺序读取速度,由于我在拷贝数据,实际的读取速度应该在2000MB/sec左右。

可以看到二者之间存在十倍的读取速度的差距。
通过iostat -x 1可以实时查看磁盘的利用率,可以看到磁盘基本处于满负载(100%)的状态,会对训练过程产生很大的影响

原因分析
(1) 数据加载速度瓶颈
DDP的并行训练会同时启动多个进程(每个GPU一个进程),所有进程会并发读取数据。HDD的机械磁头无法同时响应多进程的随机读取请求,会导致严重的I/O阻塞(称为“磁头抖动”)。
SSD的并行性(多通道NAND闪存)能轻松应对多进程的随机读取,避免DDP训练中因数据加载延迟导致的GPU闲置。
(2) 随机读取性能
PyTorch的
DataLoader默认会打乱数据顺序(shuffle=True),导致大量随机读取。HDD随机读取速度:约 1~2 MB/s(7200 RPM硬盘)。
SSD随机读取速度:约 50~500 MB/s(SATA/NVMe)。
差距可达100倍以上,直接影响epoch迭代速度。
(3) 延迟敏感
DDP要求所有GPU同步数据,高延迟的HDD会导致某些进程等待数据,破坏训练节奏。SSD的微秒级延迟能保证批次数据准时送达。
解决方法
将数据集从HDD移动到SSD上(效果立竿见影)
启用
pin_memory=True:将数据预加载到GPU显存的锁页内存,减少CPU-GPU传输延迟。增加Dataloader的num_worker。
将文件转换为.hdf5或.frecord 将小文件合并为连续存储的大文件,减少随机寻址开销。
# 启用pin_memory=True
dataloader = DataLoader(dataset, batch_size=64, shuffle=True,
num_workers=4, pin_memory=True)- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享