
Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models
编辑论文链接:https://www.arxiv.org/pdf/2407.10299
代码链接:https://github.com/Yuchen413/AnomalyRuler
该论文来自 ECCV 2024
背景
视频异常检测(Video Anomaly Detection, VAD)在安全监控和自动驾驶等应用中至关重要。然而,现有的VAD方法在检测到异常时很少提供背后的原理,这限制了它们在现实世界部署中获得公众信任的能力。因此需要开发出能够提供推理过程的VAD方法。
大语言模型(LLMs)在各种推理任务中表现出色。然而LLMs对异常的理解与特定场景所需的异常定义之间存在不匹配,这使得LLMs在直接执行VAD任务时效果不足。
动机
尽管大型语言模型(LLMs)已经在多种推理任务中展现出了革命性的能力,但直接使用它们进行 VAD 存在不足。预训练在 LLMs 中的隐含知识侧重于一般性的内容,可能不适用于每一个具体的现实世界 VAD 场景,导致缺乏灵活性和准确性。
基于LLMs推理的VAD框架 AnomalyRuler
提出了一种利用训练集中少量正态样本作为参考(规则)来推导VAD规则的新方法。
具有跨数据集的强域适应性,能够适应场景相似但视觉外观不同的数据集。
提出了规则聚合、感知平滑和鲁棒推理策略,增强了AnomalyRuler的鲁棒性。
方法
整体框架
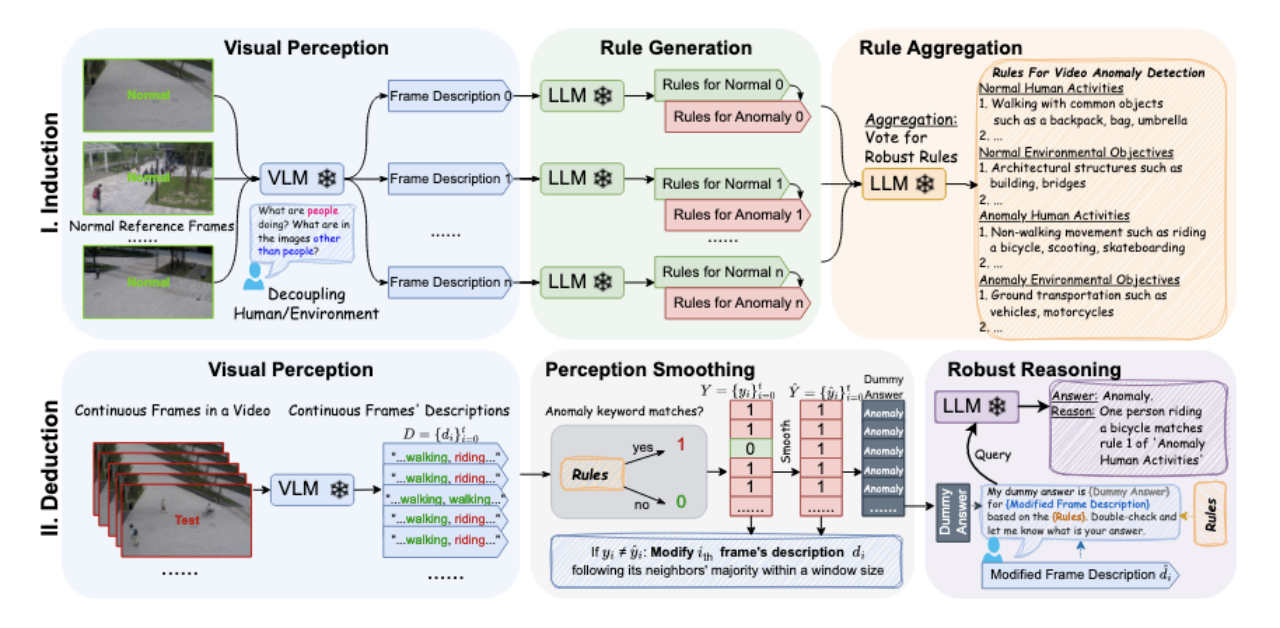
该方法共两个阶段,分别为归纳阶段(Induction Stage)和归纳阶段(Deduction Stage)。
归纳阶段(Induction)
Video Perception
使用VLM将视频帧(Video Frames)转换为文本描述(Descriptions)。
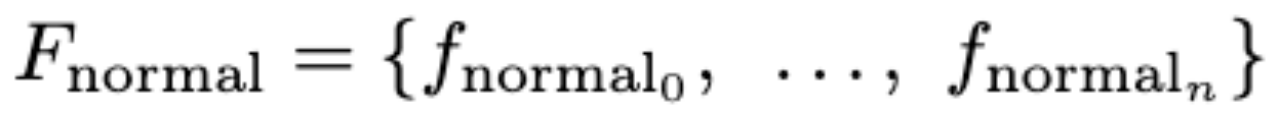
作为给定的few-normal-shot reference frames得到相应的descriptions
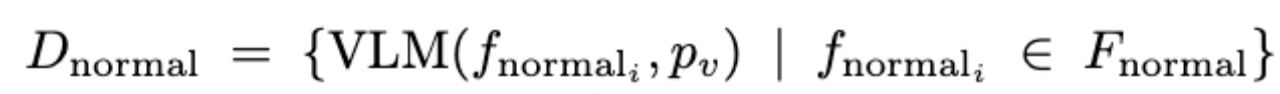
其中pv 作为prompt提示给出,pv 能够通过将模型的注意力引导到场景的特定方面来提高感知精度,并将任务划分为人类活动规则和环境物体规则两个子问题来简化下面的规则生成模块。
Rule Generation
将Visual Perception输出的文本作为冻结参数的LLM的输入来生成规则(Rules)。
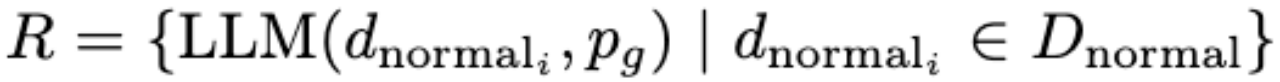
其中pg 作为prompt提示给出,pg 由三种策略制定而来,分别是:
Normal and Anomaly:通过将异常规则与正常规则进行对比,生成异常规则。
Abstract and Concrete:从一个抽象的概念开始,然后有效地推广到更具体的例子。
Human and Environment:引导LLM分别关注环境因素(如车辆或场景因素)和人类活动。
Rule Aggregation
将Rule Generation输出的规则作为使用LLM作为具有投票机制的聚合器的输入来得到一组健壮完善的规则(Rules)。 聚合过程通过保留在n个集合中一致出现的规则元素来过滤掉不常见的元素。
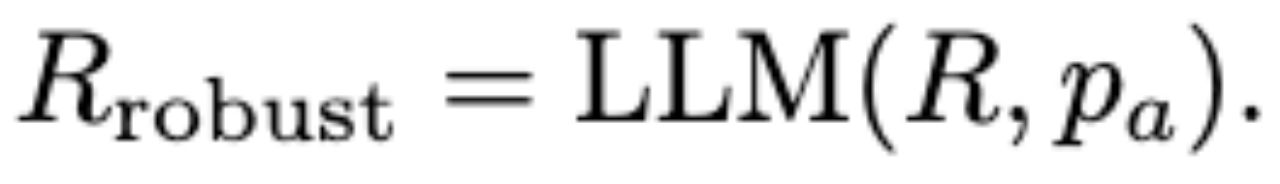
其中pg 作为prompt提示给出,该策略认为错误可能发生在单个输入上,但不太可能在多个随机采样输入上一致发生。因此,通过聚合这些输出,AnomalyRuler生成的规则对单个错误更具弹性。
演绎阶段(Deduction)
Video Perception
该部分与归纳部分保持一致,只是输入是持续性的视频帧,而不是一些normal reference frame,输出的也是持续的视频帧描述。
Perception Smoothing
利用平滑后结果来校正帧文本描述,增强AnomalyRuler对误差的鲁棒性。 对于连续的帧文本描述D=
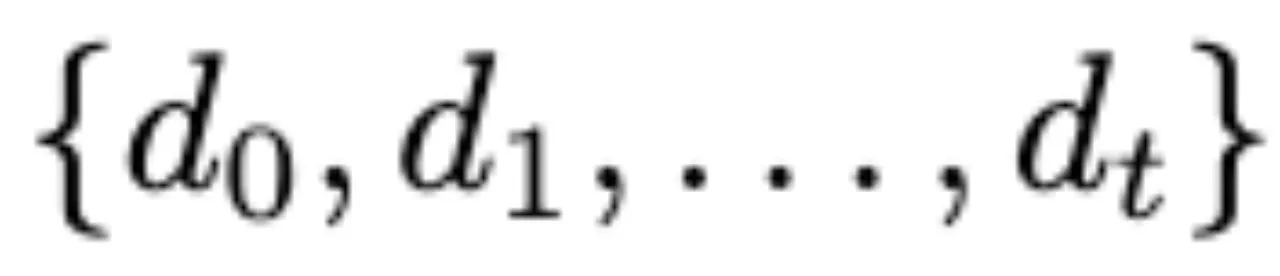
根据anomaly keyword K进行匹配,给di 分配对应的 predicted label yi ,y = 1表明di 为异常,y = 0为正常。最终得到初始预测
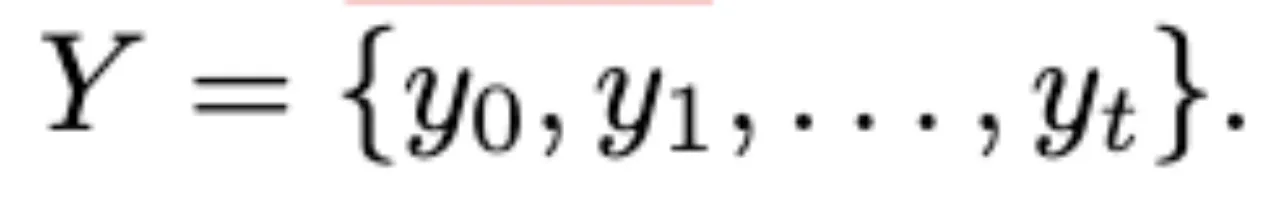
,通过计算得到anomaly score
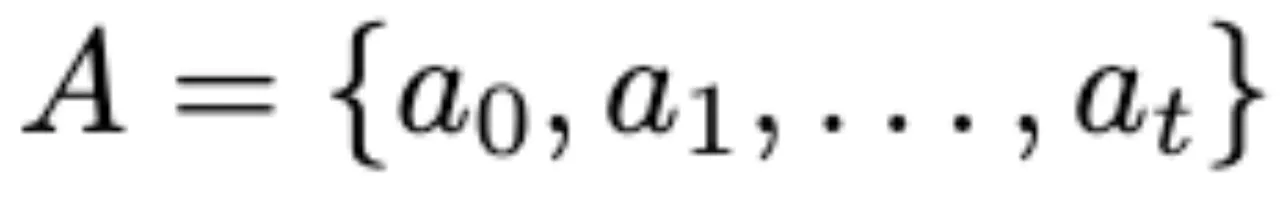
同时通过
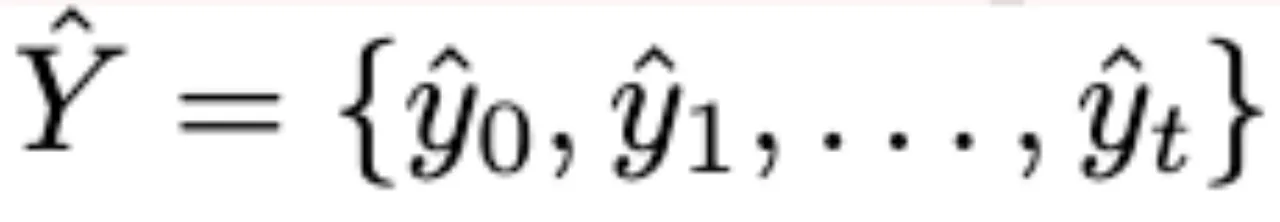
得到对应的Dummy Answer。比较y hat 和 y的值,AnomalyRuler删除描述中包含异常关键字k的部分来修改di。
Robust Reasoning
AnomalyRuler以归纳阶段导出的鲁棒规则Rrobust Rules为上下文,利用LLM实现VAD的推理任务。 di hat及其 dummy answer作为LLM的输入来得到输出
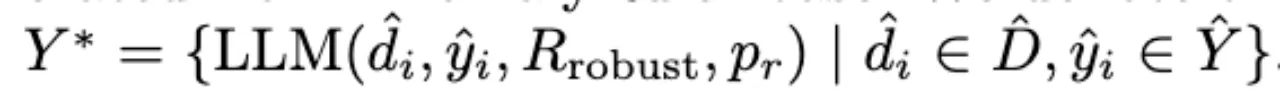
pr会引导LLM根据Rrobust重新检查虚拟答案是否与描述匹配。
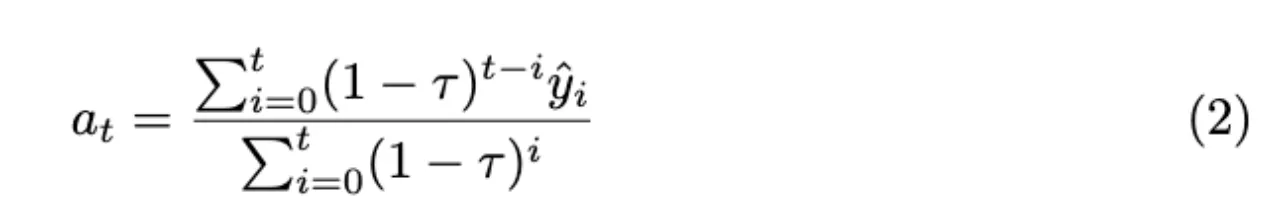
使用公式(2)计算最终的异常分数。
实验
数据集
UCSD Ped2 (Ped2):在人行道上捕获的单场景数据集包含超过4,500帧的视频。
CUHK Avenue (Ave):在中大校园大道拍摄的单场景数据集,包含超过30,000帧视频。
ShanghaiTech (ShT):一个具有挑战性的数据集,包含13个校园场景,超过317,000帧视频。
UBnormal (UB):由Cinema4D软件生成的开放式虚拟数据集,包含29个场景,超过236,000帧视频。
评价指标
Area Under the receiver operating characteristic Curve (AUC)
Accuracy,Precision and Recall Metrics
DoublyRight Metric
结果图表
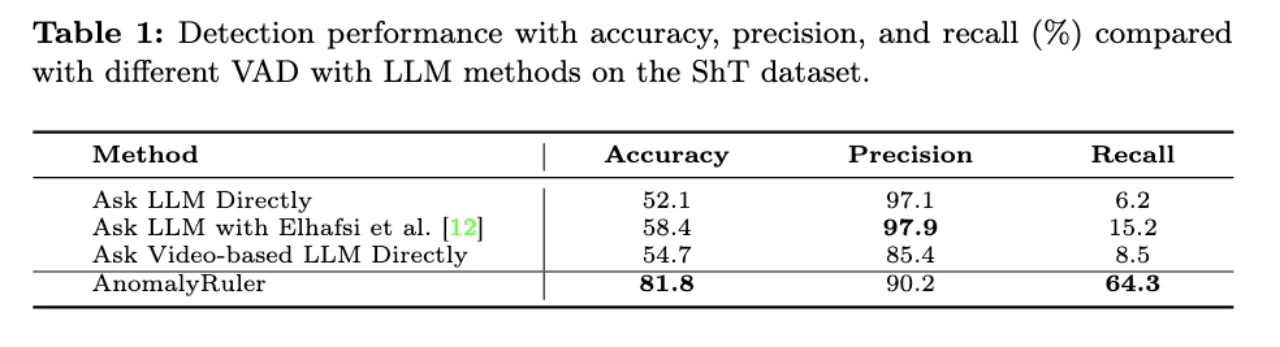
AnomalyRuler取得了显著的进步,准确率平均提高了26.2%,召回率平均提高了54.3%。这种改进归功于基于归纳阶段生成的规则的推理。
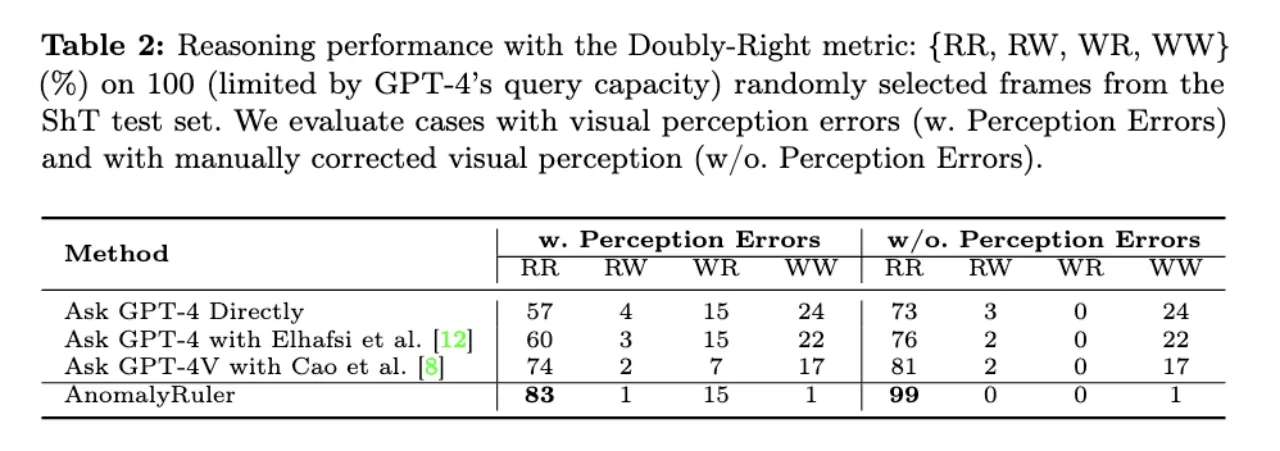
在没有感知错误的情况下,AnomalyRuler的识别率跃升至99%。证明了AnomalyRuler相对于GPT-4(V)基线模型的优势以及它在正确推理的同时进行正确检测的强大能力。


结果表明在不同的数据集上AnomalyRuler具有更好的域适应性。
消融实验
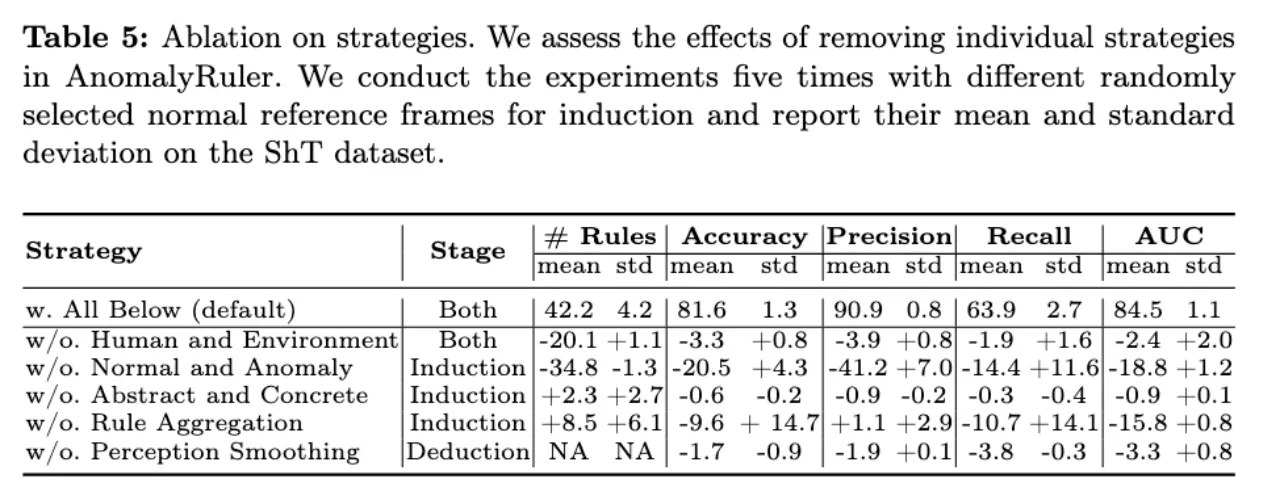
通过上表我们可以知道所提出的这些策略有效地提高了AnomalyRuler的性能。
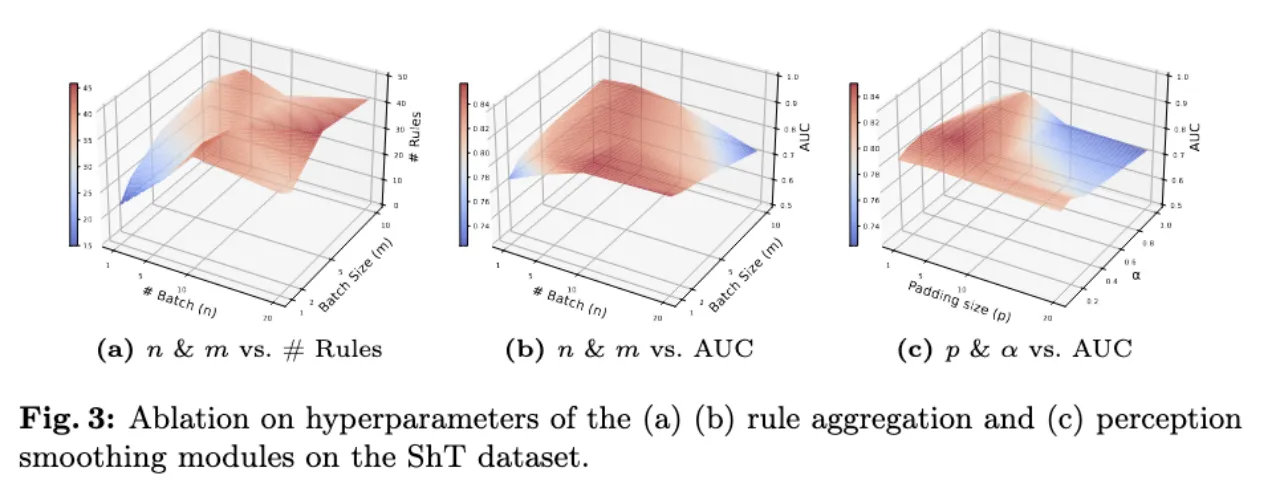
由(a) (b)图可知太多的参考帧(例如超过100个)会导致长上下文中的冗余信息,导致模型性能的下降。
由(c)图中将α值从0.09提高到0.33可以改善AUC,表明适度的EMA平滑是有益的。
总结
AnomalyRuler 是第一个针对单类 VAD 任务的推理方法,它只需要少量的正常样本提示,无需完整的训练,从而快速适应各种 VAD 场景。AnomalyRuler 不仅提供了推理能力,还展示了强大的领域适应性。
这篇论文针对视频异常检测领域提出了一个创新的解决方案,通过引入大型语言模型的推理能力,提升了模型对异常检测的透明度和信任度。此外,AnomalyRuler 的提出还推动了对 LLMs 在计算机视觉问题上应用的进一步探索。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享