
Open-Vocabulary Multi-Label Classification via Multi-Modal Knowledge Transfer
编辑论文链接:https://arxiv.org/pdf/2207.01887
代码链接:https://github.com/sunanhe/MKT
这篇文章发表在AAAI 2023上,使用VLP这种预训练的视觉语言大模型的先验知识通过知识蒸馏来指导低级的特征提取器进行训练是一个很好的思路,可以使用较低的成本完成对下游任务的特定适配。
Introduction
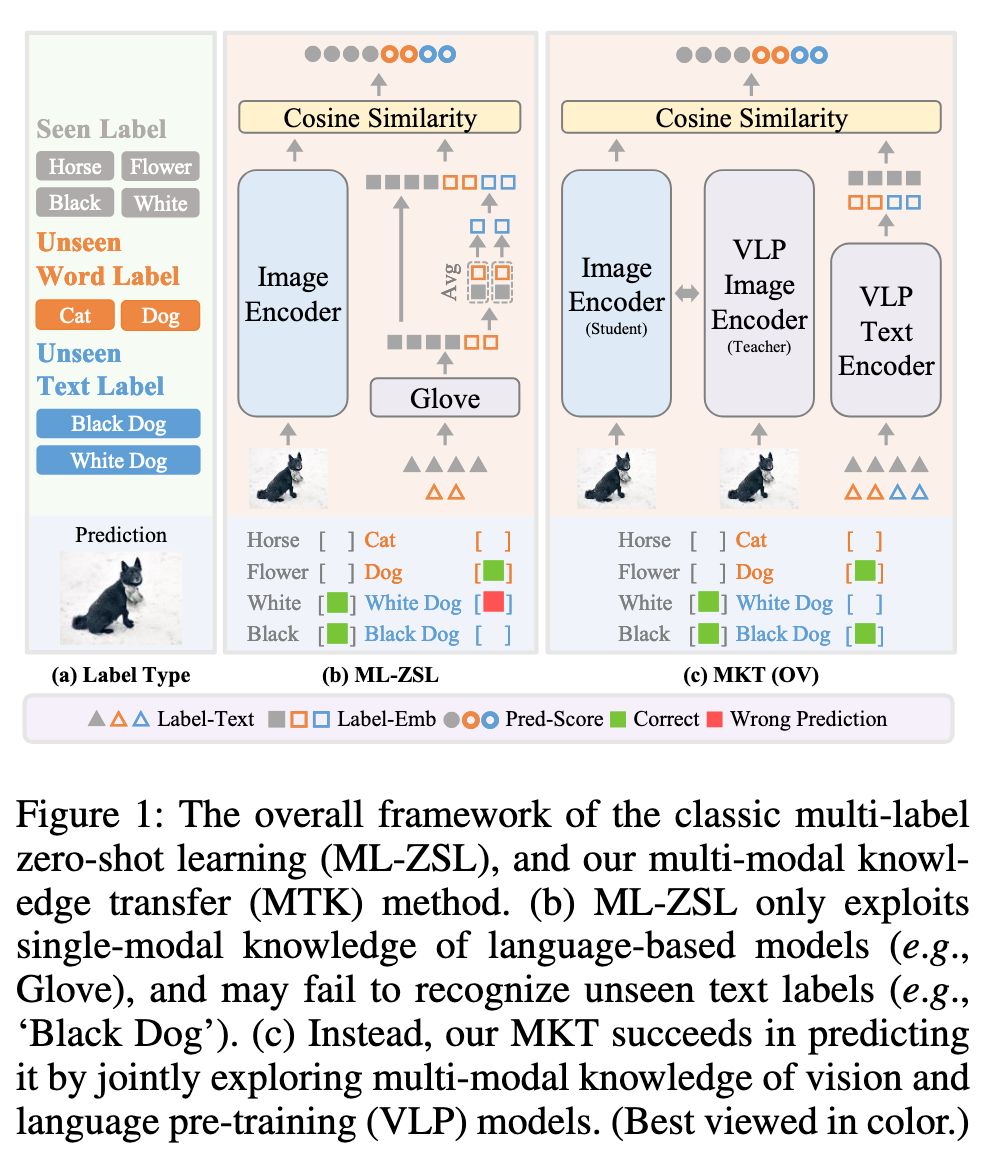
多标签分类是计算机视觉的重要任务,旨在识别图像中所有相关的标签。然而,现有方法通常只能处理训练中可见的标签,而无法应对许多实际应用中存在的“未见”标签。为解决这一问题,多标签零样本学习(ML-ZSL)尝试通过语言模型(如GloVe)进行知识转移,但其只利用了单一模态的信息,忽略了图像-文本对中的丰富语义信息。
GloVe 是一个词嵌入 word2vec 模型,它通过将每个词转换为向量(词嵌入),捕捉词语之间的语义关系。例如“Cat” 和 “Dog” 这两个标签的词向量会非常接近,因为它们在语义上是相似的。
这里的单一模态指的是仅依赖于语言模态的信息。也就是说,ML-ZSL方法仅仅利用标签的词嵌入(如GloVe)来获取类别的语义信息,而不涉及图像内容。语言模型(如GloVe)只能反映标签的语义信息,无法直接捕捉与标签相关的视觉信息。例如,“Cat”和”Dog”在GloVe中的词嵌入可能非常相似,但这些词向量并没有包含猫和狗在图像中的视觉差异。
图像-文本对中包含了图像和标签的多模态信息,即每个标签在图像中都有相应的视觉特征。比如,“Cat”标签不仅有语言上的含义(如GloVe的词向量表示),还有与之对应的图像特征(猫的形状、颜色、毛发等视觉元素)。
利用图像和文本的共同信息,可以更好地理解和推断未见类别的特征。
Motivation
现有的ML-ZSL方法存在两大问题:
仅依赖于语言模型的单模态知识,缺乏视觉一致性,处理复杂文本标签(“黑狗”)时表现有限。
为了更好地利用多模态知识,近期的开放词汇(Open-Vocabulary, OV)方法在物体检测任务中表现出色,但这些方法在多标签分类中的应用尚待探索。
一种新的开放词汇框架,称为多模态知识转移(MKT)
模型架构:结合视觉和语言预训练模型(VLP),利用图像和文本编码器提取多模态知识。
知识蒸馏:确保图像嵌入与标签嵌入之间的一致性。
提示调优(Prompt Tuning):通过优化文本嵌入模板,增强分类性能。
双流模块:通过捕获全局和局部特征,提高特征表征能力。
Method
Framework
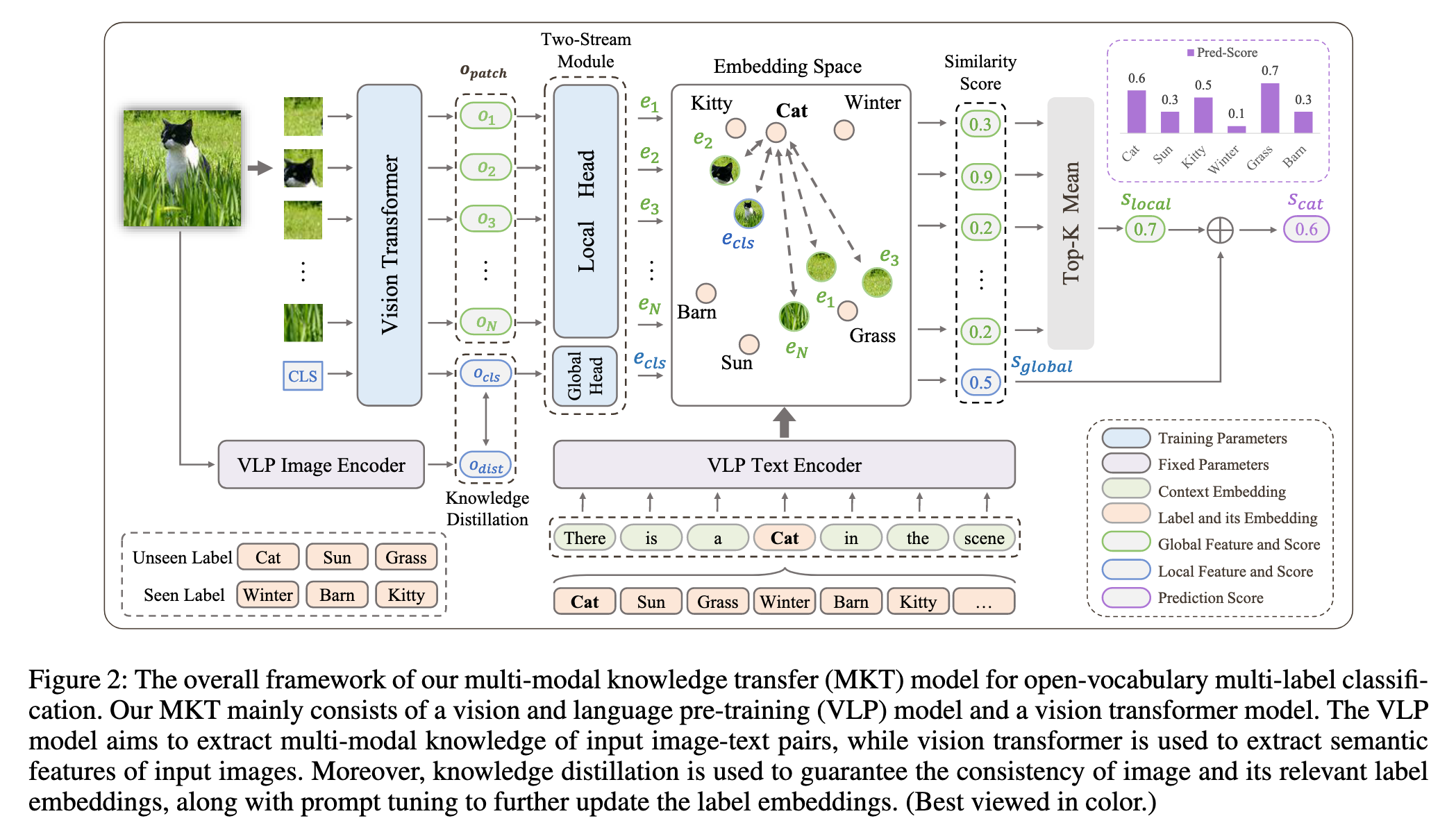
在 MTK 中,学生模型不仅提取视觉特征,还需要学习如何将这些特征与标签嵌入(由 CLIP 提供的标签嵌入)对齐,以进行准确的多标签分类。
教师模型 CLIP 生成的图像特征(如图像嵌入)和标签嵌入(如通过文本编码器生成的标签词向量)提供了图像与标签之间的丰富语义对齐信息。
学生模型(Vision Transformer)从图像中提取低级特征,并通过蒸馏过程将这些特征调整为更高层次的表示,使得它们能够与 CLIP 的标签嵌入对齐。
通过 知识蒸馏,教师模型引导学生模型学习如何将图像特征与标签嵌入对齐,从而帮助学生模型更好地进行多标签分类,尤其是对于 未见类别 的分类能力。
Q: 那么为什么不直接使用CLIP 而是要再加一个学生模型呢?
A: 使用知识蒸馏的优势在于通过从教师模型(如 CLIP)中传递知识,学生模型能够在较少计算资源和数据的条件下,获得更高的性能和泛化能力。CLIP是一个通用的模型,而知识蒸馏还能够帮助学生模型专注于目标任务、提高鲁棒性,并且减少模型的计算和内存消耗。
Vision Transformer with Two-Stream Module
选用ViT作为backbone提取特征,将H*W*C的图片作为输入,经过切分和投影后得到N个patch,记为
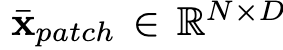
,使用ViT进行处理
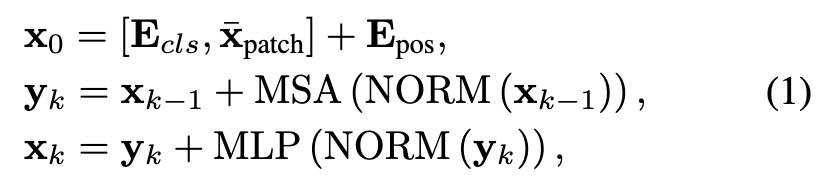
得到输出xL=$[{o_{cls},o_{patch}}]$,其中$o_{cls}$代表全局特征,$o_{patch}$代表局部特征。采用一个简单的双流模块,由本地头$Θ_L$(·)和全局头$Θ_G$(·)组成
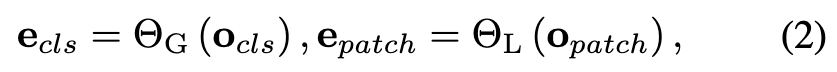
其中$e_{patch}$和$e_{cls}$代表global/local feature embedding。
公式(3)计算预测分数,公式(4)计算损失
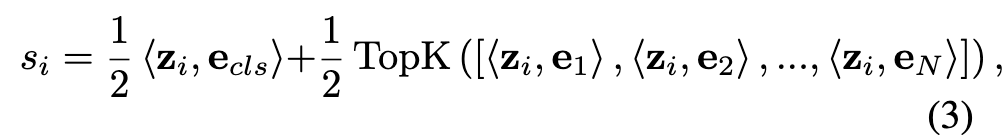
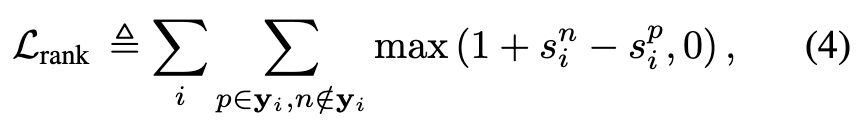
这个损失函数的目标是让正标签的得分大于负标签的得分。具体来说,我们希望 正标签的得分比负标签的得分高至少 1。如果 sni - spi 的差值小于 1,那么就会产生一个损失;如果差值大于或等于 1,则不需要任何损失。
如果正标签的得分小于负标签的得分 1 时,会产生一个正的损失值;否则,损失为 0。
这个排序损失的目标是通过对每一对正负标签的预测得分进行比较,来优化网络。对于每一个正标签 p 和负标签 n,损失会惩罚那些预测的 负标签得分比正标签得分高 的情况,具体的惩罚是通过 最大化正标签的得分 相对 负标签的得分 来实现的,要求正标签得分至少比负标签得分大 1。
要求正标签得分至少比负标签大 1,而不是 0,是为了确保 足够大的间隔,从而提升模型的 区分能力。这种设计有助于避免模型对正负标签得分非常接近的情况过于宽容,并且能够增强模型的 排序能力,使其在多标签排序任务中表现得更好。除此之外,避免出现损失为0的情况而导致梯度消失的情况。
Knowledge Distillation for Alignment
采用包含image encoder和text encoder的CLIP作为VLP模型,引入知识蒸馏来促进image embedding与其对应的seen label embedding之间的对齐。 指定教师模型(CLIP image encoder)为
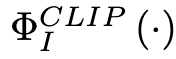
蒸馏的过程可以总结为公式(5)
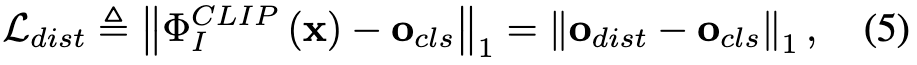
其中$o_{cls}$是由ViT(学生模型)得到的图像全局特征,$o_{dist}$代表CLIP image encoder的输出。
Prompt Tuning for Label Embedding
设计了manual prompt template
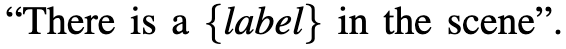
使用标签名称填充模板后,将其作为CLIP text encoder的输入,得到的输出作为label embedding使用。由于训练目标不同,预训练的CLIP text encoder生成的label embedding对于多标签分类可能不是最优的,因此对label embedding进行微调。 具体做法是在调优过程中,除了提示模板的上下文嵌入(如图中的虚线框所示)之外,所有参数都是固定的,实验证明基于CLIP文本编码器的嵌入空间连续搜索有助于任务学习最佳上下文嵌入。
为了提高标签嵌入的质量,进一步对标签嵌入进行微调(fine-tuning)。但是,直接微调整个文本编码器存在困难,主要是因为训练样本的数量不足,会导致 模式崩溃(mode collapse) 的问题,无法有效训练整个模型。
与手动编写的固定Prompt模板不同,Prompt Tuning 通过优化模板中的上下文嵌入,使得该部分能够更好地适应多标签分类的任务,从而获得更好的标签嵌入。
Loss Functions
训练过程分为两个阶段:
通过预训练的CLIP文本编码器生成标签嵌入,并以排序损失和蒸馏损失为目标训练视觉编码器。
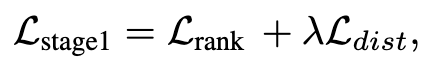
使用排序损失来微调上下文嵌入。
Experiments
Datasets
NUS-WIDE:除了基于Flickr用户标签的925个标签之外,还有81个人工验证的标签。在实验中将925个标签视为可见标签,其余81个标签视为未见标签,使用161,789张图像进行训练,使用107,859张图像进行测试。
Open Images (v4) :由9M张训练图像和125,456张测试图像组成。将训练集中超过100张图像的7186个标签视为可见标签,将训练数据中不存在的最常见的400个测试标签视为未见标签。
Metrics
mean Average Precision (mAP)
Top-k位置的F1 Score
Result
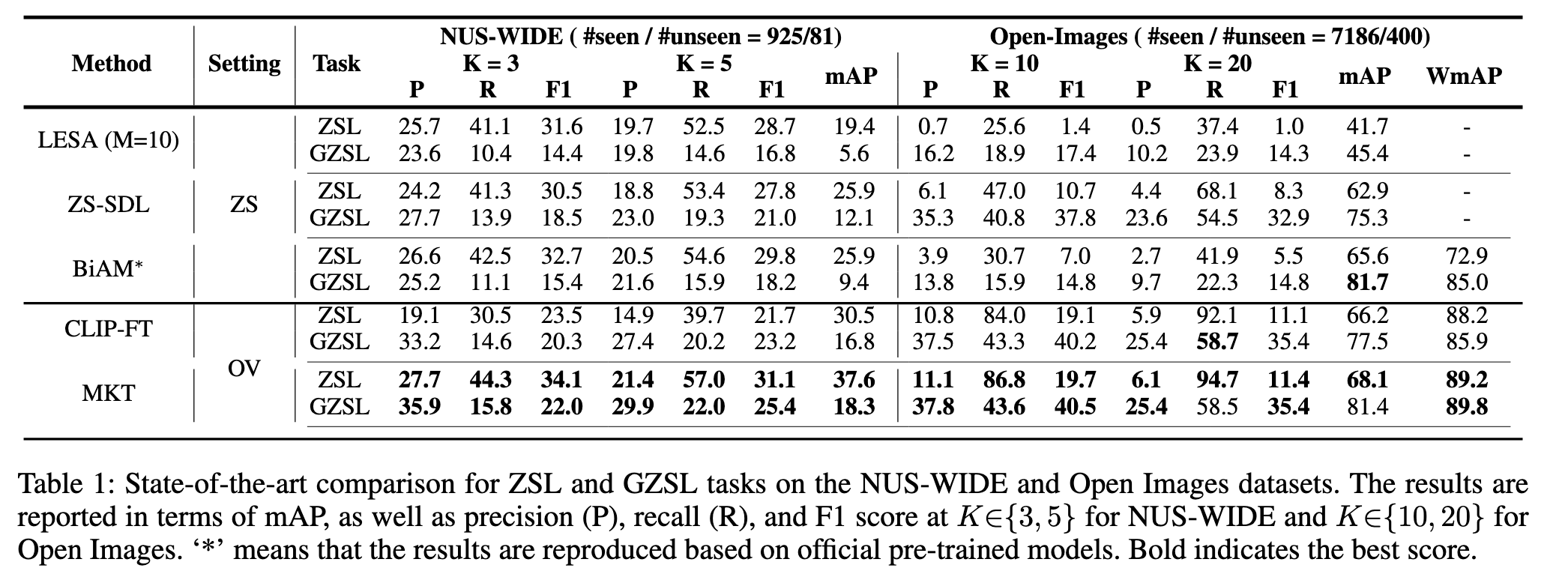
其中ZSL为zero-shot learning ,用于训练分类器以推断可见标签(seen label);GZSL为generalized zero-shot learning,用于训练分类器以识别测试图像中存在的可见标签(seen label)和未见标签(unseen label)。
Ablation Study
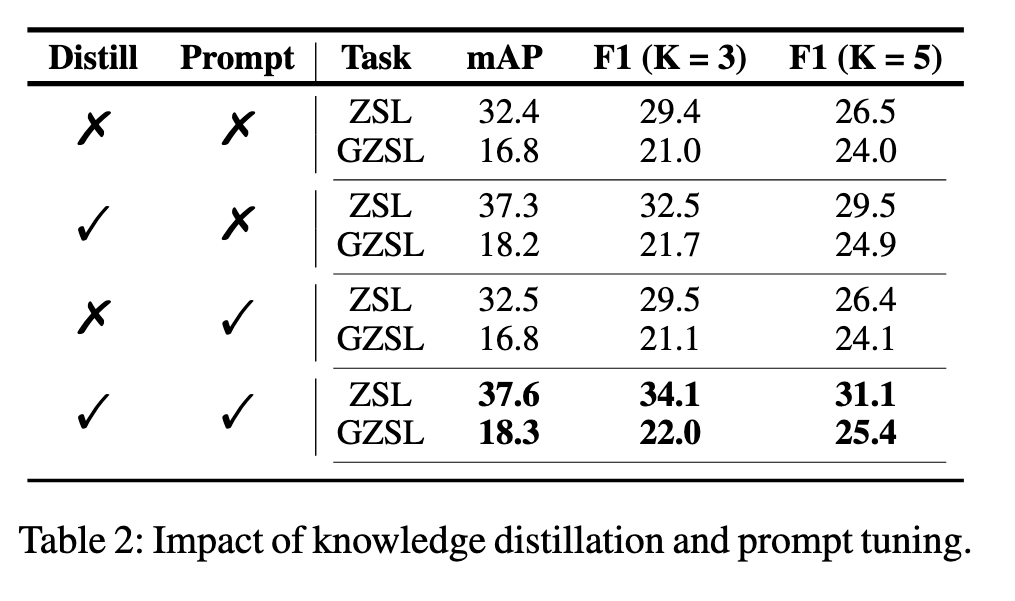
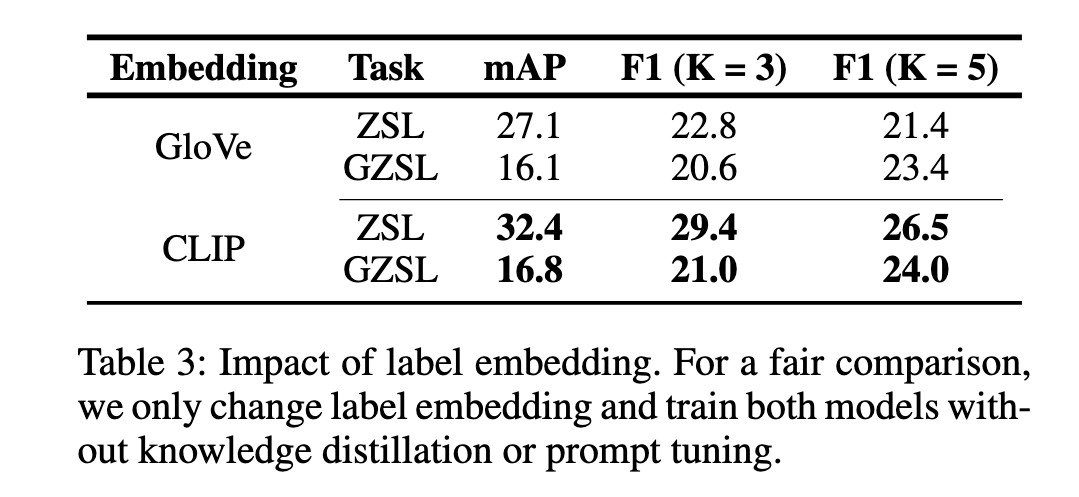
由于CLIP有视觉和文本特征嵌入的对齐,比使用单一文本模态的GloVe的性能更加出色。

图3展示了总体Top-3精度的检索结果和检索标签的示例。与语言模型相比,VLP模型可以同时捕获标签之间的语义一致性和视觉一致性。例如,“女孩”与“男人”,“孩子”和“人”包含类似的视觉信息,因此认为具有视觉一致性和语义一致性的标签嵌入有助于对不可见标签的泛化。
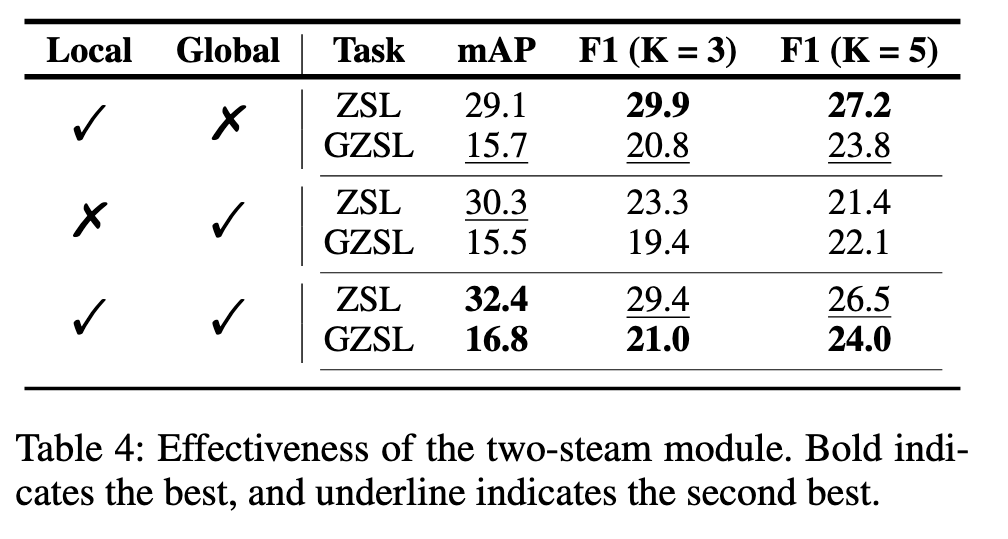
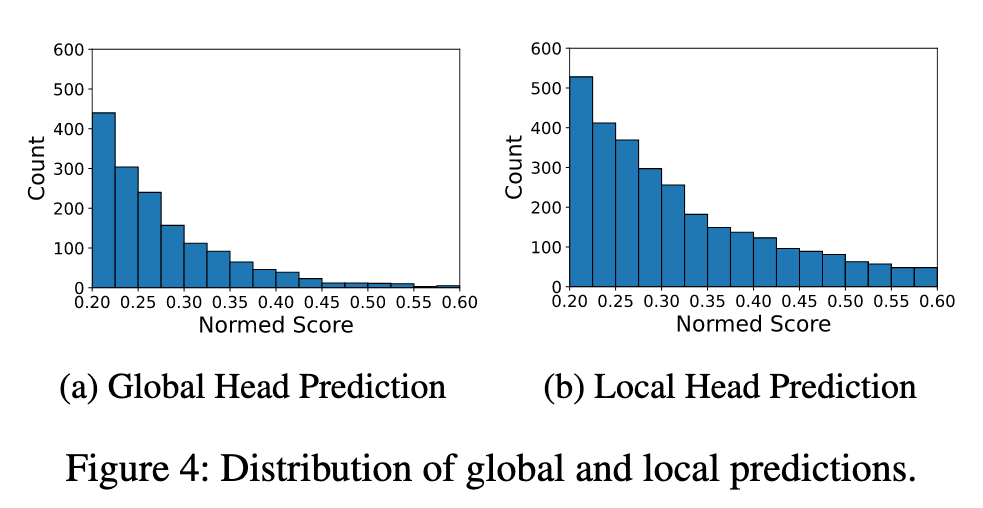
由于全局表征更普遍,而局部表征更具判别性。如图4所示,局部头部倾向于预测比全局头部更高的分数。虽然更具辨别力的特征可以让相关标签脱颖而出,但它也使模型对噪音更敏感,从而导致错误的预测。另一方面,与F1分数相比,mAP分数越高,就越容易受到错误预测的影响。因此,局部头部模型F1得分较高,mAP得分较低。结合局部头和全局头,双流模块可以获得更多的判别预测和抗噪声,从而获得更高的性能。
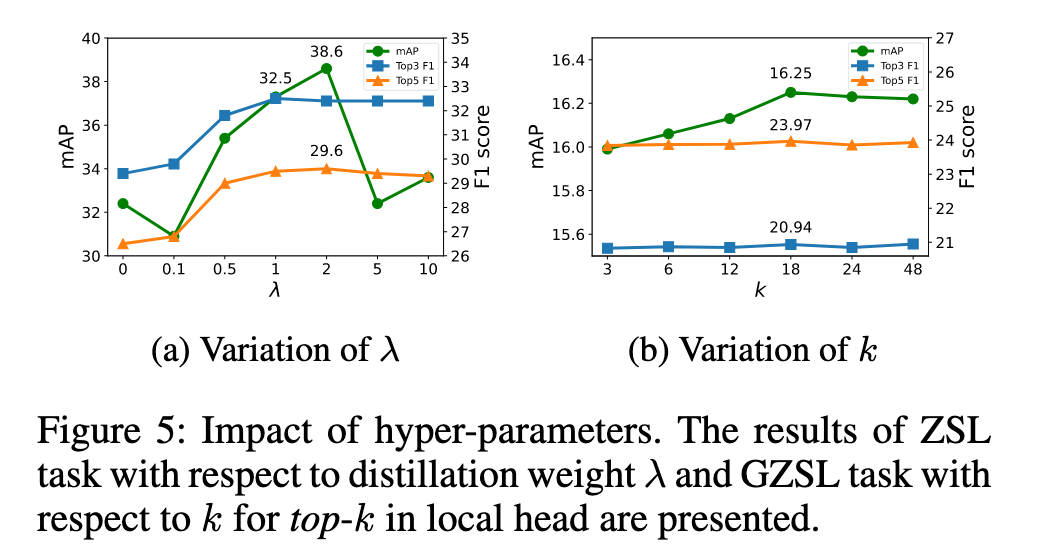
知识蒸馏:较小的蒸馏权重有助于提高未见标签的分类性能,过大的蒸馏权重则可能影响分类目标的学习。
局部头的k值:适当增大 k值(如k=18)能够平衡噪声和区分度,从而提升 F1得分 和 mAP。较小的 k值 对噪声敏感,较大的 k值 则可能导致输出失去区分度
Visualization


Conclusion
提出了一种基于开放词汇表的多模态知识转移(MKT)框架,该框架共同利用了基于图像-文本对的VLP模型中的语义多模态信息。为了便于将VLP模型的图像-文本匹配能力转化为分类,引入了知识蒸馏和提示调优。还提出了一个双流模块来捕获局部和全局特征,从而显著提高了模型在多标签任务中的性能。
MKT首次在多标签分类任务中探索了开放词汇方法,通过有效利用图像-文本对中的多模态知识,实现了对已见和未见标签的统一识别,展示了其在计算机视觉中的广泛应用潜力。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享