
Robust Contrastive Cross-modal Hashing with Noisy Labels
编辑论文链接:https://openreview.net/pdf?id=UBPu6deCPt
代码链接:https://github.com/LonganWANG-cs/NRCH
这篇文章发表在ACM MM 2024会议上。
Background
跨模态哈希(Cross-modal Hashing)是一种用来检索和存储不同模态数据(如图像和文本)的方法,主要优点包括:
存储成本低:二值哈希编码较连续特征更紧凑。
检索效率高:哈希距离计算效率远高于传统方法。
然而,现有的跨模态哈希方法面临以下主要问题:
标签噪声普遍存在:在实际数据中,标注可能因复杂性、人工错误或标签模糊而产生噪声。
依赖高质量标注:大多数方法隐含假设数据标签是准确的,而现实中,生成高质量标注代价高昂且资源有限。
标签噪声的存在会导致模型倾向于过拟合噪声数据,使得检索性能显著下降。

深度模型会因为对有噪声标签的过度记忆而加剧过拟合,使得静态分离策略在后期训练阶段中对有噪声标签和干净标签的分离效果较差。因此,鲁棒跨模态哈希需要一种可靠的动态标签噪声分离方法。
Motivation
噪声过拟合(Noise Overfitting):传统的分类或相似性损失容易被噪声标签误导,从而过拟合错误标注的样本。
2.错误积累(Error Accumulation):在迭代优化中,噪声会逐渐扩散,使模型性能进一步恶化。
噪声鲁棒的动态标签分离和学习框架(NRCH)
RCH:专注于真实样本对(homologous pairs),而非构造的正样本对(可能含噪声),从而提高跨模态表示的鲁棒性。
DNS:基于损失分布动态区分“干净样本”和“噪声样本”,自动适配不同数据集和噪声情况。
Method
Framework
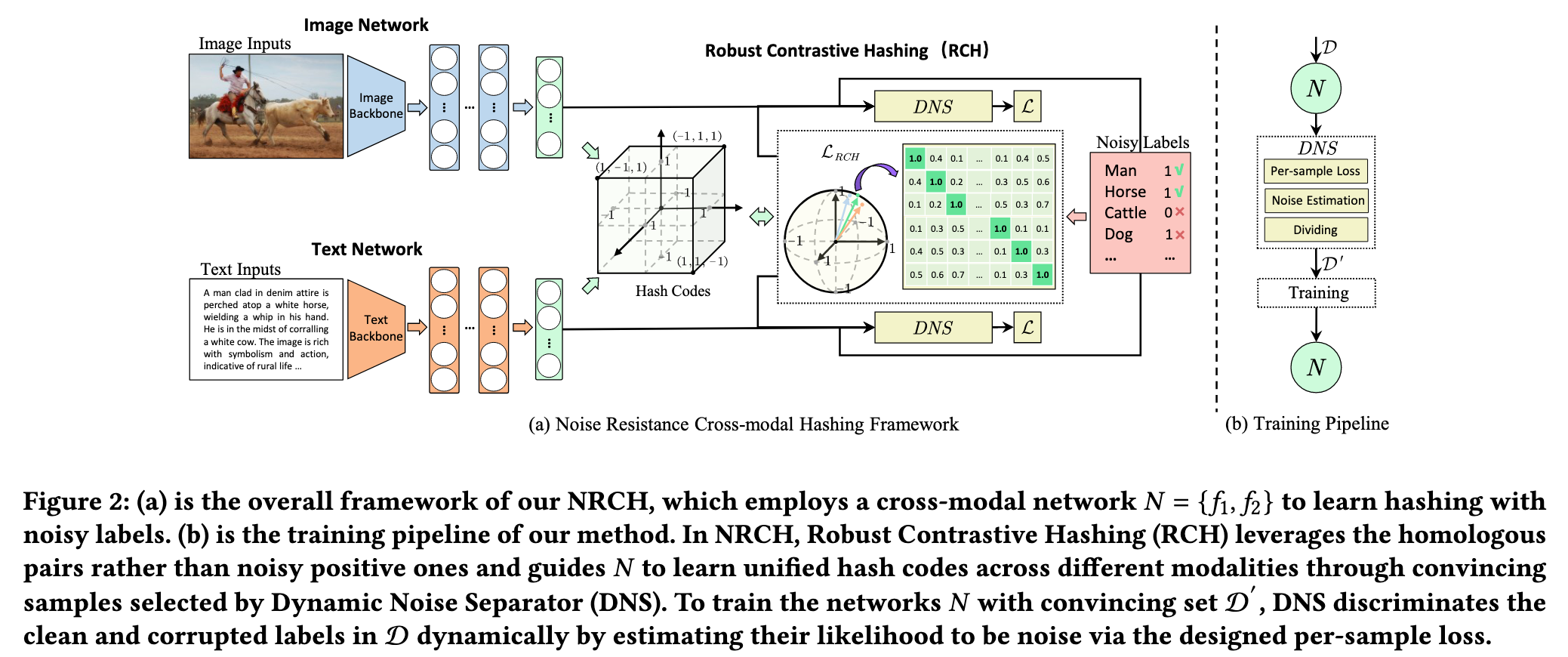
Problem Formulation
D为包含N个样本的多模态训练数据集,表示为
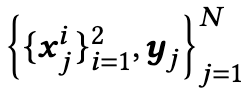
其中$x^i_j$代表第j个样本的第i个模态,在这篇文章中i=1代表图像模态,i=2代表文本模态。$y_j ∈ R^C$代表对应的噪声标签,以one-hot-encoding的形式表示。
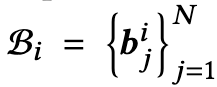
其中$b^*_j∈ \{{−1, +1}\}^L$, ∗ ∈ {1, 2},L代表hash code的长度,我们可以使用汉明距离来评估图像和文本样本之间的相似性。 对于任意的图像-文本对(x1i , x2j ),汉明距离表示为
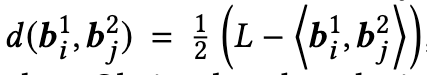
显然当Tij=1时汉明距离很小,而Tij=0时汉明距离很大。
为了学习统一的二进制表示,采用了针对不同模态量身定制的不同哈希函数, F∗(·,Θ∗),∗∈{1,2}在下文中表示为F∗或F∗(·),哈希函数的输出为
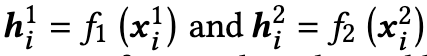
样本对应的二进制表示通过sign function得到
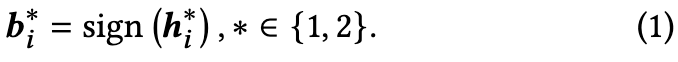
Robust Contrastive Hashing(RCH)
RCH的目标是拉近相似样本(相同类别的样本对应的二值哈希距离应接近)和区分非相似样本(不同类别的样本距离应尽量远)。
基于三元组损失的思想,定义如下:
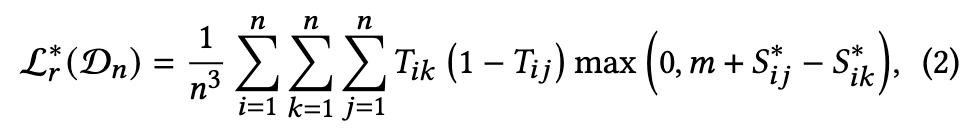
该公式用于**消除误导样本的平滑正则,**其中∗ ∈ {12, 21},Dn为D的mini-batch,m为对比学习中的正间隔。
采用S*的相似矩阵来处理false pairs,是一种相似度调整策略。
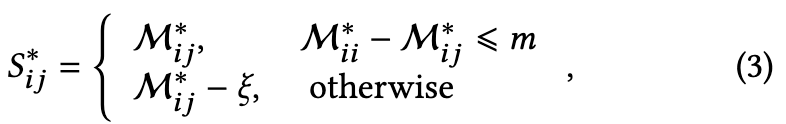
其中∗ ∈ {12, 21},m为对比学习中的正间隔。
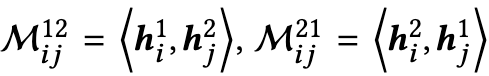
公式(3)利用了不同模式下相同样本的一致相似性以减少相似性矩阵中不可靠对(假正对FP和假副对FN)的影响,如框架图中对角线所示。
由于考虑了soft margin内的所有false pairs,该策略减轻了由noisy labels引起的false pairs的负面影响。
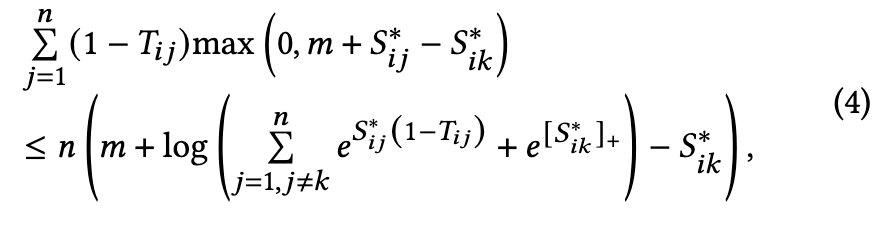
具体的推导过程为
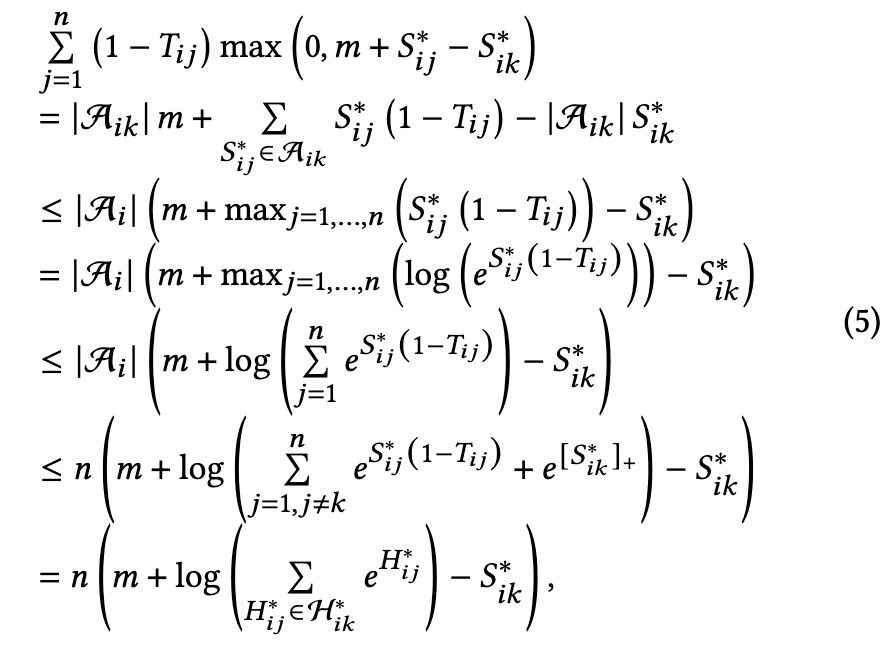
其中
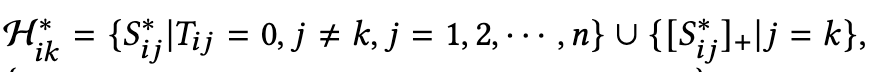
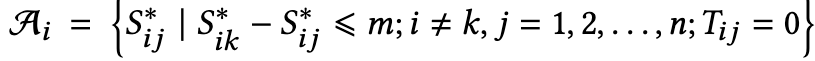
|Ai|表示集合Ai的长度
由公式(4)可以推导出以下不等式:
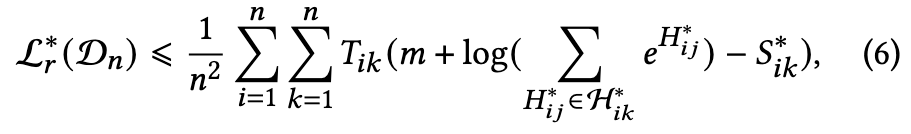
根据公式(6),可将公式(2)的最小化优化用损失函数重新表述为:
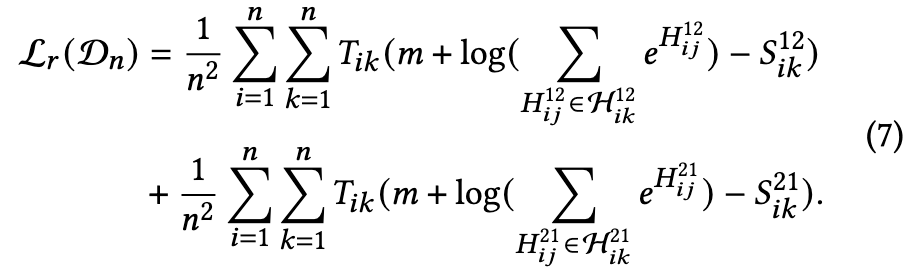
为了简化计算,只考虑对角线
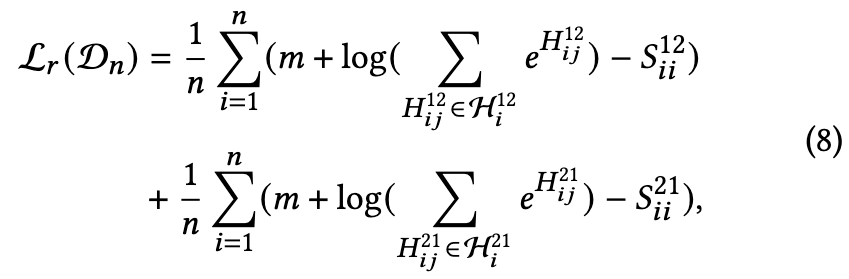
最后鲁棒对比哈希损失(RCH)表示为公式(9)
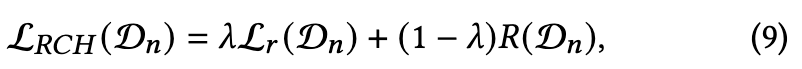
其中R(Dn)是二元正则化项。 R (Dn)的设计是为了减小获取的二进制码的量化误差,确保二值化编码的质量,为了防止后续训练中的过拟合,对|bij | = 1施加限制,最终的R (Dn)表示为公式(10)
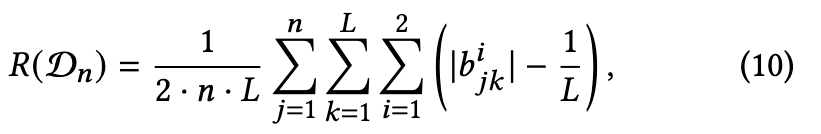
其中$b^i_{jk}$是$B^i_j$的第k个元素。
Dynamic Noise Separator
在训练的早期阶段,干净样本的损失值通常低于有噪声样本的损失值,这可以用于动态识别带有噪声标签的实例。更具体地说,DNS利用每个实例中干净样本和有噪声样本之间损失分布的对比来衡量其被破坏的可能性,并动态选择可靠样本来训练网络。
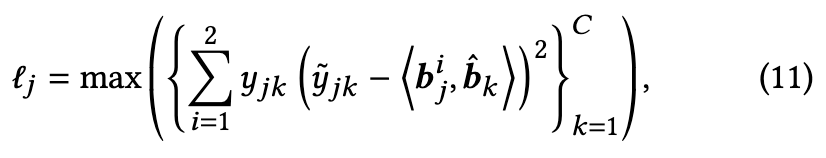
公式(11)用于计算每个样本的损失,其中$\hat{b}k$为所有类别的二进制表示,$\hat{y}{𝑗𝑘}$= 2$y_{jk}$-1 ∈{−1,1}来对齐二进制表示, max(·)的操作是通过选择最高损失值作为潜在标签损坏的指标来处理多标签样本中的噪声。随后通过双分量高斯混合模型(GMM),通过拟合整个数据集的损失分布来分离带有噪声标签的实例。
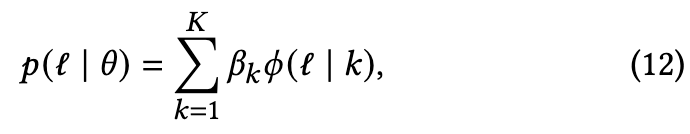
其中βk表示混合权重,φ (l | k)封装了模型中第k个高斯分量的概率密度。
计算后验概率,以表示第j个实例无噪声的可能性,k表示显示较低平均值的高斯分量。
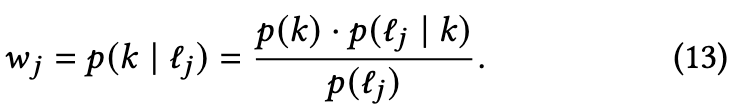
为了分离带有噪声标签的样本,在W = $\{w_j\}^N_{j=1}$上使用动态阈值将整个训练数据集划分为干净子集和噪声子集。
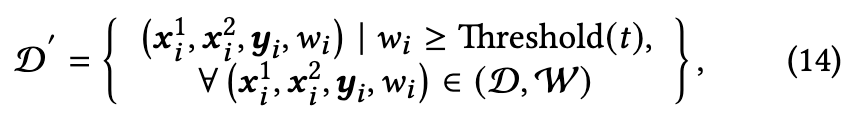
DNS启动时使用较低的阈值,以便在开始时包含广泛的数组,然后,为了保证保留干净的样本,同时在网络记忆之前过滤掉有噪声的样本,将阈值(t)逐渐提高到ξ∈(0,1)。
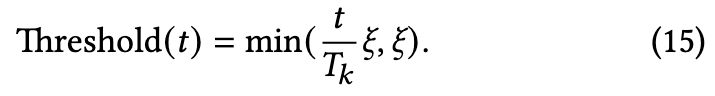
其中t代表当前训练的epoch。
Loss Functions
在动态选择之前,首先对训练集数据进行预热过程以达到初始收敛。 给定一个属于数据集D的mini-batch Dn,则warmup的损失函数为
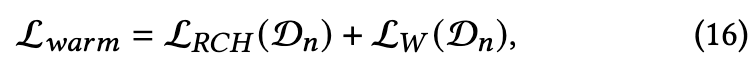
其中$L_W(D_n)$定义为
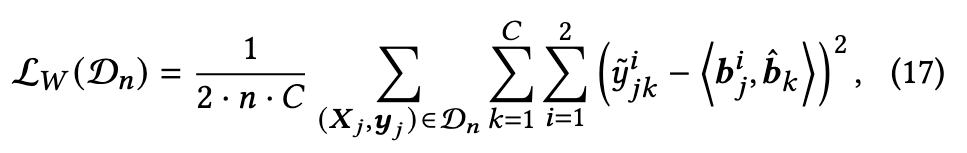
在实现初始收敛后,利用DNS来选择可信的样本,使用它们对模型进行鲁棒训练。
Overall Loss:
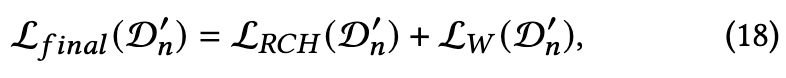
其中$D^′_n$ = $D_n$ ∩ D′
Training Process

图像和文本输入通过对应网络 f1, f2 提取跨模态特征表示。
RCH 模块在哈希空间中通过鲁棒损失函数 LRCH 进行优化,确保正样本对更相似、负样本对更区分。
DNS 模块根据样本损失动态筛选出高置信度的样本,形成可信样本集合 D ′
可信样本集合用于网络 N 的进一步训练,以减少噪声标签的影响。
循环以上步骤,使得模型能在噪声标签的干扰下仍然获得鲁棒的跨模态哈希表示。
Experiments
Datasets
MIRFlickr-25K:包含 20,015 图文对,涉及 24 个类别。
IAPR TC-12:包含 20,000 图文对,涵盖 255 个多标签类别。
NUS-WIDE:经过筛选后有 200,421 图文对,涉及 21 个主要类别。
MS-COCO:含 122,218 图文对,涉及 80 个类别。
Metrics
mean Average Precision (mAP)
Result
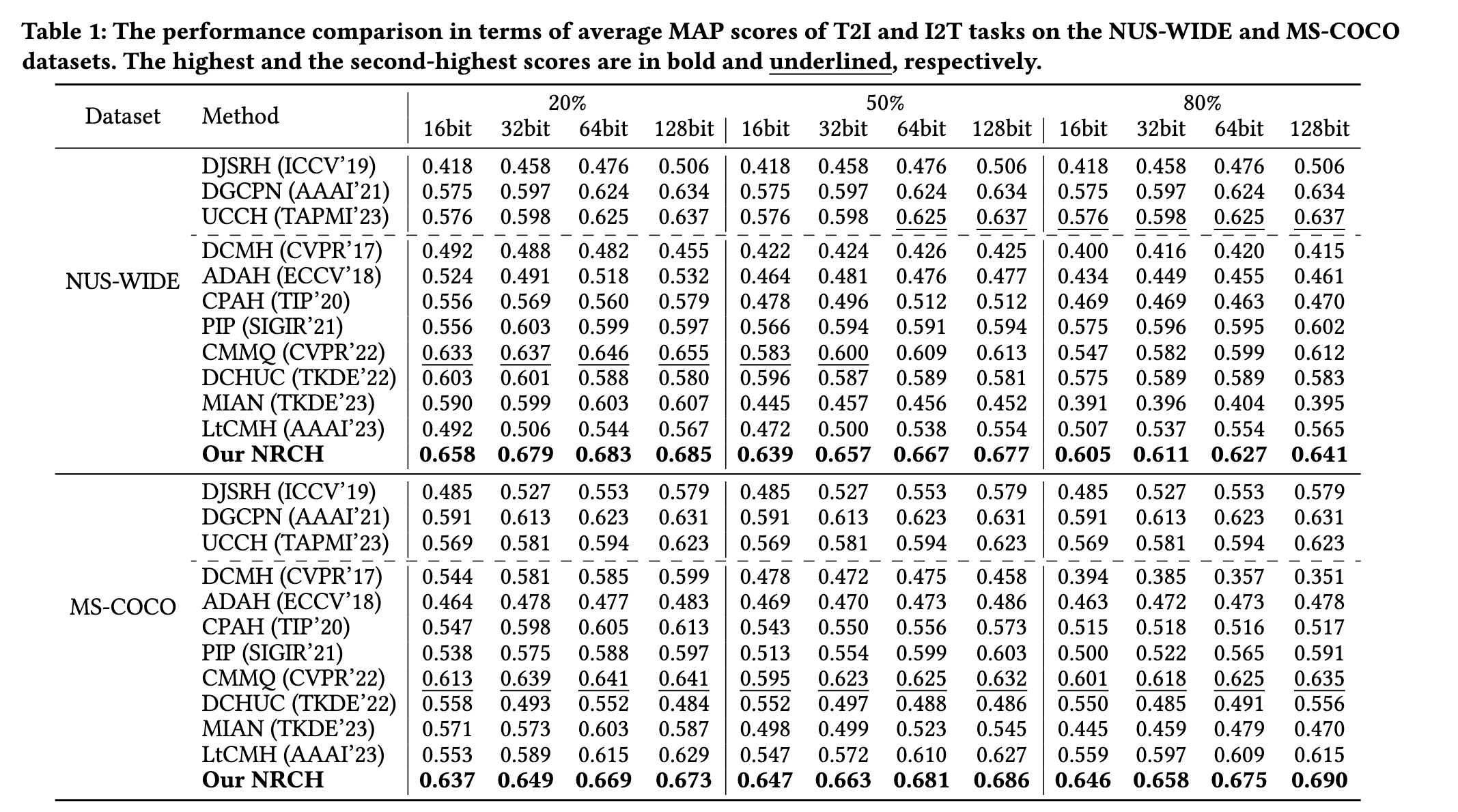
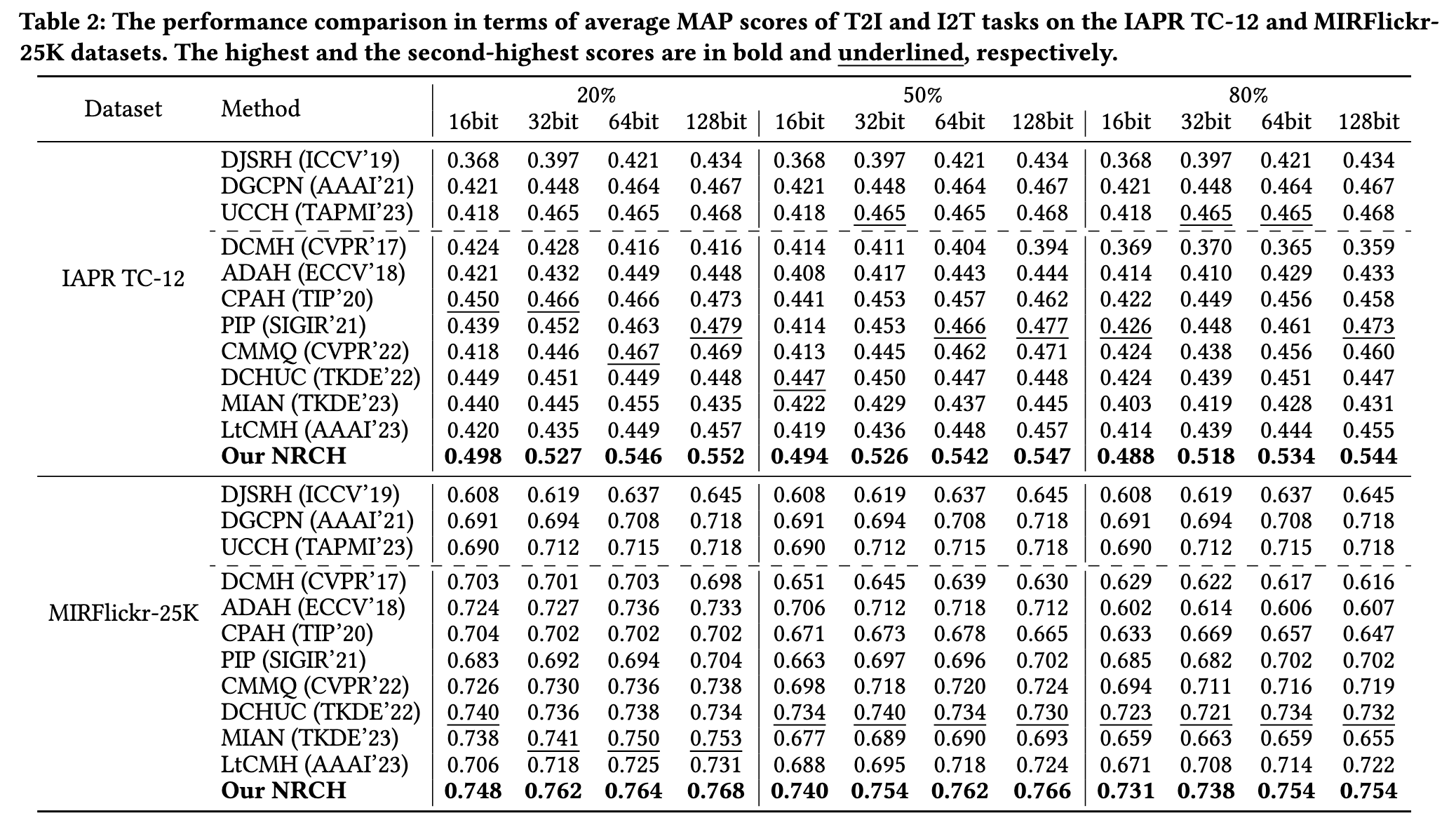
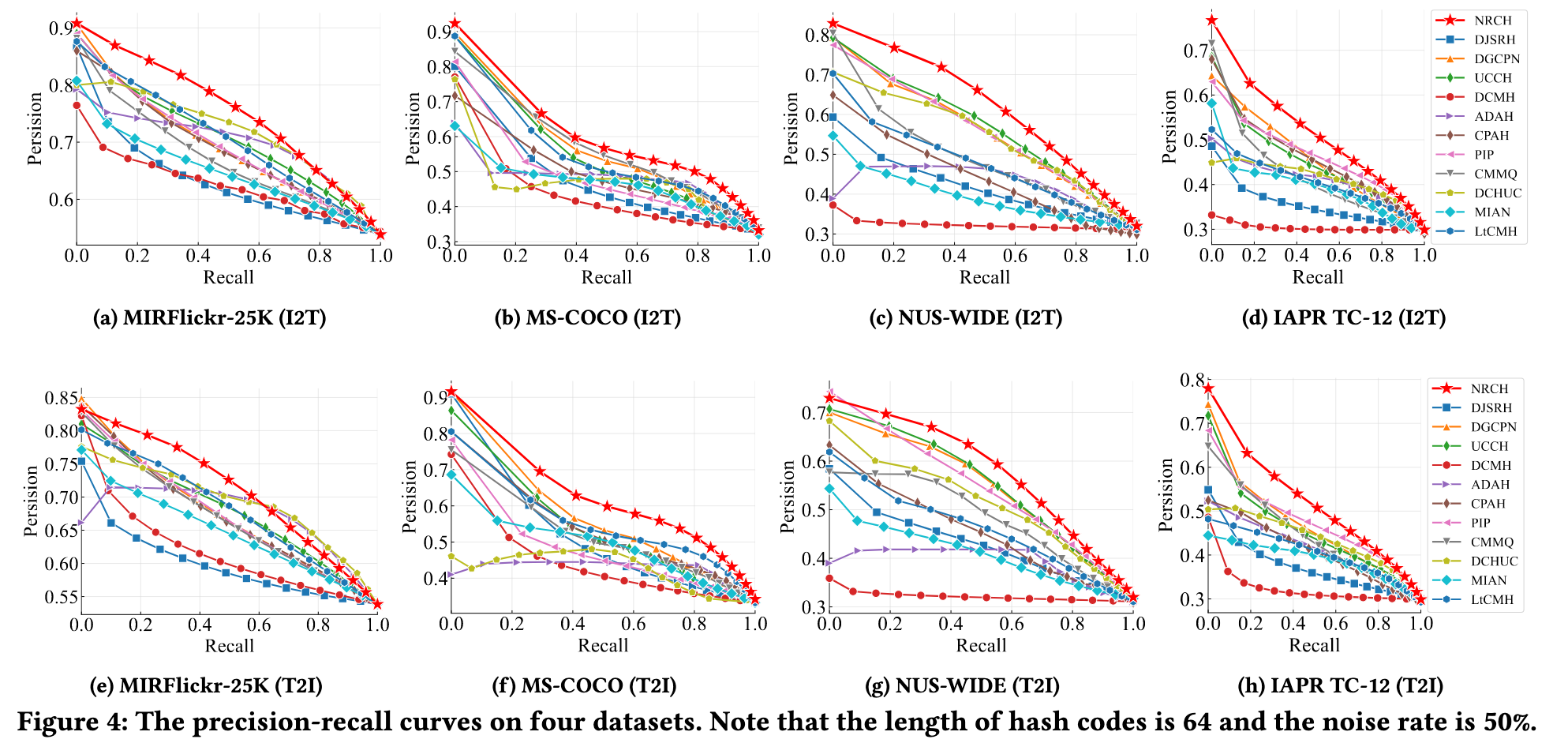
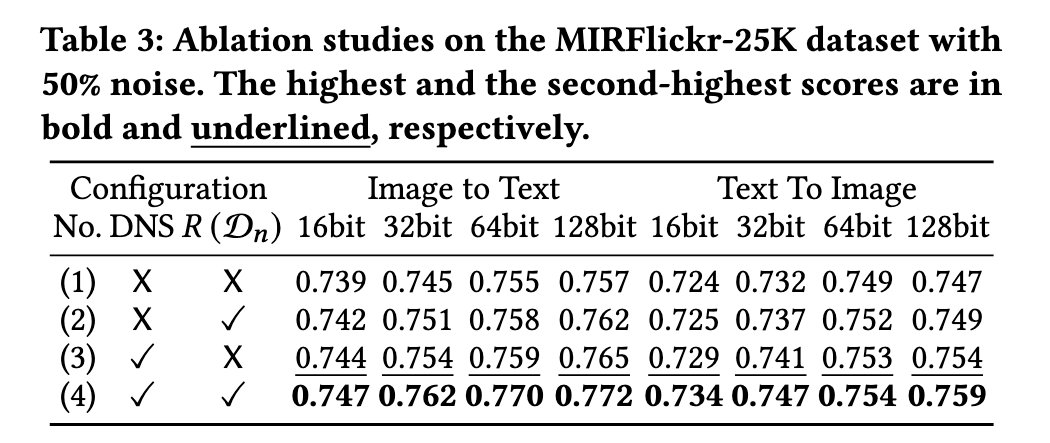
Ablation Study
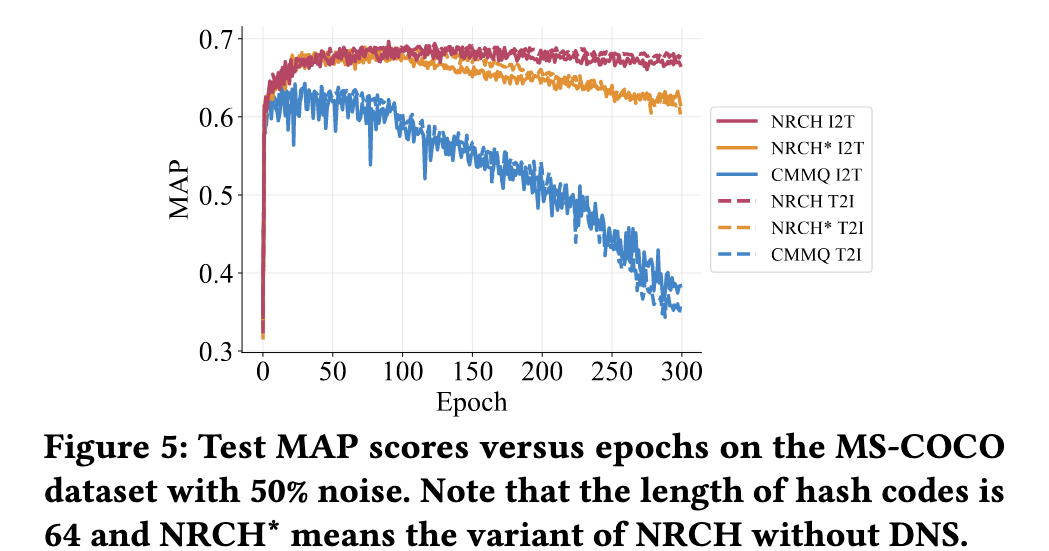
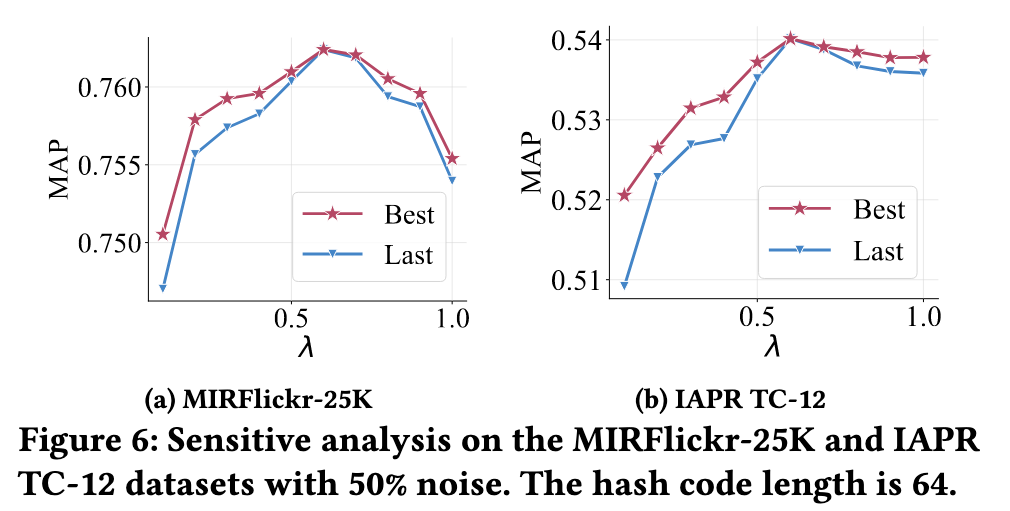
Conclusion
NRCH 框架结合了以下两个重要模块
鲁棒对比哈希(RCH):通过关注可靠的正样本对来对抗标签噪声,提高模态间的语义一致性。
动态噪声分离器(DNS):基于损失分布动态适应和分离噪声样本,避免错误样本的累积影响。
NRCH 的噪声处理方式不需要手动估计噪声水平,适应性更强,且可以扩展到其他类似任务中。
未来可以探索扩展到更多模态(如视频或语音)或复杂分布的数据集上,同时优化算法的计算效率以进一步提高实际应用价值。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享