
解决PyTorch DDP训练卡住问题
编辑问题描述
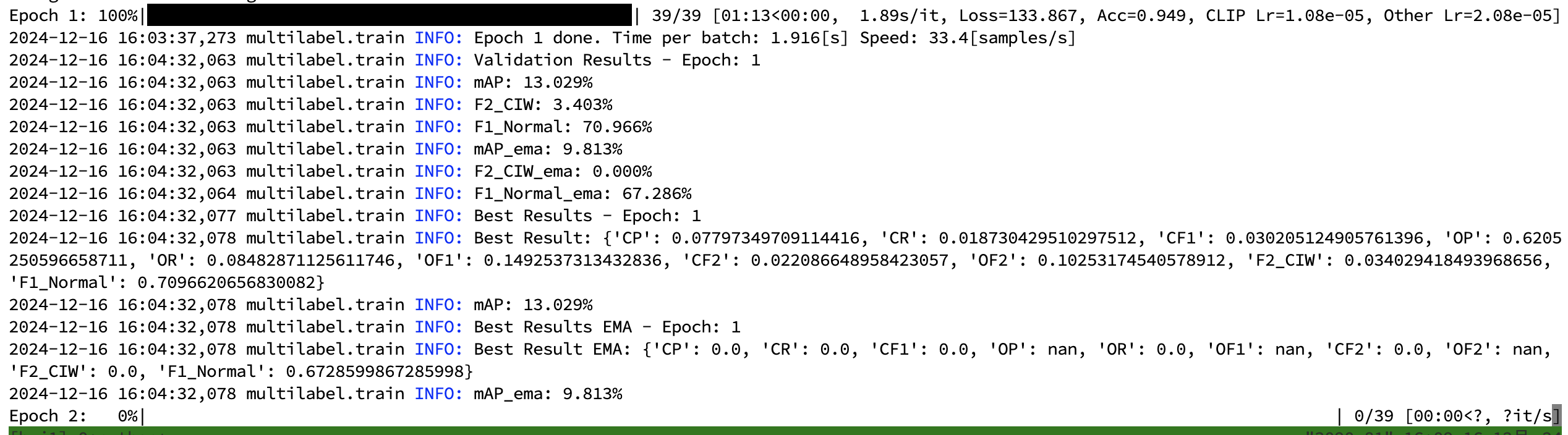
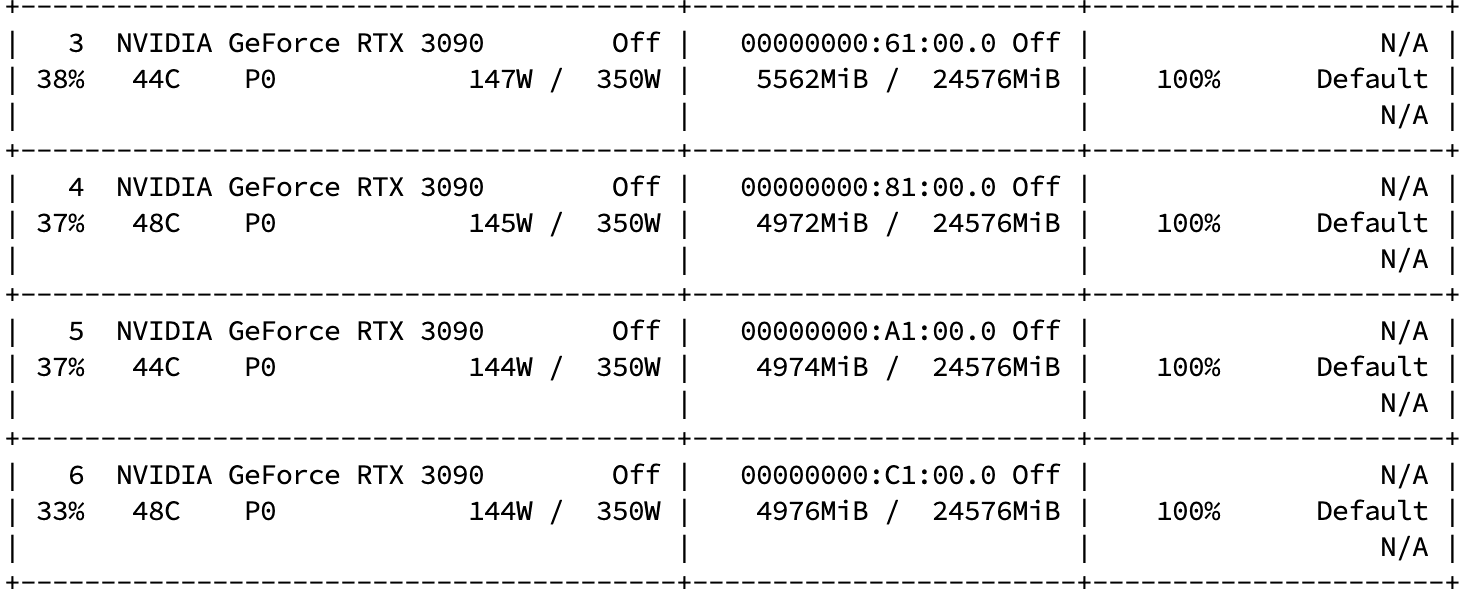
使用DDP进行训练时,第一个epoch能够正常训练和验证,并输出相应的指标,但在第二个epoch开始后就卡住了,同时显卡的占用率高达100%,持续了很长时间且始终无法降下来。单卡训练是没有问题的。
尝试了多种方法,都没有实际效果,包括
修改cuda进程同步代码
修改batch-size的大小
修改DDP启动的形式
解决方法
单卡训练没有问题,证明代码逻辑基本上都是正确的,所以首先考虑还是DDP部分代码的问题。
DDP启动主要分为三部分:
从启动的shell脚本中获取相关设备信息,初始化进程组(nccl是由NVIDIA提出的backend)
def setup_distributed(cfg): """ Setup distributed training environment and return the device and rank. """ local_rank = int(os.environ.get("LOCAL_RANK", 0)) torch.cuda.set_device(local_rank) device = torch.device("cuda", local_rank) torch.distributed.init_process_group(backend="nccl", init_method="env://") print(f"Process {os.environ.get('RANK')} initialized on GPU {local_rank}") return device, local_rank使用DistributedSampler为不同的进程(GPU)加载不同的训练集的子集
train_sampler = torch.utils.data.distributed.DistributedSampler(train_set) train_loader = torch.utils.data.DataLoader(train_set,batch_size=batch_size,pin_memory=True,num_workers=num_workers, shuffle=False,sampler=train_sampler,collate_fn=train_collate_fn,drop_last=True)使用DistributedDataParallel启动DDP训练
model = torch.nn.parallel.DistributedDataParallel( model, device_ids=[local_rank],find_unused_parameters=False )
这段DDP初始化启动代码是比较正常的,也没有什么明显的问题,但是我在运行的时候就会出现上面提到的训练流程卡住的问题。
在网上翻看博客的时候无意间找到了一篇也是关于多卡DDP训练卡死问题的文章,文章里给出的DDP代码如下
model = MyNet(config).cuda()
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[config.LOCAL_RANK],
output_device=config.LOCAL_RANK,
broadcast_buffers=False,
find_unused_parameters=True)相比于我使用的代码多了output_device和broadcast_buffers两个参数
output_device:指定了 输出(final output) 应该存放的设备,通常应该与 device_ids 中指定的设备一致。如果它未显式设置,则模型默认将输出张量存放在 device_ids 中的第一个设备上。但有时,DDP 可能会遇到推断时的一些竞态条件,特别是在多卡训练中,导致训练过程中出现卡住的现象。
因此,如果你没有在 DistributedDataParallel 的构造函数中显式设置 output_device=local_rank,那么模型输出的设备可能与预期的设备不一致,可能导致一些内存和设备上的通信问题,尤其是在GPU分配和数据同步时。
broadcast_buffers:默认情况下,模型的所有缓冲区(如BatchNorm 层的均值和方差)会在每次训练的过程中进行广播(即在所有GPU间进行同步)。这对于某些模型可能会引起额外的开销或同步问题,尤其是在复杂的训练设置下。当你设置 broadcast_buffers=False 时,它会禁用对缓冲区的自动同步(广播),从而提高性能,同时也避免了一些潜在的阻塞操作。这个选项非常适用于那些不需要同步均值和方差等缓冲区的情况。
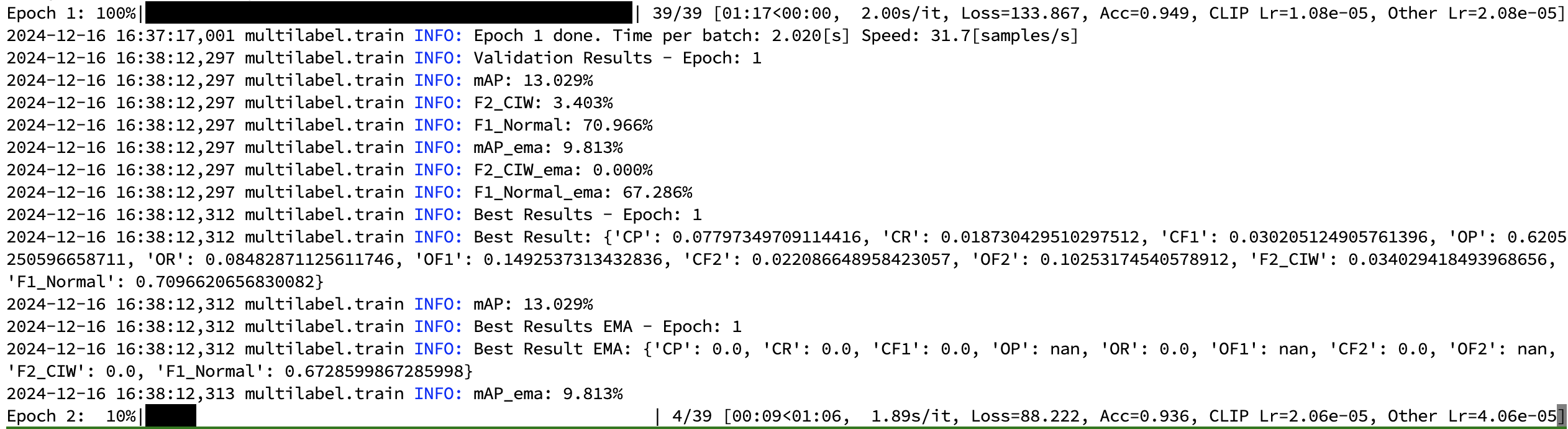
我尝试增加这两个参数进行实验,当设置broadcast_buffers=False时,DDP训练能够正常进行
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[local_rank], broadcast_buffers=False, find_unused_parameters=False
)
反正就很奇怪,我是没想明白为什么。
GPT-4o给出的解释是:
broadcast_buffers=False 确实能有效避免一些同步缓冲区的广播问题,从而解决卡住的问题。在使用 DistributedDataParallel (DDP) 时,默认情况下,模型的所有缓冲区(例如,BatchNorm 层的均值和方差)会在每次训练的过程中进行广播(即在所有GPU间进行同步)。这对于某些模型可能会引起额外的开销或同步问题,尤其是在复杂的训练设置下。
当你设置 broadcast_buffers=False 时,它会禁用对缓冲区的自动同步(广播),从而提高性能,同时也避免了一些潜在的阻塞操作。这个选项非常适用于那些不需要同步均值和方差等缓冲区的情况。
进一步解析:
• 默认行为(broadcast_buffers=True): DDP 会自动在每个训练步骤中广播模型中的缓冲区(例如 BatchNorm 的移动均值和方差),以确保所有的GPU上使用一致的数据。这可能导致通信和同步开销,尤其是在网络或硬件环境不稳定时,容易导致训练过程卡住。
• 禁用广播(broadcast_buffers=False): 设置为 False,则不会同步 BatchNorm 层等的缓冲区,这在某些情况下可以避免问题,尤其是当你确信这些缓冲区不需要在多GPU训练中同步时。通常,除非你有显式需求(如在某些特定场景下需要同步统计量),否则可以禁用这个选项来提升训练效率。
总结:
如果你的模型没有使用 BatchNorm 或者对同步这些缓冲区没有强烈要求,那么设置 broadcast_buffers=False 是一个优化训练速度和避免潜在卡住的良好做法。而在你遇到卡住的情况时,这个参数确实是一个有效的解决方案。
参考文献
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享