
PyTorch DDP详解
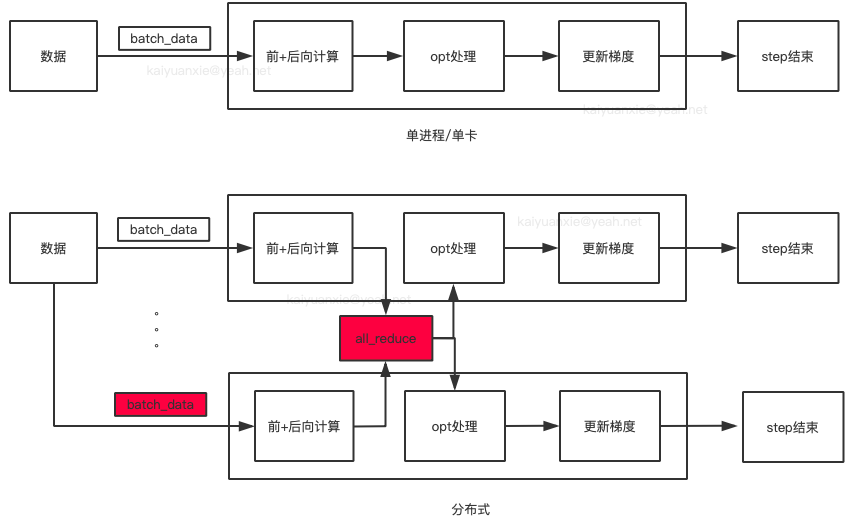
编辑框架图
命令
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=0 --master_addr="localhost" --master_port=12355 ddp.py在分布式训练中,使用 torch.distributed.launch 启动脚本时,它会自动为每个进程传递 local_rank 参数,因此不需要显式设置 local_rank,每个进程会分配一个唯一的 local_rank 值(从 0 到 nproc_per_node - 1)。
python ddp.py --local_rank=0 python ddp.py --local_rank=1 python ddp.py --local_rank=2 python ddp.py --local_rank=3--nproc_per_node=4:每个节点(机器)上启动 4 个进程(通常对应 4 个 GPU),如果机器有 4 个 GPU,则每个 GPU 分配一个进程,每个进程会独立加载模型和数据,通过 DDP 同步梯度。--nnodes=1:总共使用 1 个节点(单机训练)。如果是多机训练(如 2 台机器),则设为 --nnodes=2,并配合 --master_addr 和 --master_port 指定主节点地址。--node_rank=0:当前节点的编号为 0(单机时固定为 0)。主节点设为0,其他节点依次为1, 2, ...。--master_addr="localhost":主节点的 IP 地址,也可以设置为127.0.0.1。--master_port=12355:主节点监听的端口号(用于进程间通信)。需确保端口未被占用(可随意选择,如12355、29500)。
代码示例
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def main():
# 1. 初始化进程组
dist.init_process_group(
backend="nccl", # 使用 NVIDIA NCCL 后端(GPU 必须)
init_method="env://", # 通过环境变量自动获取 master_addr 和 master_port
)
# 2. 获取当前进程信息
rank = dist.get_rank() # 进程编号(0 ~ nproc_per_node-1)
local_rank = int(os.environ["LOCAL_RANK"]) # 当前 GPU 编号
# 3. 绑定 GPU
torch.cuda.set_device(local_rank)
# 4. 创建模型并包装为 DDP
model = MyModel().cuda()
model = DDP(model, device_ids=[local_rank])
# 5. 数据加载(需使用 DistributedSampler)
dataset = MyDataset()
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, sampler=sampler)
# 6. 训练逻辑
for epoch in range(10):
sampler.set_epoch(epoch) # 确保每个 epoch 数据不同
for batch in dataloader:
...
if __name__ == "__main__":
main()常见问题
为什么用
nccl后端?nccl是 NVIDIA 的优化通信库,专为多 GPU 设计,比gloo更快(GPU 必须)。
多机训练如何修改?
设
--nnodes=2,--master_addr为主节点 IP,其他节点--node_rank=1。
LOCAL_RANK是什么?由
torch.distributed.launch自动注入的环境变量,表示当前进程的 GPU 编号(0~3)。
数据如何分配?
必须用
DistributedSampler,它会自动切分数据,确保不同进程处理不同部分。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享