
DualCoOp++: Fast and Effective Adaptation to Multi-Label Recognition With Limited Annotations
编辑论文链接:https://ieeexplore.ieee.org/document/10373051
这篇文章发表在TPAMI 2024上。
Background
多标签图像识别旨在识别图像中存在的多个语义标签,多标签识别 (MLR) 通常处理复杂场景和多样对象的图像,收集多标签注释存在两个问题:
对图像进行完整的语义标签集注释是费力的
特定类别的样本可能难以找到
尽管现有方法能够处理以上两个问题,但没有一种能够同时处理部分或缺失标签实际场景的解决方案。
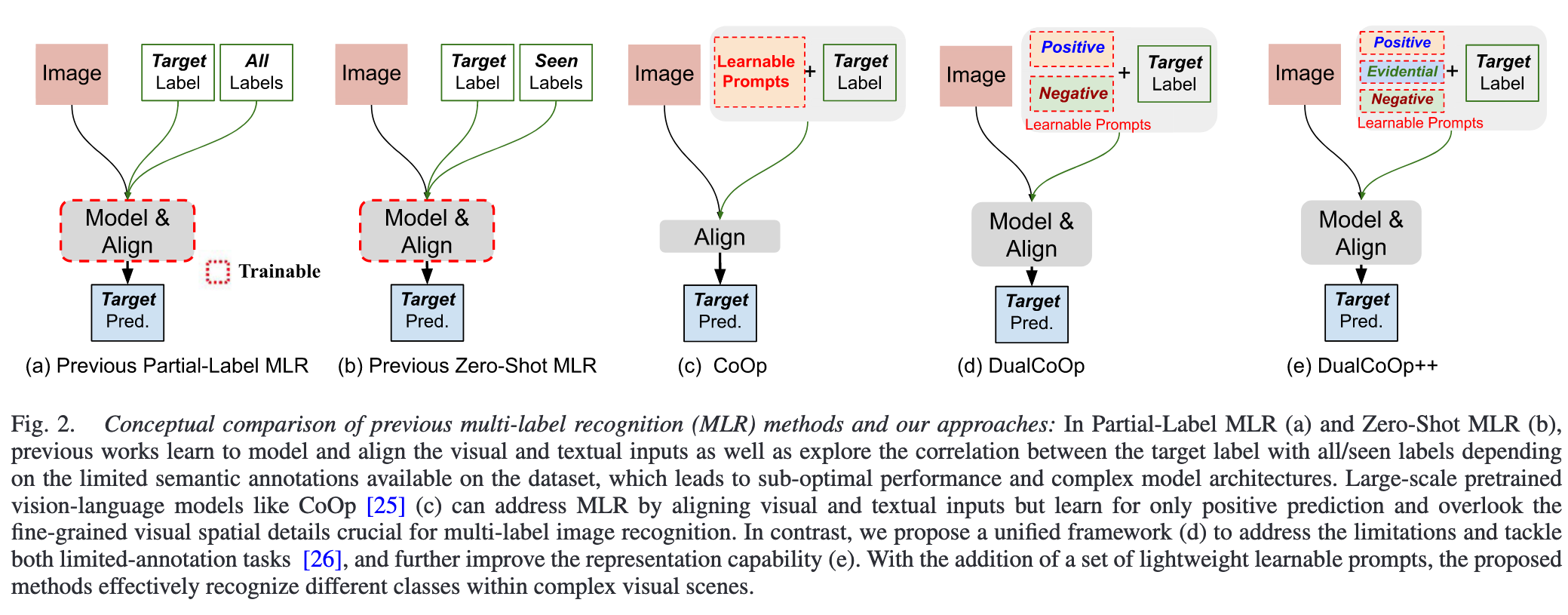
Motivation
现有方法尝试通过学习文本和视觉空间之间的对齐来弥补图像标签的不足,但由于高质量多标签标注的缺乏,可能导致准确性下降。因此,作者希望利用预训练的视觉-语言模型(CLIP)中强大的文本和视觉特征对齐能力,以此解决部分标注和零样本多标签识别问题。
基于证据引导的双重上下文优化框架(DualCoOp++)
Triple Learnable Prompts:将全局、正类别、负类别的上下文结合起来,为多标签分类任务中的类别特征建模提供了更强的表达能力。
Evidence-Guided Region Feature Aggregation:基于证据引导的区域特征聚合模块,改进从有限注释中学习到的上下文信息的空间聚合。
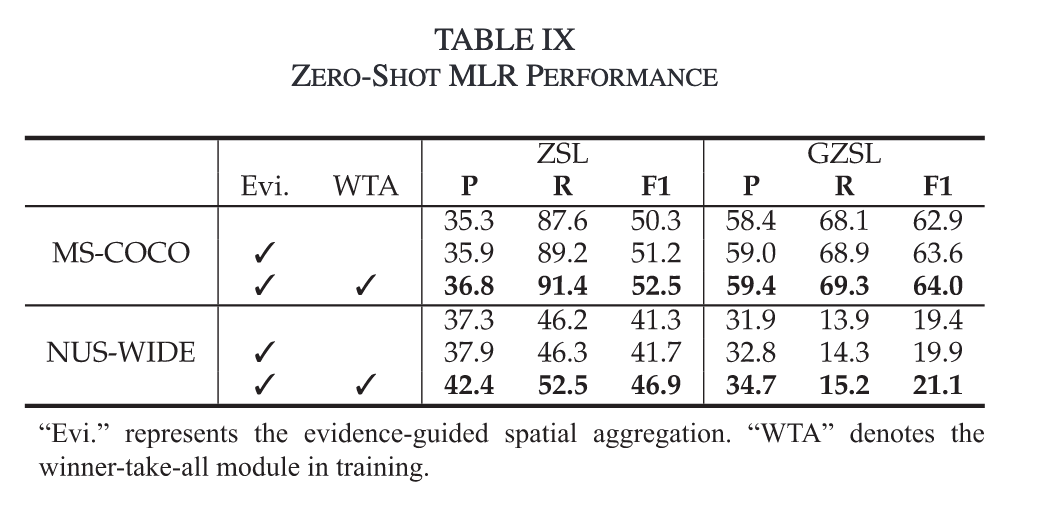
Winner-Take-All (WTA):规范每个空间位置,促进MLR中的类间互动,使其最多只能积极响应一个类别,从而进一步增强模型区分相似类别的能力。
Method
Framework
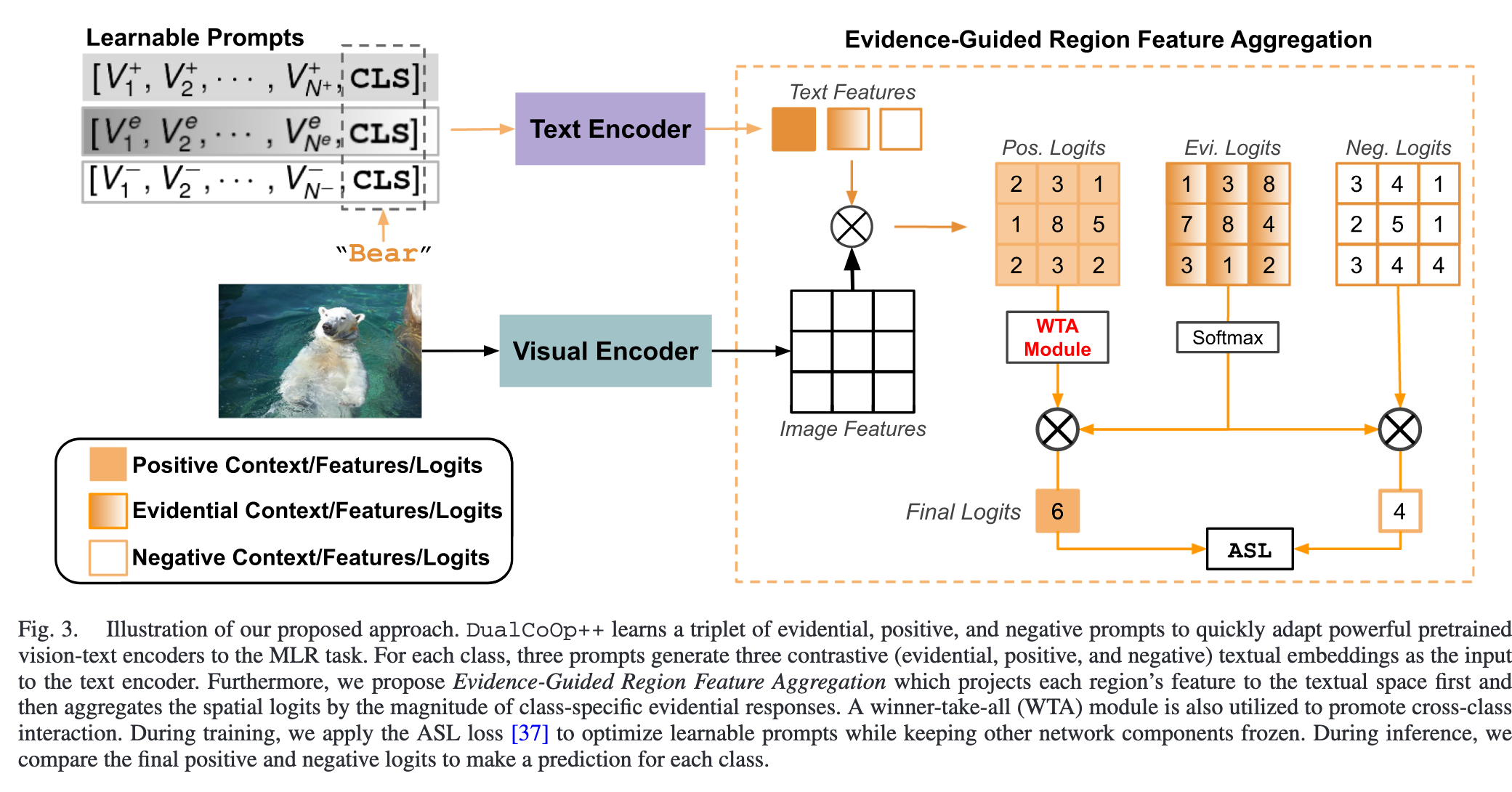
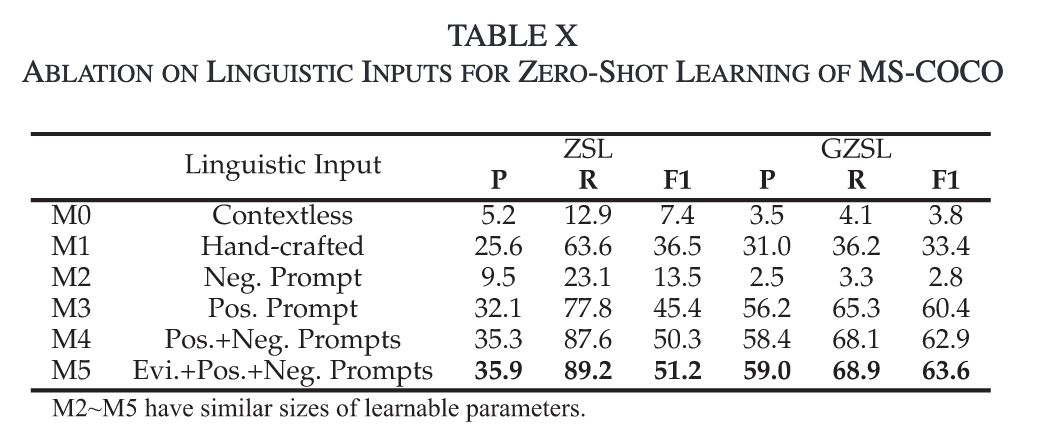
Triple Learnable Prompts
Evidential Context Prompts:
提供共享信息,增强特征表示的通用性。
“一种一般的动物背景场景”可以在包含多种动物的场景下作为全局提示。
Positive Context Prompts:
专注捕获特定类别的显著特性,增强正样本的识别。
对于“cat”类,正向上下文可能与“furry, small, domestic animal”相关。
Negative Context Prompts:
用于建模类别间的排他性,提高区分能力,降低误分类风险。
对于“cat”,负向上下文可能包括“bark, tall, wild animal”等与“dog”或“tiger”相关的信息,帮助模型区分相似类。
Triple Learnable Prompts三重提示中的可学习部分,分别携带evidential、positive和negative的上下文环境,并且可以通过二值分类损失从数据端到端进行优化。
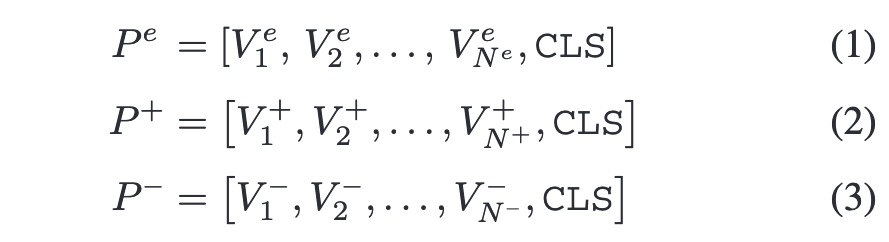
其中V为可学习的词嵌入向量,CLS为给定的类名。 随后通过比较正负上下文计算二元分类输出p
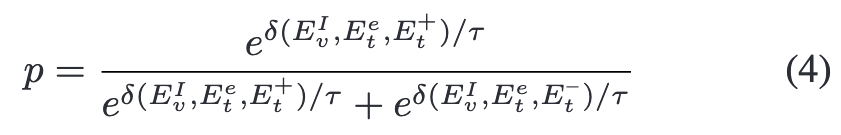
其中p是给定(image,label)对作为正例的预测概率, Ev表示图像特征,Et表示prompts,δ(·,·,·)是后面提出的证据引导的空间聚集函数。
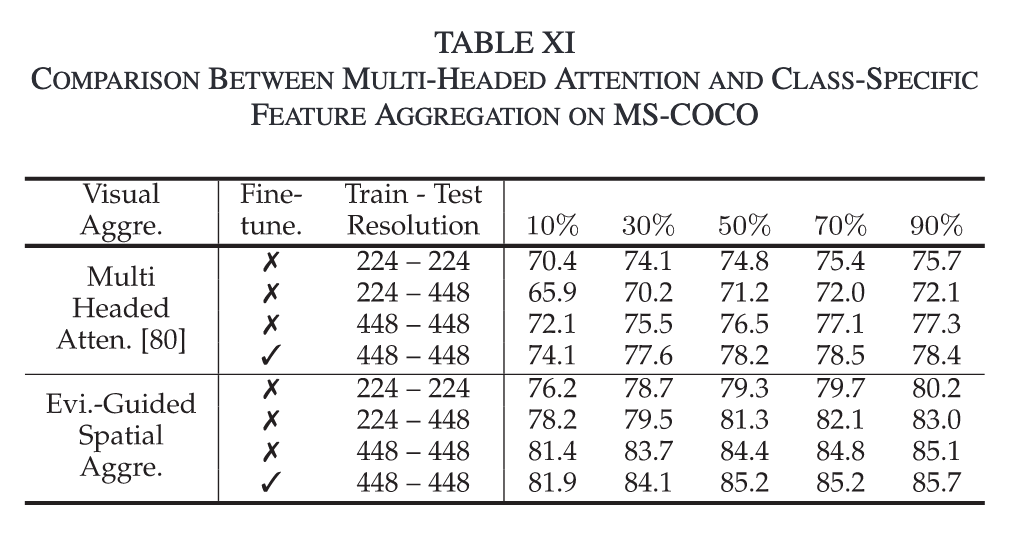
Evidence-Guided Region Feature Aggregation
池化为所有类生成单个图像级特征向量会带来次优的性能, 因为空间信息减少了,不同的对象混合在一起。 CLIP 中的原始注意池化层首先对视觉特征图进行池化,然后将全局特征向量投影到文本空间。
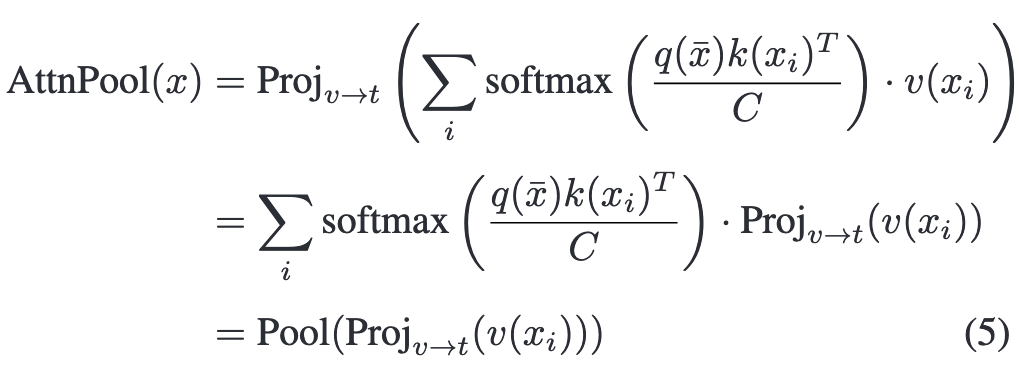
通过移除池化操作,每个区域i的视觉特征$F_v^i$能够投影到文本空间。
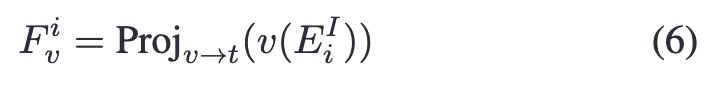
对于每一个区域和其对应类别,计算Fvi与类别的证据、正、负上下文之间的cosine similarity计算logits
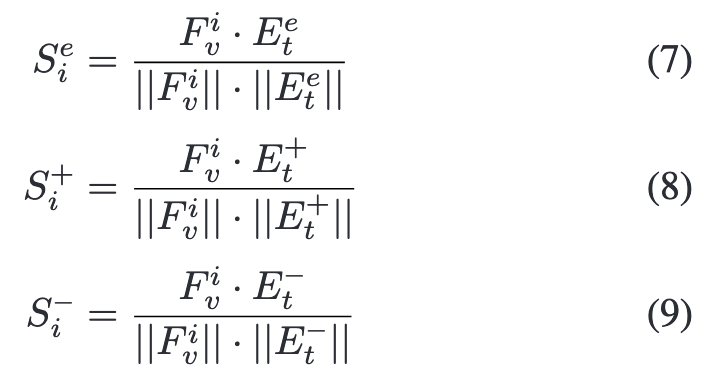
为了对整个图像进行单一预测,根据Sie的大小将logit映射S+i和S-i聚合为S+和S-
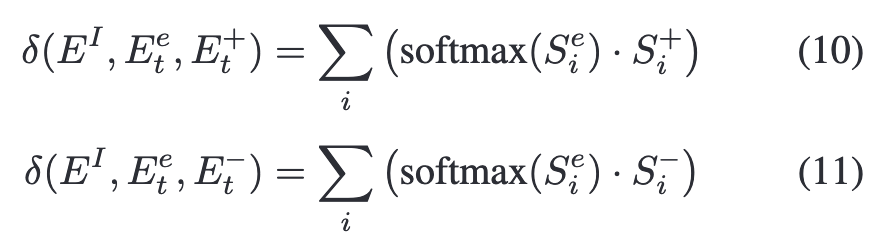
对某一类别的预测概率通过公式(4)计算。
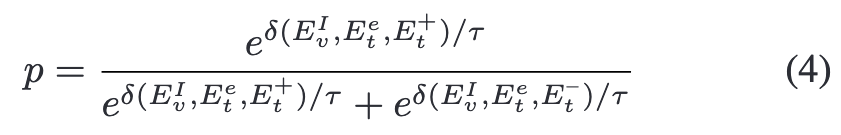
Winner-Take-All Regularization
WinnerTake-All (WTA)模块规范每个空间区域最多只对一个类做出积极响应,从而解决相同的视觉特征可能对多个相似的类做出积极响应导致的假阳性预测问题。 在所有标签上计算正则化权值wi∈$R^M$
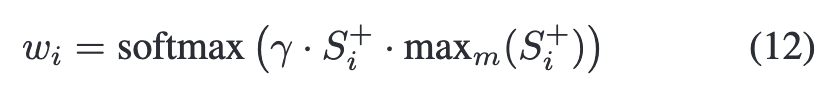
其中$max_m(S^+_i)$表示区域i在M个类中的最大logit分数,γ是一个超参数
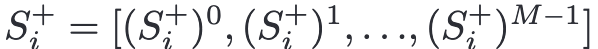
随后逐元素更新positive logits
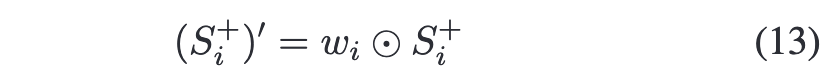
与总是标记最大元素的Gumbel softmax相反,WTA仅在多个logit具有大值时突出显示较大的元素,这确保了图像区域可以对给定的类没有响应或仅响应一个。

Loss Functions
应用非对称损失(ASL)来处理多标签识别优化中固有的正负不平衡。 计算正(image, label)对L+和负(image, label)对L−的损失
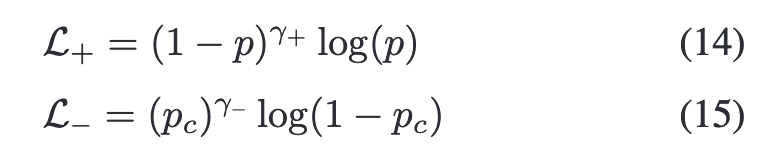
其中PC = max(p−c, 0)是通过边界c进行硬阈值转移的负例的概率。设置超参数γ−≥γ+,使ASL降权重和硬阈值易于负样本。
Experiments
Datasets
MS-COCO、VOC2007、 BigEarth、NUS-WIDE
Setting
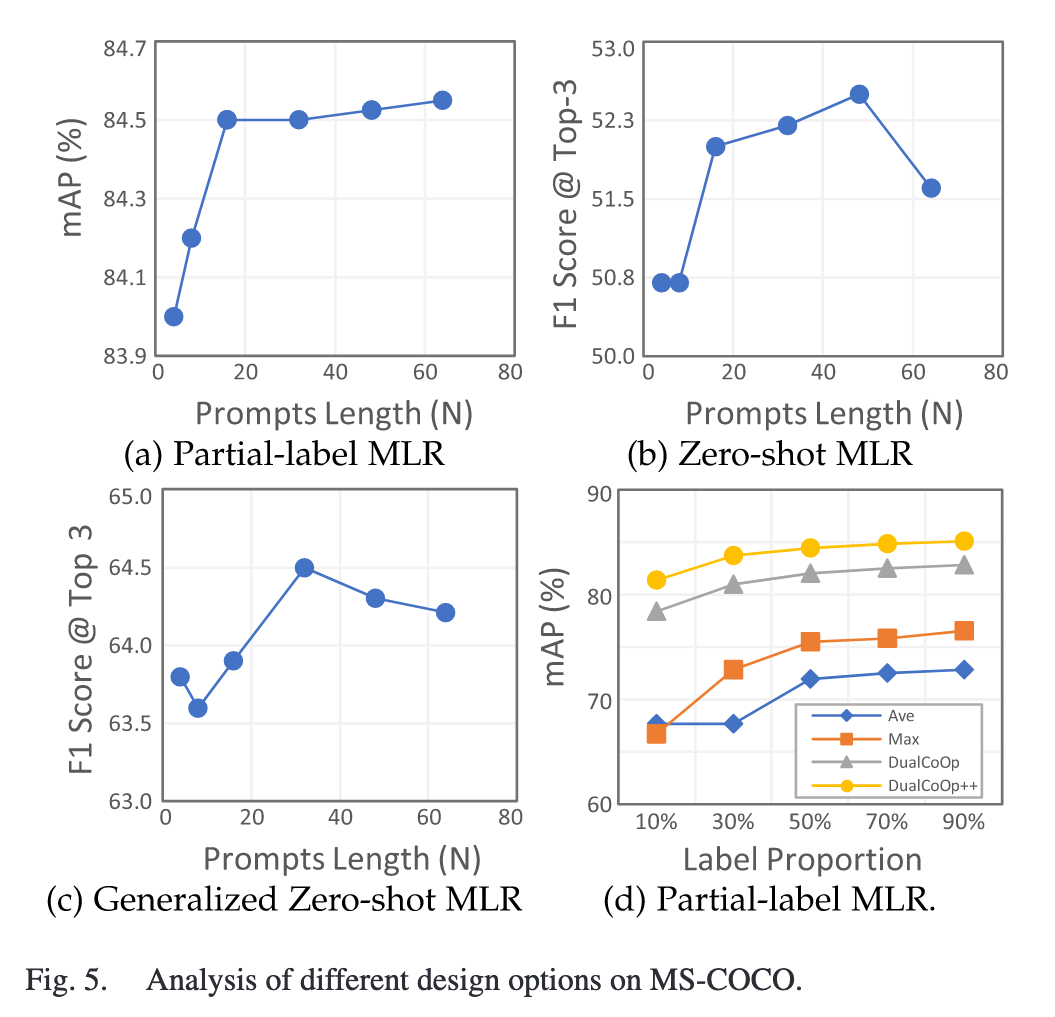
Partial Labels Setting:随机地从完全标注的训练集中屏蔽掉标签,并按照标准惯例使用剩余的标签进行训练,在实验中将保留标签的比例从10%变化到90%。
Zero-shot Setting:MS-COCO上为48个可见类和17个未见类。NUS-WIDE上81个人工注释的类别为不可见类,从Flickr标签中获得的925个标签作为可见类。
Metrics
mean average precision (mAP)
learnable parameters(#P)
Result
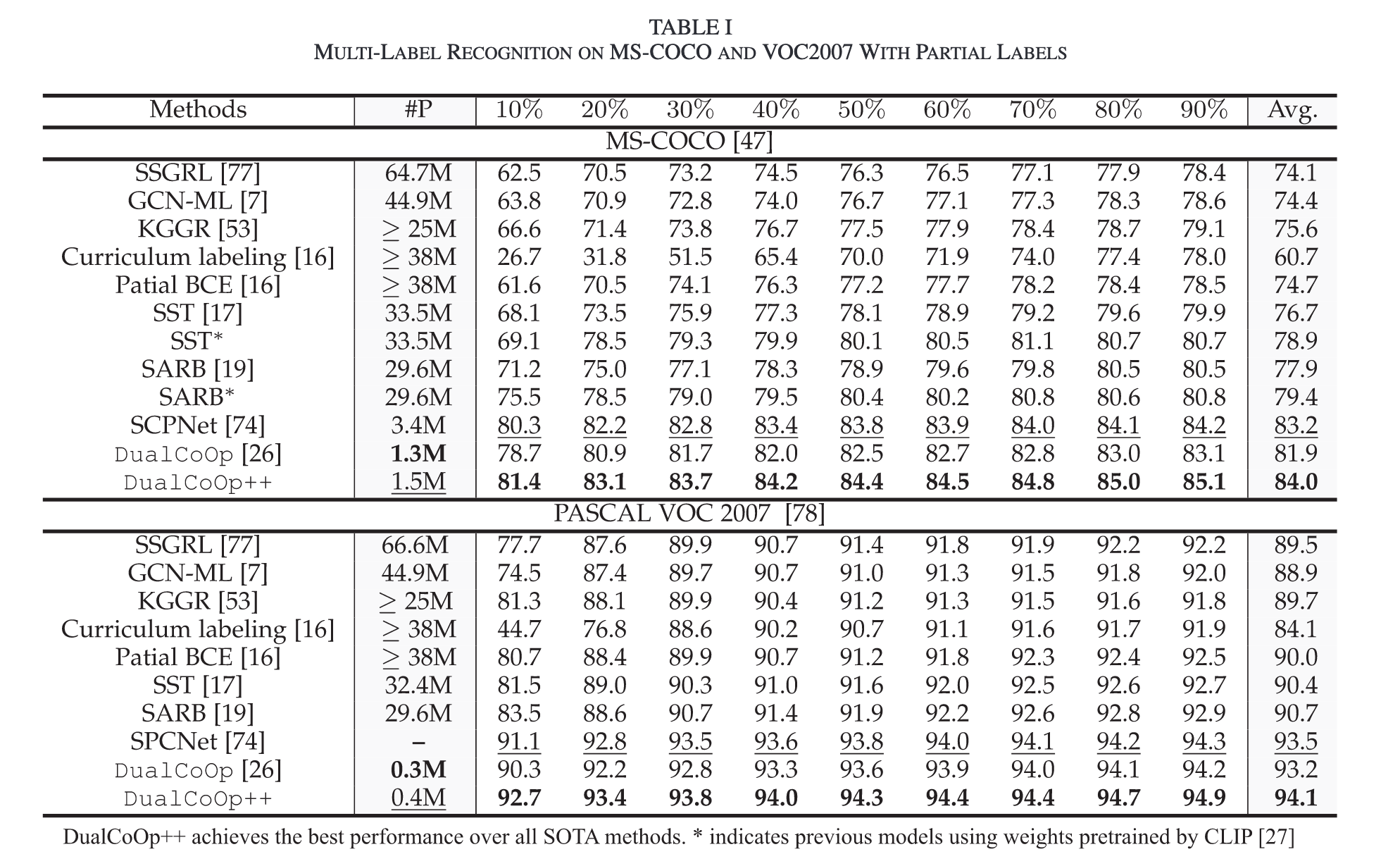
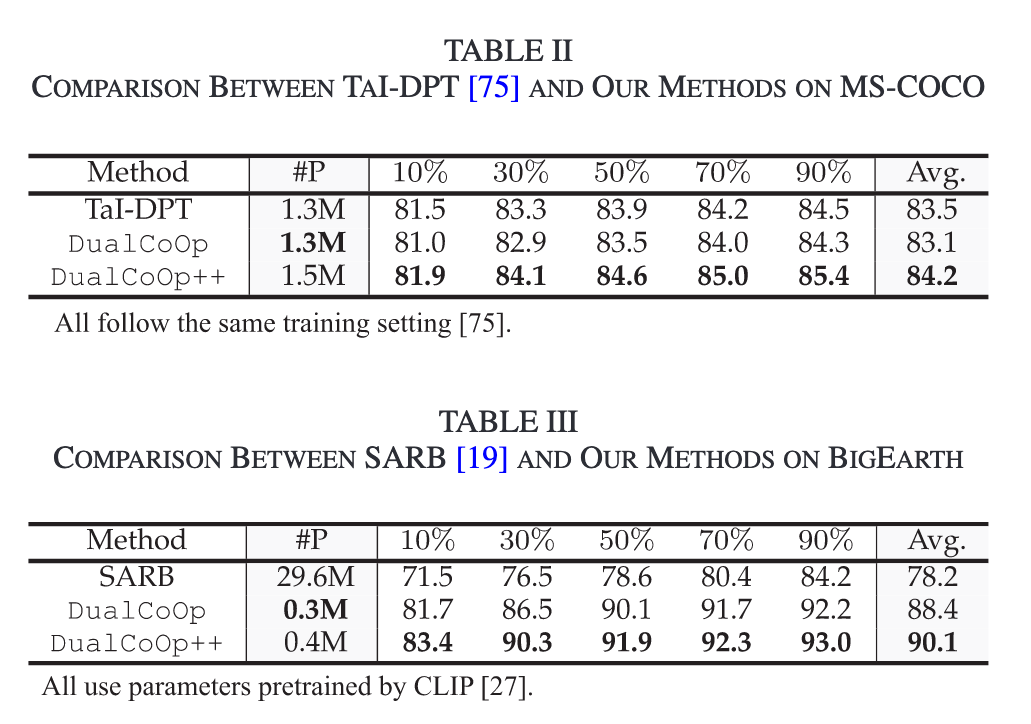
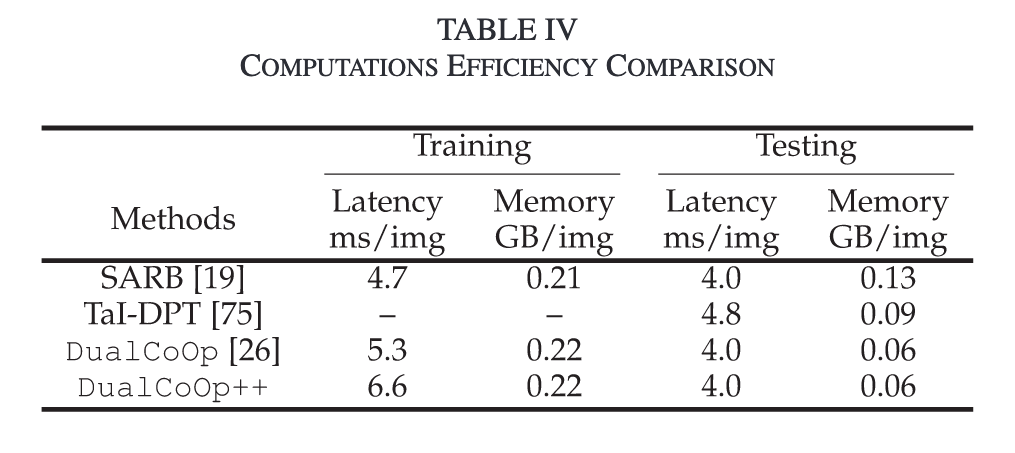
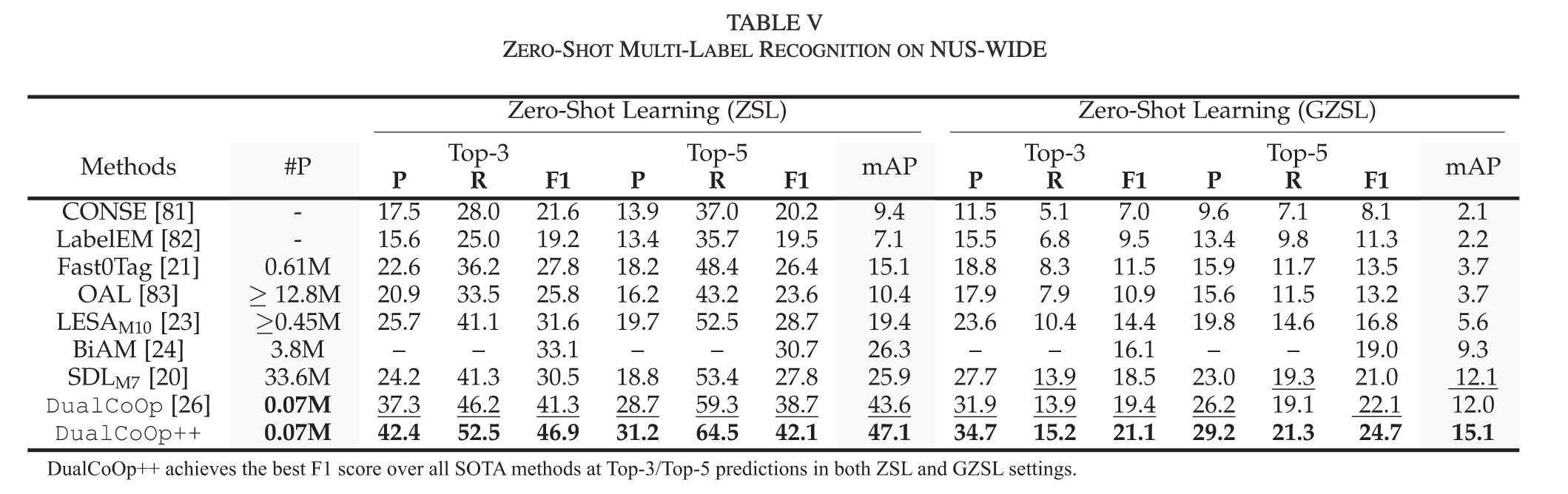
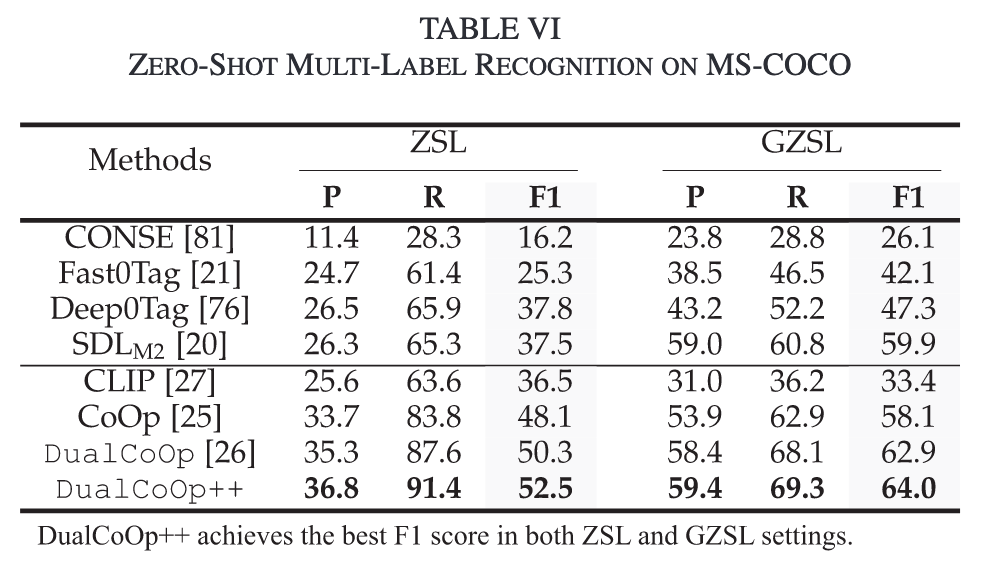
Ablation Study
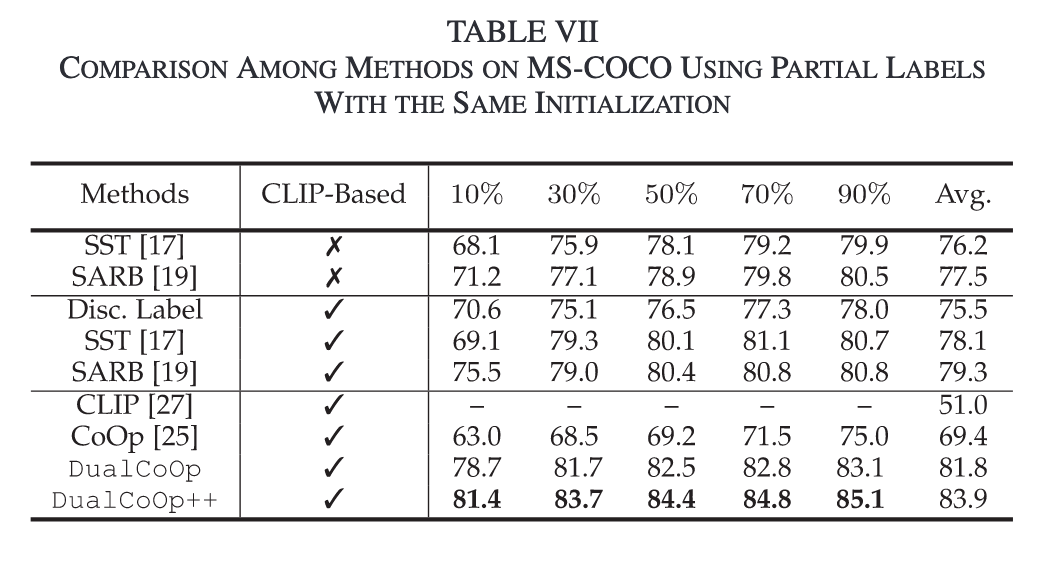
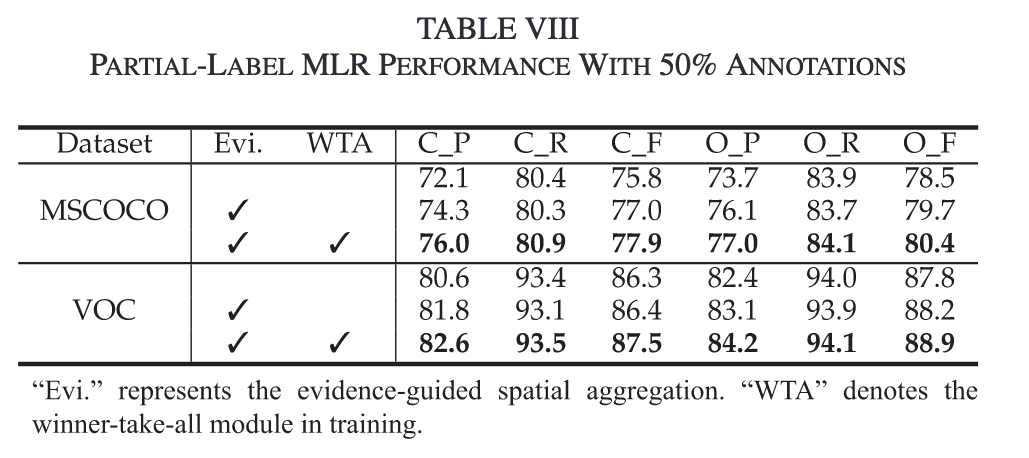
Visualization

Conclusion
通过引入负面提示,模型解开了优化过程的纠缠,从而明确地进一步优化真类的假阴性预测和假类的假阳性预测。这种方法引入了独立和互补的上下文,从而增强了模型的区分和泛化能力。此外,这种优化策略通过比较正对数和负对数来促进分类,从而消除了在纯正模型中通常需要的手动阈值选择的需要。
DualCoOp++提供了一种统一的方法,能够在有限标注的情况下快速适应多标签识别任务。通过引入证据引导的上下文编码和“胜者为王”模块,该方法在减少计算开销的同时,提高了模型在部分标注和零样本多标签识别任务中的性能。
- 0
- 0
-
赞助
 AliPay
AliPay
 WeChat Pay
WeChat Pay
-
分享