
DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations
编辑论文链接:https://ieeexplore.ieee.org/document/10373051
代码链接:https://github.com/sunxm2357/DualCoOp
这篇文章发表在NeurIPS 2022上。
Background
多标签图像识别是一项具有挑战性的任务,涉及识别图像中存在的多个对象或属性。传统的图像识别方法主要集中在单标签分类上,即每张图像只与一个类别标签相关联。然而,现实世界中的图像通常包含多个对象或属性,这使得单标签分类在很多应用中(如图像检索、视频分析和推荐系统)变得不足。
多标签识别的挑战因获取完全标注的数据集的难度而加剧,每张图像都需要标注所有相关的类别。这导致了两种主要的场景:部分标签多标签识别,即每张图像只标注了部分标签;以及零样本多标签识别,即在测试时出现了新的类别,而这些类别在训练时没有任何示例。
Motivation
解决现有方法在处理有限标注的多标签识别任务时的局限性。传统方法要么需要大规模的完全标注数据集,要么不够灵活,无法同时处理部分标签和零样本场景。作者提出了一种统一的框架,能够通过利用大规模视觉-语言预训练中学习到的文本和视觉特征之间的强对齐,高效地适应有限标注的多标签识别任务。
证据引导的双上下文优化框架(DualCoOp++)
双可学习提示(Dual Learnable Prompts): 对于每个类别,DualCoOp 学习一对正负提示。这些提示为文本编码器提供上下文信息,使模型能够区分图像中某个类别的存在与否。
类别特定的区域特征聚合(Class-Specific Region Feature Aggregation):DualCoOp 修改了视觉编码器的注意力机制,以自适应地聚合每个类别的区域特征。
Method
Framework
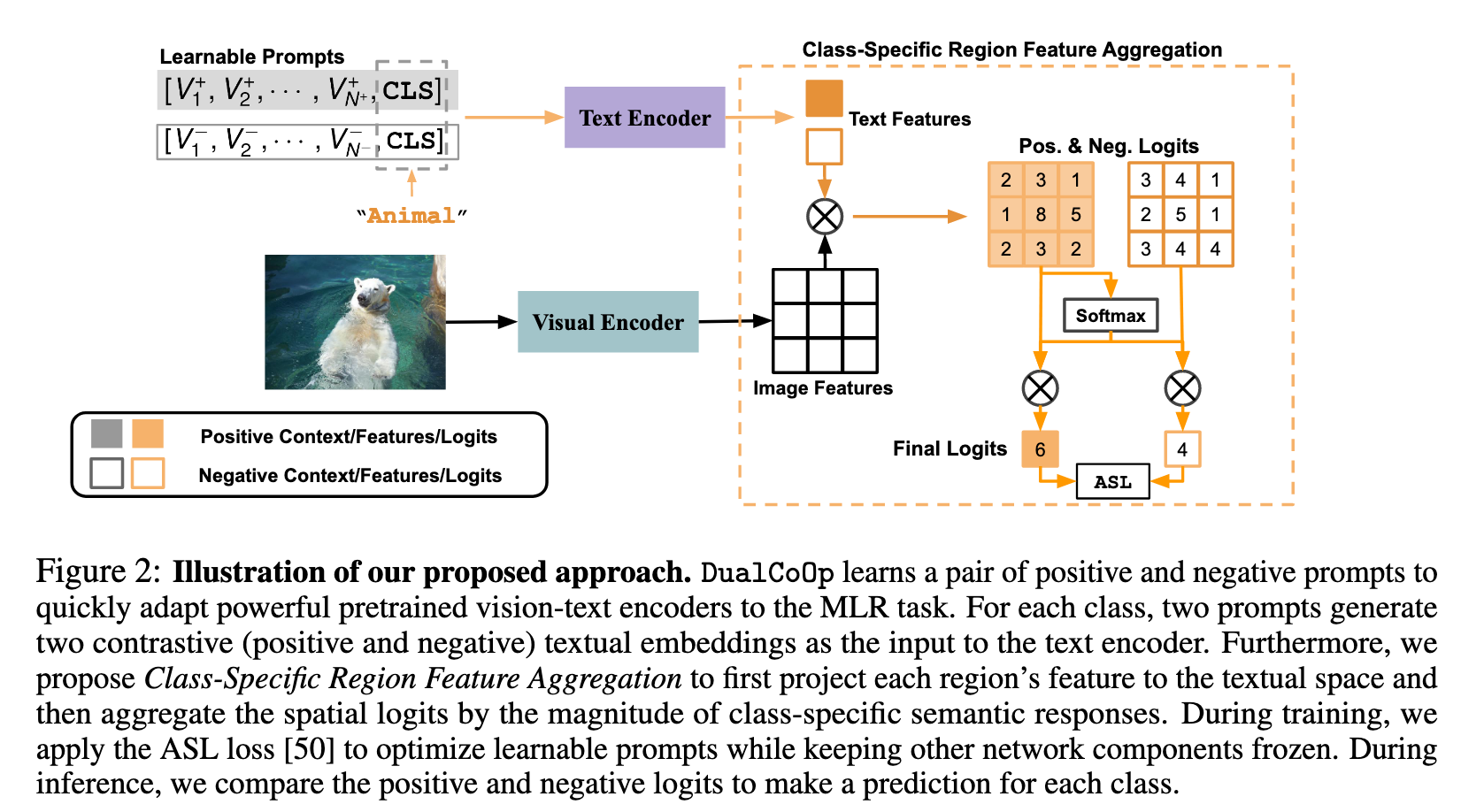
Problem Formulation & Approach Overview
设定M作为描述图像中对象或属性的一组类别,给定训练图像I,现有的m ∈ M个类别可能是positive,negative或unknown,对应的标签分别为ym=1,-1或0。
为了弥补图像标签的不足或缺失,了解类别名称的含义如何相互关联是很重要的, 通常是通过学习视觉和文本空间之间的对齐来完成相关类别之间的知识传递。
DualCoOp来利用大规模视觉语言预训练(CLIP)模型学习到的视觉和文本特征空间的强对齐,并且具有轻量级的可学习开销,可以快速适应具有有限语义注释的MLR任务。 DualCoOp以两个可学习的词向量序列的形式学习一对“提示”上下文,以提供给定类别名称m的positive和negative上下文环境。记为文本特征$(F_t^m)+$ 和$(F_t^m)-$,作为预训练的text encoder的输入。
为了更好地识别多个objects,设计了类特定区域特征聚合(Class-Specific Region Feature Aggregation)。首先用 $(F_t^m)+$/ $(F_t^m)-$计算每个投影视觉特征$F_v^i$在位置i的相似度得分,得到区域上的prediction logit。对于每个类执行所有空间逻辑的聚合,其中每个逻辑的权重由其相对大小决定。
Dual Learnable Prompts
双提示的可学习部分分别携带positive和negative的上下文环境,可以通过二值分类损失(binary classification loss)从数据端到端进行优化。 定义输入给文本编码器的一对提示为
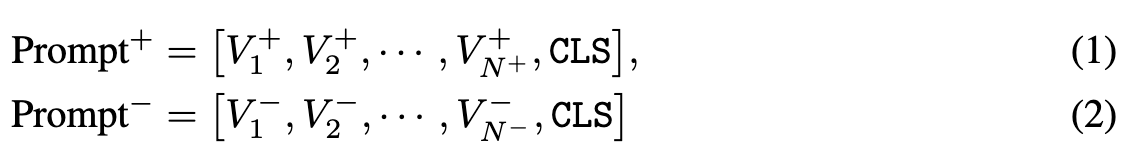
其中每个V是一个可学习的词嵌入向量,CLS是给定的类名,N+和N-是positive和negative 提示的work tokens的数量,在这篇文章中N+=N- 。
在partial labels的MLR任务中,每个类都有独自的一对positive和negative 提示。在zero-shot MLR任务中,所有类共享一对positive和negative 提示。
在此基础上通过公式(3)计算二进制分类输出p
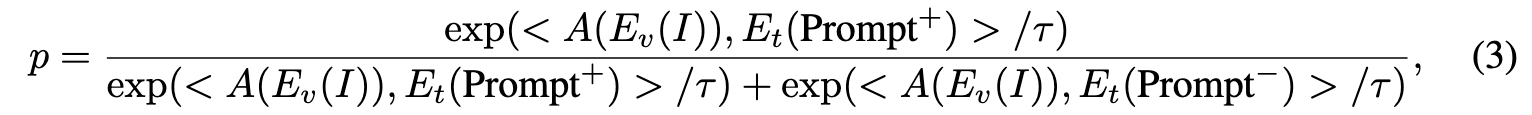
其中<·,·>表示余弦相似度,p为给定(图像,标签) 对作为正例的预测概率。Ev(·)和Et(·)是来自视觉 语言预训练的视觉和文本编码器。A(·)是我们新的 聚合函数,用于自适应地降低每一类视觉特征的空间维度。
Class-Specific Region Feature Aggregation
重新制定CLIP中视觉编码器的最后一个多头注意力池化层,采用多标签设置中自适应聚合区域特征的类特定池化。
CLIP中的原始注意力池层首先将视觉特征映射池化,然后将全局特征向量投影到文本空间中。
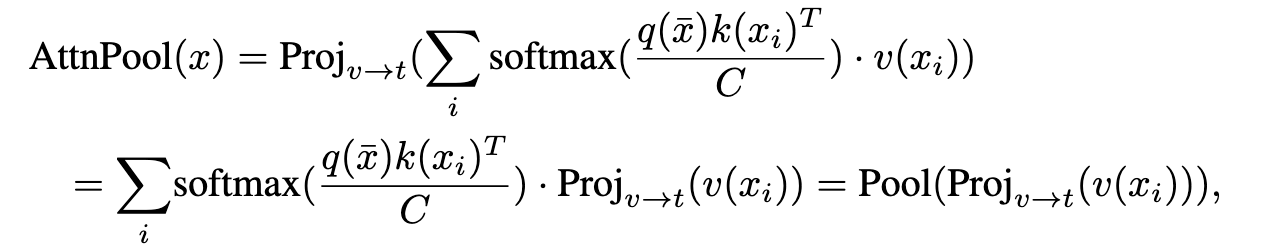
其中q、v、k为独立的线性嵌入层,x = Ev(I)为视觉编码器的输出特征映射。 通过去除池化操作,我们可以将每个区域i的视觉特征xi投影到文本空间中。
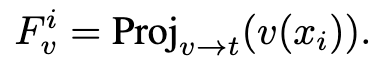
对于每个区域i和每个类m,通过公式(5)和(6)聚合分数。
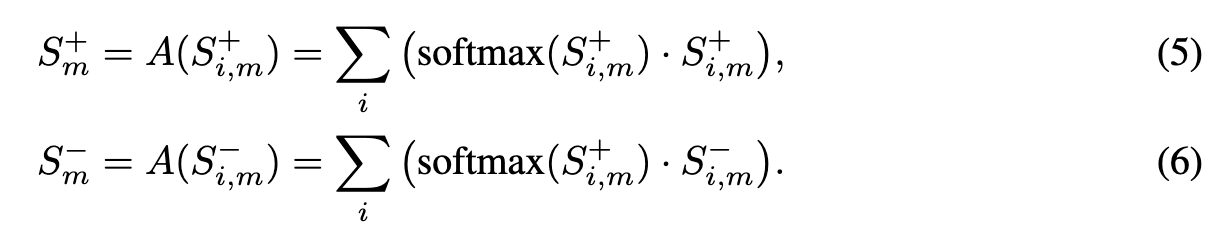
Loss Functions
应用非对称损失(ASL)来处理多标签识别优化中固有的正负不平衡。 计算正(image, label)对L+和负(image, label)对L−的损失

其中其中PC = max(p−c, 0)是通过边界c进行硬阈值偏移的负例的概率。 设置超参数γ−≥γ+,使ASL降权重和硬阈值易于负样本。通过冻结文本编码器反向传播ASL来更新这对可学习的提示。
Experiments
Datasets
MS-COCO、VOC2007、NUS-WIDE
PreProcess
Partial Labels Setting:随机地从完全标注的训练集中屏蔽掉标签,并按照标准惯例使用剩余的标签进行训练,在实验中将保留标签的比例从10%变化到90%。
Zero-shot Setting:MS-COCO上为48个可见类和17个未见类。NUS-WIDE上81个人工注释的类别为不可见类,从Flickr标签中获得的925个标签作为可见类。
Metrics
mean average precision (mAP)
learnable parameters(#P)
Result
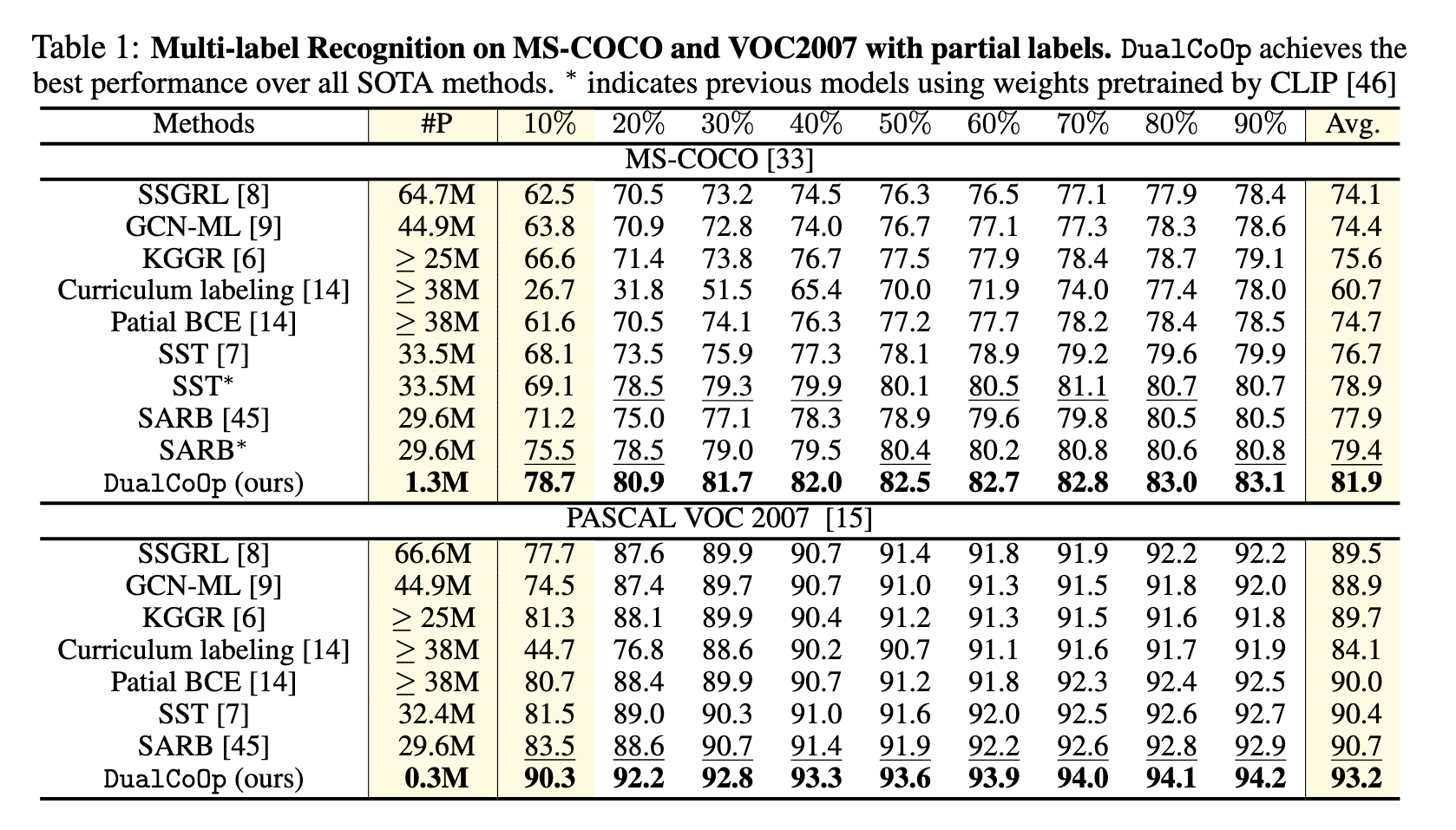
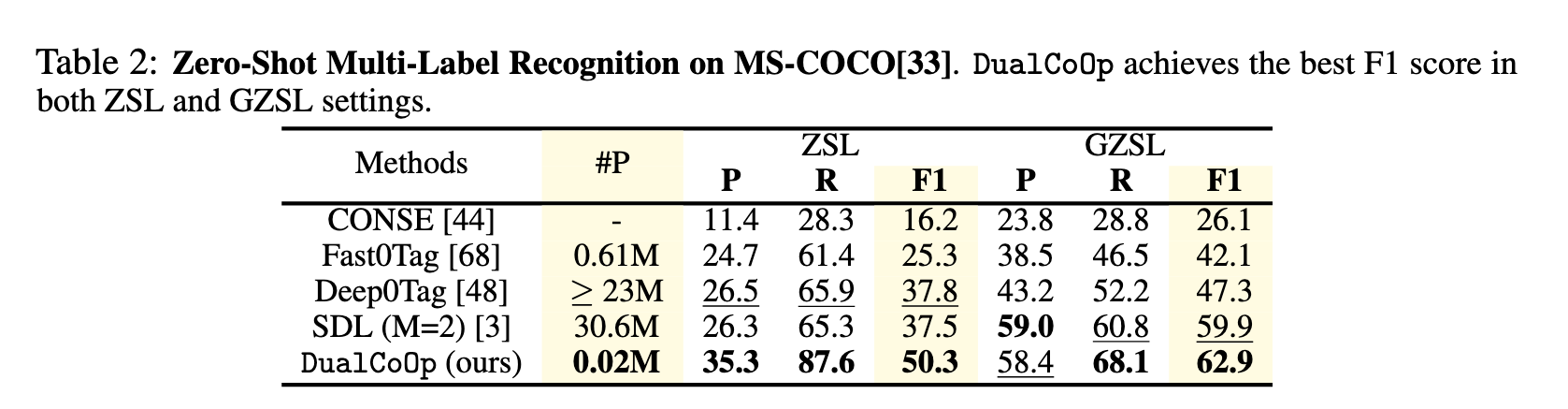
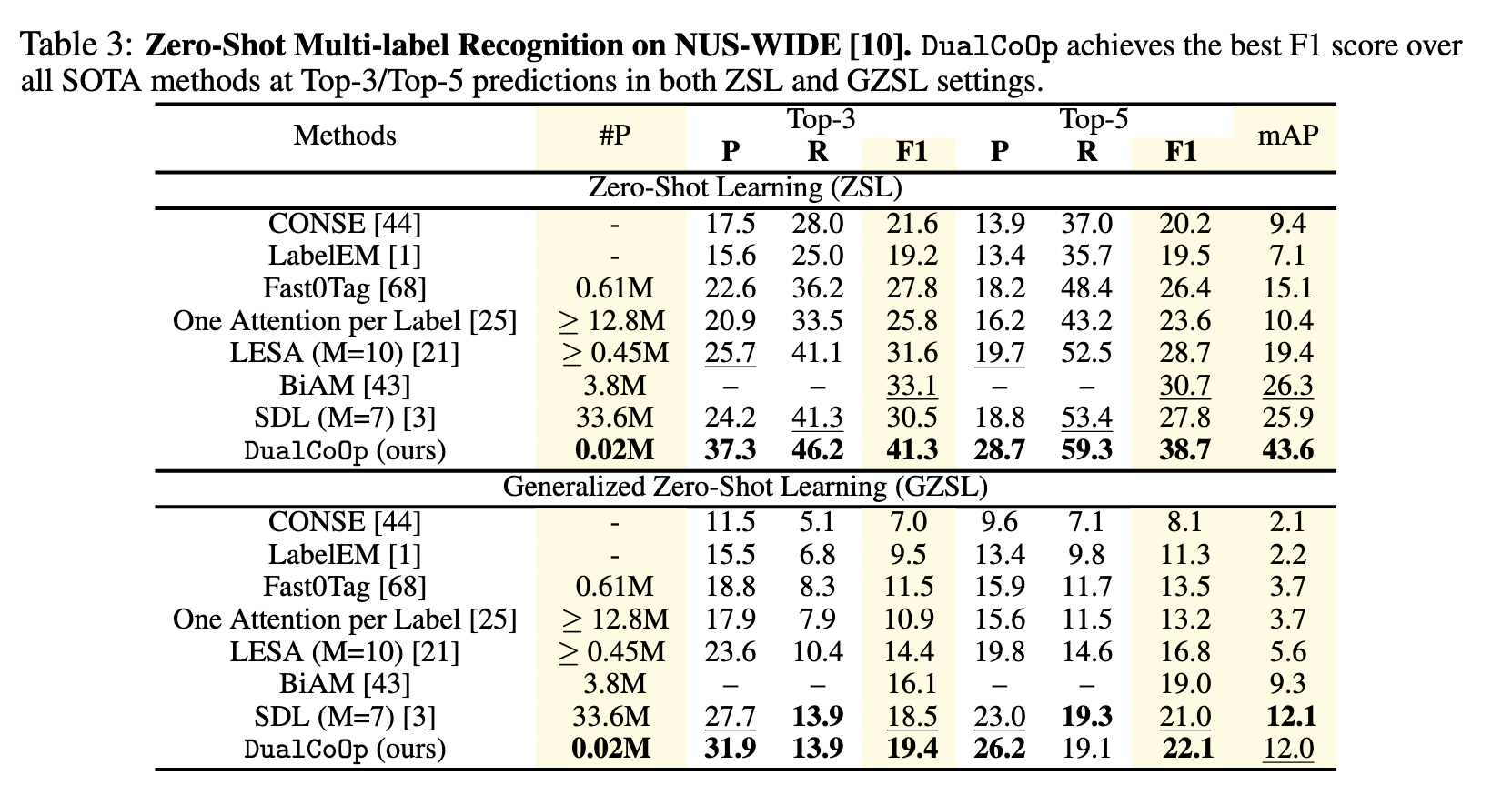
Ablation Study

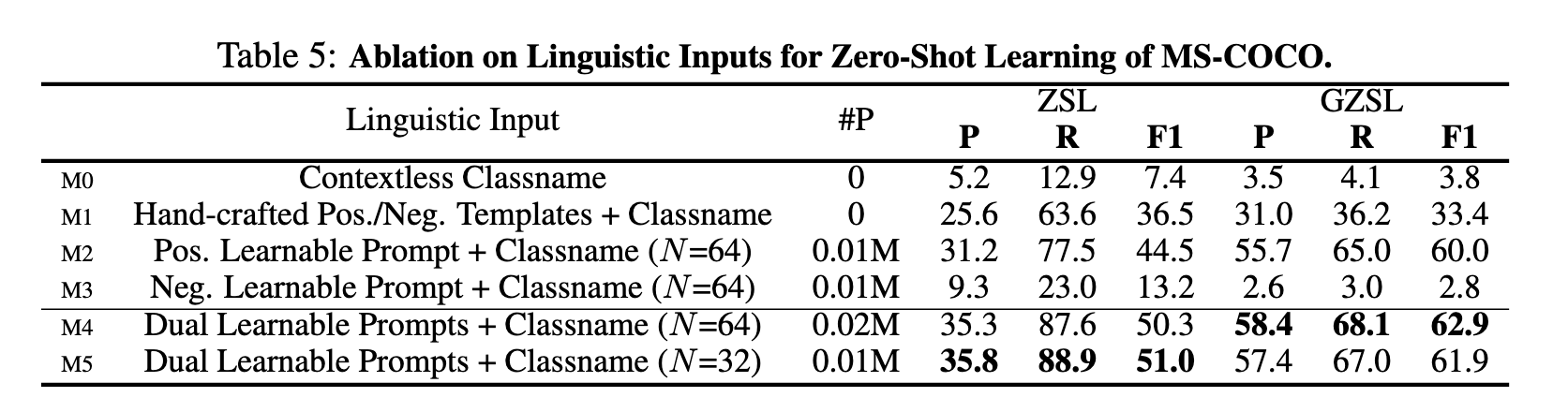
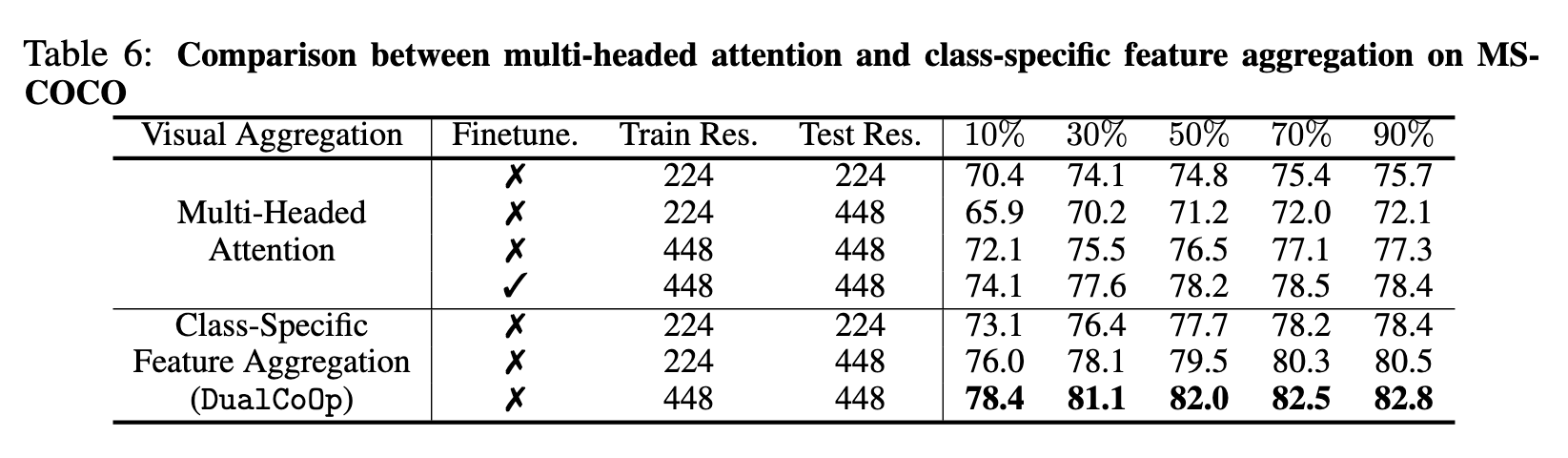
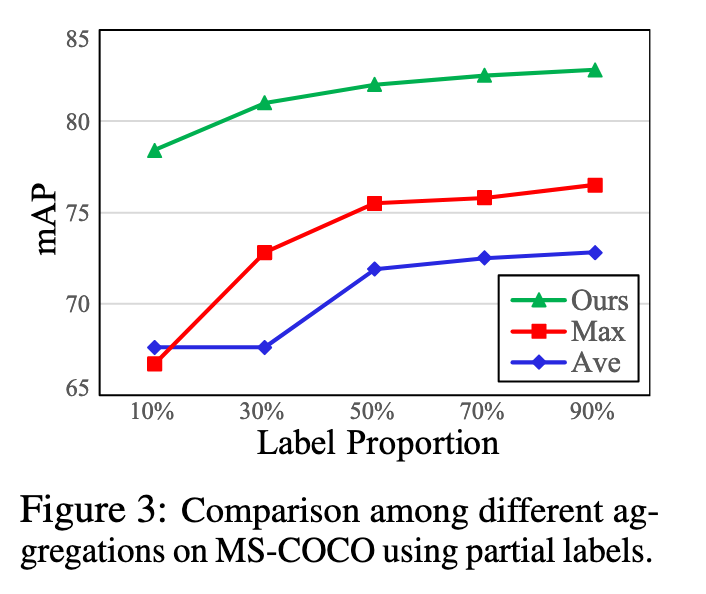
Conclusion
本文提出了一种新颖的框架 DualCoOp++,通过引入证据提示和 Winner-Take-All 模块,有效提高了在标注有限情况下的多标签图像识别性能。该方法不仅提高了识别准确性,还保持了高效的计算成本,适用于实际应用中的多标签识别任务。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享